Begynnelsen av C++-språket skjedde tilbake i 1983, like etter når 'Bjare Stroustrup' jobbet med klasser på C-språket inkludert med noen tilleggsfunksjoner som operatøroverbelastning. Filtypene som brukes er '.c' og '.cpp'. C++ er utvidbar og ikke avhengig av plattformen og inkluderer STL som er forkortelsen for Standard Template Library. Så i utgangspunktet er det kjente C++-språket faktisk kjent som et kompilert språk som har kildefilen kompilert sammen for å danne objektfiler, som når de kombineres med en linker produserer et kjørbart program.
På den annen side, hvis vi snakker om nivået, er det på middels nivå som tolker fordelen med lavnivåprogrammering som drivere eller kjerner og også apper på høyere nivå som spill, GUI eller skrivebordsapper. Men syntaksen er nesten den samme for både C og C++.
Komponenter av C++ Language:
#include
Denne kommandoen er en overskriftsfil som består av 'cout'-kommandoen. Det kan være mer enn én overskriftsfil avhengig av brukerens behov og preferanser.
int main()
Denne setningen er masterprogramfunksjonen som er en forutsetning for hvert C++-program, noe som betyr at uten denne setningen kan man ikke kjøre noe C++-program. Her er 'int' returvariabeldatatypen som forteller om typen data funksjonen returnerer.
Erklæring:
Variabler deklareres og navn tildeles dem.
Problemstilling:
Dette er viktig i et program og kan være en «mens»-løkke, «for»-løkke eller en hvilken som helst annen betingelse som brukes.
Operatører:
Operatører brukes i C++-programmer, og noen er avgjørende fordi de brukes på forholdene. Noen få viktige operatorer er &&, ||, !, &, !=, |, &=, |=, ^, ^=.
C++ inngangsutgang:
Nå skal vi diskutere inngangs- og utdatamulighetene i C++. Alle standardbibliotekene som brukes i C++ gir maksimale inngangs- og utdatafunksjoner som utføres i form av en sekvens av byte eller er normalt relatert til strømmene.
Inndatastrøm:
I tilfelle bytene streames fra enheten til hovedminnet, er det inngangsstrømmen.
Utdatastrøm:
Hvis bytene streames i motsatt retning, er det utgangsstrømmen.
En header-fil brukes for å lette inndata og utdata i C++. Den er skrevet som
Eksempel:
Vi vil vise en strengmelding ved hjelp av en tegntypestreng.
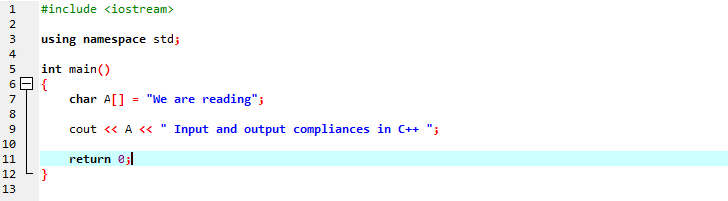
I den første linjen inkluderer vi 'iostream' som har nesten alle de essensielle bibliotekene som vi kan trenge for kjøring av et C++-program. I neste linje erklærer vi et navneområde som gir omfanget for identifikatorene. Etter å ha kalt hovedfunksjonen, initialiserer vi en tegntype-array som lagrer strengmeldingen og 'cout' viser den ved å sette sammen. Vi bruker 'cout' for å vise teksten på skjermen. Vi tok også en variabel 'A' som har en karakterdatatype-array for å lagre en streng med tegn, og så la vi til både array-meldingen langs den statiske meldingen ved å bruke 'cout'-kommandoen.
Utgangen som genereres er vist nedenfor:

Eksempel:
I dette tilfellet vil vi representere alderen til brukeren i en enkel strengmelding.
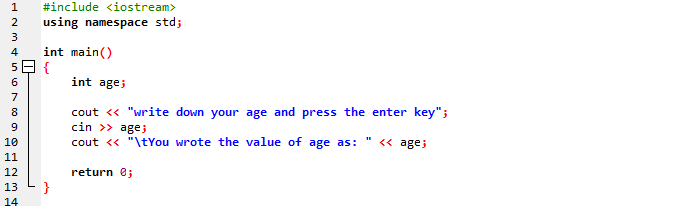
I det første trinnet inkluderer vi biblioteket. Etter det bruker vi et navneområde som vil gi omfanget for identifikatorene. I neste trinn kaller vi hoved() funksjon. Deretter initialiserer vi alder som en 'int'-variabel. Vi bruker 'cin'-kommandoen for input og 'cout'-kommandoen for utdata av den enkle strengmeldingen. 'cin' legger inn verdien av alder fra brukeren og 'cout' viser det i den andre statiske meldingen.

Denne meldingen vises på skjermen etter å ha kjørt programmet slik at brukeren kan få alder og deretter trykke ENTER.

Eksempel:
Her viser vi hvordan du skriver ut en streng ved å bruke 'cout'.

For å skrive ut en streng inkluderer vi først et bibliotek og deretter navneområdet for identifikatorer. De hoved() funksjonen kalles. Videre skriver vi ut en strengutgang ved å bruke 'cout'-kommandoen med innsettingsoperatøren som deretter viser den statiske meldingen på skjermen.

C++ datatyper:
Datatyper i C++ er et veldig viktig og allment kjent emne fordi det er grunnlaget for C++ programmeringsspråk. På samme måte må enhver variabel som brukes være av en spesifisert eller identifisert datatype.
Vi vet at for alle variablene bruker vi datatype mens vi gjennomgår deklarering for å begrense datatypen som måtte gjenopprettes. Eller vi kan si at datatypene alltid forteller en variabel hva slags data den lagrer selv. Hver gang vi definerer en variabel, tildeler kompilatoren minnet basert på den deklarerte datatypen ettersom hver datatype har en annen minnelagringskapasitet.
C++-språket hjelper mangfoldet av datatyper slik at programmereren kan velge den aktuelle datatypen han måtte trenge.
C++ forenkler bruken av datatypene angitt nedenfor:
- Brukerdefinerte datatyper
- Avledede datatyper
- Innebygde datatyper
Følgende linjer er for eksempel gitt for å illustrere viktigheten av datatypene ved å initialisere noen få vanlige datatyper:
int en = to ; // heltallsverdiflyte F_N = 3,66 ; // flyttallverdi
dobbelt D_N = 8,87 ; // dobbel flyttallverdi
røye Alfa = 'p' ; // tegn
bool b = ekte ; // Boolsk
Noen vanlige datatyper: hvilken størrelse de spesifiserer og hvilken type informasjon variablene deres vil lagre, vises nedenfor:
- Tegn: Med størrelsen på én byte vil den lagre et enkelt tegn, bokstav, tall eller ASCII-verdier.
- Boolsk: Med størrelsen 1 byte vil den lagre og returnere verdier som enten sant eller usant.
- Int: Med størrelsen 2 eller 4 byte vil den lagre hele tall som er uten desimal.
- Flytende komma: Med en størrelse på 4 byte vil den lagre brøktall som har en eller flere desimaler. Dette er tilstrekkelig for lagring av opptil 7 desimaler.
- Dobbelt flytende komma: Med en størrelse på 8 byte vil den også lagre brøktallene som har en eller flere desimaler. Dette er tilstrekkelig for lagring av opptil 15 desimaler.
- Void: Uten spesifisert størrelse inneholder et tomrom noe verdiløst. Derfor brukes den for funksjonene som returnerer en nullverdi.
- Bredt tegn: Med en størrelse større enn 8-bit som vanligvis er 2 eller 4 byte lang er representert av wchar_t som ligner på char og lagrer dermed også en tegnverdi.
Størrelsen på de ovennevnte variablene kan variere avhengig av bruken av programmet eller kompilatoren.
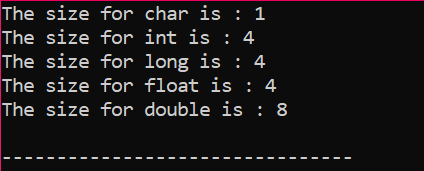
Eksempel:
La oss bare skrive en enkel kode i C++ som vil gi de nøyaktige størrelsene på noen få datatyper beskrevet ovenfor:

I denne koden integrerer vi biblioteket
Utgangen mottas i byte som vist i figuren:
Eksempel:
Her vil vi legge til størrelsen på to forskjellige datatyper.
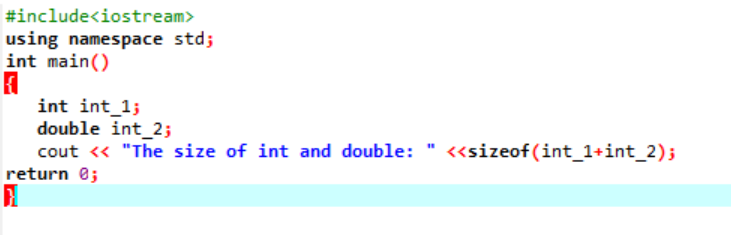
Først inkorporerer vi en overskriftsfil som bruker et 'standard navneområde' for identifikatorer. Neste, den hoved() funksjon kalles der vi initialiserer 'int'-variabelen først og deretter en 'dobbel'-variabel for å sjekke forskjellen mellom størrelsene på disse to. Deretter blir størrelsene deres sammenkoblet ved bruk av størrelsen av() funksjon. Utgangen vises med 'cout'-setningen.

Det er ett begrep til som må nevnes her, og det er det «Datamodifikatorer» . Navnet antyder at 'datamodifikatorene' brukes langs de innebygde datatypene for å endre lengdene deres som en bestemt datatype kan opprettholde av kompilatorens behov eller krav.
Følgende er datamodifikatorene som er tilgjengelige i C++:
- Signert
- Usignert
- Lang
- Kort
Den modifiserte størrelsen og også passende rekkevidde av de innebygde datatypene er nevnt nedenfor når de kombineres med datatypemodifikatorene:
- Kort int: Har størrelsen på 2 byte, har en rekke modifikasjoner fra -32 768 til 32 767
- Usignert kort int: Har størrelsen 2 byte, har en rekke modifikasjoner fra 0 til 65 535
- Usignert int: Har størrelsen på 4 byte, har en rekke modifikasjoner fra 0 til 4,294,967,295
- Int: Har størrelsen på 4 byte, har en rekke modifikasjoner fra -2.147.483.648 til 2.147.483.647
- Long int: Har størrelsen på 4 byte, har et modifikasjonsområde fra -2.147.483.648 til 2.147.483.647
- Usignert lang int: Har størrelsen på 4 byte, har en rekke modifikasjoner fra 0 til 4,294,967.295
- Lang lang int: Har størrelsen på 8 byte, har en rekke modifikasjoner fra –(2^63) til (2^63)-1
- Usignert lang lang int: Har størrelsen 8 byte, har en rekke modifikasjoner fra 0 til 18.446.744.073.709.551.615
- Signert tegn: Har størrelsen 1 byte, har en rekke modifikasjoner fra -128 til 127
- Usignert tegn: Med størrelsen 1 byte, har en rekke modifikasjoner fra 0 til 255.
C++-oppregning:
I programmeringsspråket C++ er 'Enumeration' en brukerdefinert datatype. Opptelling er erklært som en enum' i C++. Den brukes til å tildele spesifikke navn til enhver konstant som brukes i programmet. Det forbedrer programmets lesbarhet og brukervennlighet.
Syntaks:
Vi erklærer opptelling i C++ som følger:
enum enum_Name { Konstant 1 , Konstant 2 , Konstant 3... }Fordeler med opptelling i C++:
Enum kan brukes på følgende måter:
- Den kan brukes ofte i byttetilfeller.
- Den kan bruke konstruktører, felt og metoder.
- Den kan bare utvide 'enum'-klassen, ikke noen annen klasse.
- Det kan øke kompileringstiden.
- Den kan krysses.
Ulemper med oppregning i C++:
Enum har også få ulemper:
Hvis et navn først er oppregnet, kan det ikke brukes igjen i samme omfang.
For eksempel:
enum Dager{ Lør , Sol , Min } ;
int Lør = 8 ; // Denne linjen har feil
Enum kan ikke videresendes.
For eksempel:
enum former ;klasse farge
{
tomrom tegne ( former aShape ) ; //former er ikke deklarert
} ;
De ser ut som navn, men de er heltall. Så de kan automatisk konvertere til en hvilken som helst annen datatype.
For eksempel:
enum former{
Triangel , sirkel , torget
} ;
int farge = blå ;
farge = torget ;
Eksempel:
I dette eksemplet ser vi bruken av C++-oppregning:
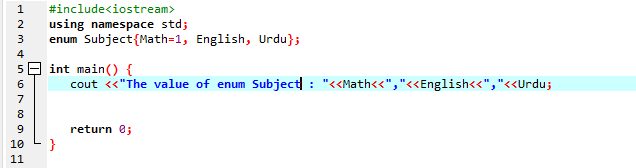
I denne kodekjøringen starter vi først med #include
Her er resultatet av det utførte programmet:

Så, som du kan se at vi har verdier for emne: matematikk, urdu, engelsk; det vil si 1,2,3.
Eksempel:
Her er et annet eksempel der vi fjerner begrepene våre om enum:
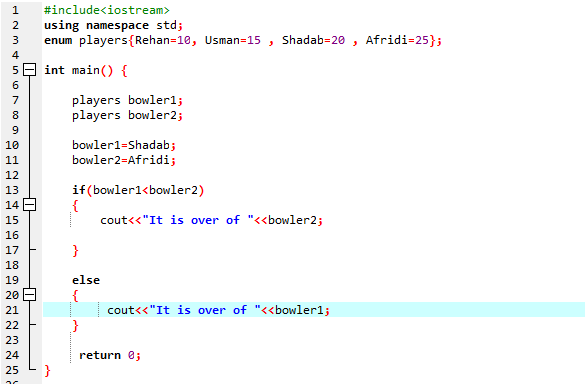
I dette programmet starter vi med å integrere header-filen
Vi må bruke en if-else-setning . Vi har også brukt sammenligningsoperatoren i ‘if’-setningen som betyr at vi sammenligner om ‘bowler2’ er større enn ‘bowler1’. Deretter kjøres 'hvis'-blokken, noe som betyr at det er Afridis over. Deretter skrev vi 'cout<<' for å vise utdataene. Først skriver vi ut setningen 'Det er over'. Deretter verdien av 'bowler2'. Hvis ikke, påkalles den andre blokken, noe som betyr at den er over av Shadab. Deretter, ved å bruke 'cout<<'-kommandoen, viser vi utsagnet 'Det er over'. Deretter verdien av 'bowler1'.

I følge If-else-uttalelsen har vi over 25 som er verdien av Afridi. Det betyr at verdien av enum-variabelen 'bowler2' er større enn 'bowler1', det er grunnen til at 'if'-setningen blir utført.
C++ Hvis annet, bytt:
I programmeringsspråket C ++ bruker vi 'if-setningen' og 'switch-setningen' for å endre programmets flyt. Disse setningene brukes til å gi flere sett med kommandoer for implementering av programmet avhengig av den sanne verdien av de nevnte setningene. I de fleste tilfeller bruker vi operatører som alternativer til 'hvis'-setningen. Alle disse ovennevnte uttalelsene er utvalgserklæringene som er kjent som beslutnings- eller betingede uttalelser.
'Hvis'-utsagnet:
Denne uttalelsen brukes til å teste en gitt tilstand når du føler for å endre flyten til et hvilket som helst program. Her, hvis en betingelse er sann, vil programmet utføre de skriftlige instruksjonene, men hvis betingelsen er falsk, vil den bare avsluttes. La oss vurdere et eksempel;
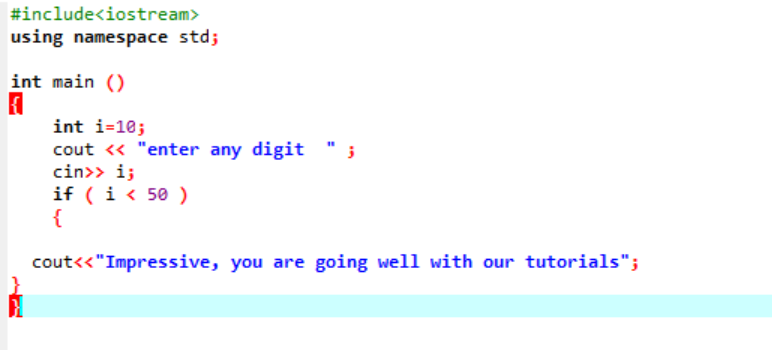
Dette er den enkle 'if'-setningen som brukes, der vi initialiserer en 'int'-variabel som 10. Deretter blir en verdi tatt fra brukeren og den krysssjekkes i 'if'-setningen. Hvis den tilfredsstiller betingelsene som er brukt i 'if'-setningen, vises utdataene.

Siden sifferet som ble valgt var 40, er utgangen meldingen.
'Hvis annet'-uttalelsen:
I et mer komplekst program der 'hvis'-setningen vanligvis ikke samarbeider, bruker vi 'hvis-else'-setningen. I det gitte tilfellet bruker vi «hvis-else»-erklæringen for å kontrollere betingelsene som er brukt.
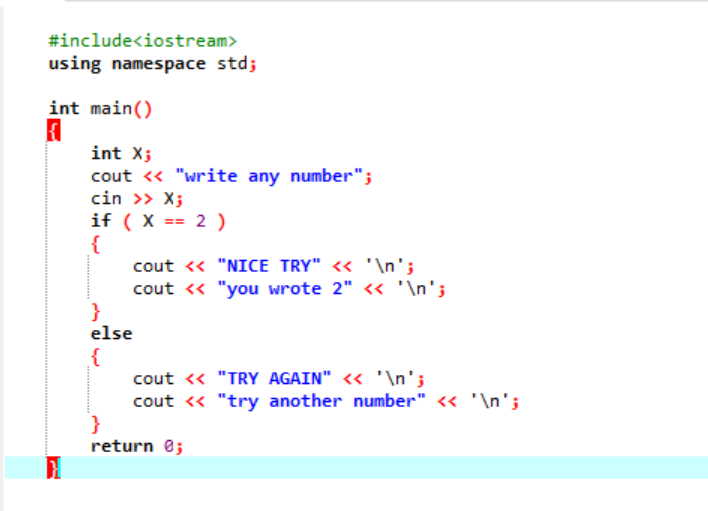
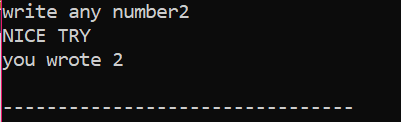
Først vil vi erklære en variabel av datatype 'int' kalt 'x' hvis verdi er hentet fra brukeren. Nå brukes 'if'-setningen der vi brukte en betingelse om at hvis heltallsverdien angitt av brukeren er 2. Utdata vil være den ønskede og en enkel 'NICE TRY'-melding vil vises. Ellers, hvis det angitte tallet ikke er 2, vil utgangen være annerledes.
Når brukeren skriver tallet 2, vises følgende utgang.
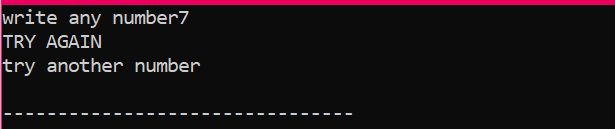
Når brukeren skriver et hvilket som helst annet tall unntatt 2, er utdataene vi får:
If-else-if-utsagnet:
Nestede if-else-if-setninger er ganske komplekse og brukes når det er flere betingelser brukt i samme kode. La oss tenke over dette ved å bruke et annet eksempel:
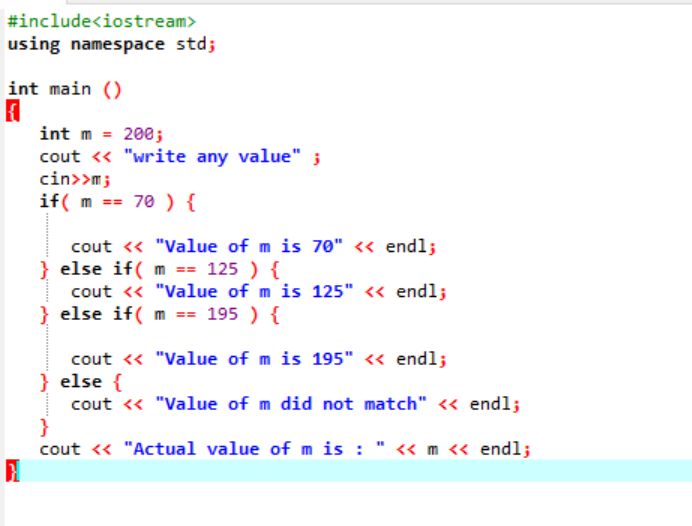
Her, etter å ha integrert overskriftsfilen og navneområdet, initialiserte vi en verdi av variabel 'm' som 200. Verdien av 'm' blir så tatt fra brukeren og krysssjekket med de flere betingelsene som er oppgitt i programmet.
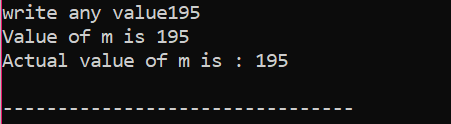
Her valgte brukeren verdi 195. Dette er grunnen til at utdata viser at dette er den faktiske verdien av 'm'.
Bytt uttalelse:
En 'switch'-setning brukes i C++ for en variabel som må testes hvis den er lik en liste med flere verdier. I «bytte»-erklæringen identifiserer vi forhold i form av distinkte saker og alle sakene har en pause inkludert på slutten av hver saksuttalelse. Flere tilfeller har riktige betingelser og setninger brukt på seg med break-setninger som avslutter switch-setningen og flytter til en standardsetning i tilfelle ingen betingelse støttes.
Søkeord «pause»:
Switch-setningen inneholder nøkkelordet 'break'. Det stopper koden fra å kjøre på den påfølgende saken. Switch-setningens utførelse avsluttes når C++-kompilatoren kommer over nøkkelordet 'break' og kontrollen flytter til linjen som følger switch-setningen. Det er ikke nødvendig å bruke en pauseerklæring i en bryter. Utførelsen går videre til neste sak hvis den ikke brukes.
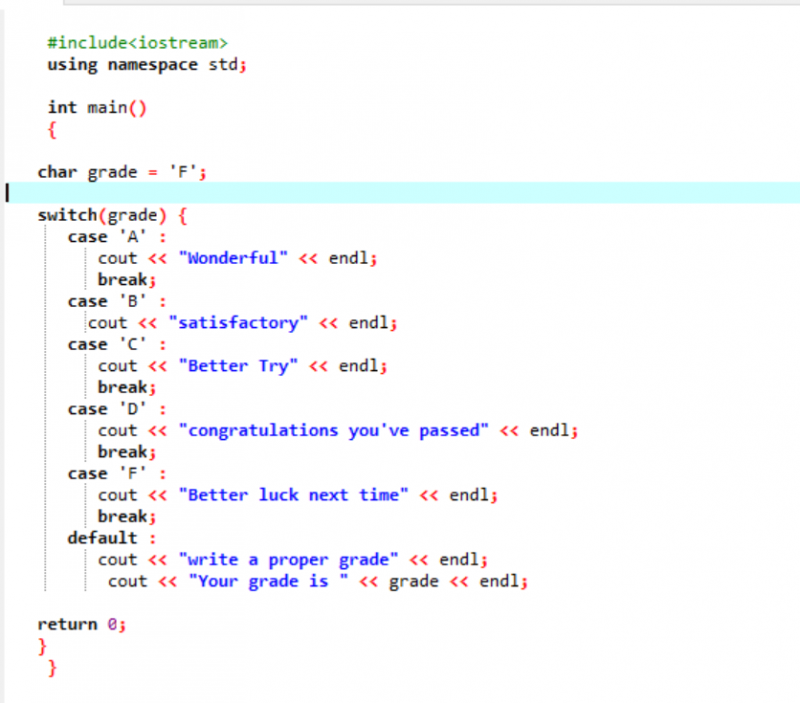
I den første linjen i den delte koden inkluderer vi biblioteket. Deretter legger vi til 'navneområde'. Vi påkaller hoved() funksjon. Deretter erklærer vi en karakterdatatype karakter som 'F'. Denne karakteren kan være ditt ønske, og resultatet vil bli vist henholdsvis for de valgte tilfellene. Vi brukte bytteerklæringen for å få resultatet.
Hvis vi velger 'F' som karakter, er resultatet 'bedre lykke neste gang' fordi dette er påstanden om at vi ønsker å bli skrevet ut i tilfelle karakteren er 'F'.

La oss endre karakteren til X og se hva som skjer. Jeg skrev 'X' som karakteren, og resultatet som ble mottatt vises nedenfor:

Så, upassende tilfelle i 'bryteren' flytter automatisk pekeren direkte til standardsetningen og avslutter programmet.
If-else og switch-setninger har noen fellestrekk:
- Disse uttalelsene brukes til å administrere hvordan programmet kjøres.
- De vurderer begge en tilstand og det avgjør hvordan programmet flyter.
- Til tross for at de har forskjellige representasjonsstiler, kan de brukes til samme formål.
If-else og switch-setninger er forskjellige på visse måter:
- Mens brukeren definerte verdiene i 'switch'-tilfellesetninger, mens begrensninger bestemmer verdiene i 'if-else'-setninger.
- Det tar tid å finne ut hvor endringen må gjøres, det er utfordrende å modifisere 'hvis annet'-utsagn. På den andre siden er 'bytte'-setninger enkle å oppdatere fordi de enkelt kan endres.
- For å inkludere mange uttrykk kan vi bruke mange 'hvis-annes'-utsagn.
C++-løkker:
Nå vil vi finne ut hvordan du bruker loops i C++-programmering. Kontrollstrukturen kjent som en 'løkke' gjentar en rekke utsagn. Med andre ord kalles det repeterende struktur. Alle setningene utføres samtidig i en sekvensiell struktur . På den annen side, avhengig av den angitte setningen, kan betingelsesstrukturen utføre eller utelate et uttrykk. Det kan være nødvendig å utføre en erklæring mer enn én gang i spesielle situasjoner.
Typer løkker:
Det er tre kategorier av løkker:
For loop:
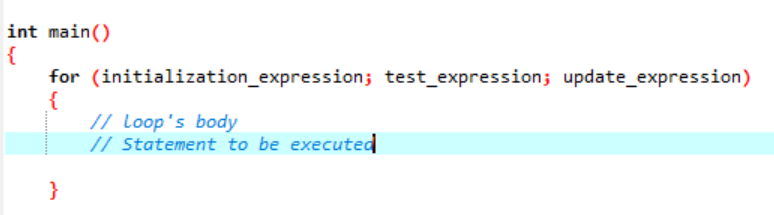
Loop er noe som gjentar seg selv som en syklus og stopper når den ikke validerer tilstanden som er gitt. En 'for'-løkke implementerer en sekvens av utsagn flere ganger og kondenserer koden som takler loop-variabelen. Dette demonstrerer hvordan en 'for'-løkke er en spesifikk type iterativ kontrollstruktur som lar oss lage en loop som gjentas et bestemt antall ganger. Løkken ville tillate oss å utføre 'N' antall trinn ved å bruke bare en kode av en enkel linje. La oss snakke om syntaksen som vi skal bruke for en 'for'-løkke som skal utføres i programvareapplikasjonen din.
Syntaksen for 'for' løkkekjøring:
Eksempel:
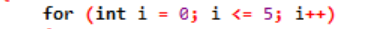
Her bruker vi en løkkevariabel for å regulere denne løkken i en 'for' løkke. Det første trinnet ville være å tilordne en verdi til denne variabelen vi oppgir som en løkke. Etter det må vi definere om den er mindre eller større enn tellerverdien. Nå skal hoveddelen av loopen kjøres, og også loop-variabelen oppdateres i tilfelle setningen returnerer sann. Trinnene ovenfor gjentas ofte til vi når utgangstilstanden.
- Initialiseringsuttrykk: Først må vi sette looptelleren til en hvilken som helst startverdi i dette uttrykket.
- Testuttrykk : Nå må vi teste den gitte tilstanden i det gitte uttrykket. Hvis kriteriene er oppfylt, vil vi utføre 'for'-løkkens kropp og fortsette å oppdatere uttrykket; hvis ikke, må vi stoppe.
- Oppdater uttrykk: Dette uttrykket øker eller reduserer løkkevariabelen med en viss verdi etter at løkkens kropp er utført.
Eksempler på C++-program for å validere en 'For'-løkke:
Eksempel:
Dette eksemplet viser utskrift av heltallsverdier fra 0 til 10.
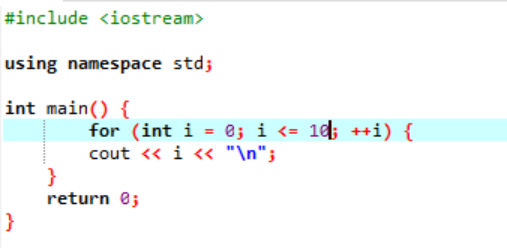
I dette scenariet er det meningen at vi skal skrive ut heltallene fra 0 til 10. Først initialiserte vi en tilfeldig variabel i med en verdi er gitt '0', og deretter kontrollerer betingelsesparameteren vi allerede har brukt betingelsen hvis i<=10. Og når den tilfredsstiller betingelsen og den blir sann, begynner utførelsen av 'for'-løkken. Etter utførelsen, blant de to inkrement- eller dekrementparameterne, skal en utføres, og der inntil den spesifiserte tilstanden i<=10 blir til usann, økes verdien av variabelen i.

Antall iterasjoner med betingelse i<10:
| Antall av iterasjoner |
Variabler | jeg <10 | Handling |
| Først | i=0 | ekte | 0 vises og i økes med 1. |
| Sekund | i=1 | ekte | 1 vises og i økes med 2. |
| Tredje | i=2 | ekte | 2 vises og i økes med 3. |
| Fjerde | i=3 | ekte | 3 vises og i økes med 4. |
| Femte | i=4 | ekte | 4 vises og i økes med 5. |
| Sjette | i=5 | ekte | 5 vises og i økes med 6. |
| Syvende | i=6 | ekte | 6 vises og i økes med 7. |
| Åttende | i=7 | ekte | 7 vises og i økes med 8 |
| Niende | i=8 | ekte | 8 vises og i økes med 9. |
| Tiende | i=9 | ekte | 9 vises og i økes med 10. |
| Ellevte | i=10 | ekte | 10 vises og i økes med 11. |
| Tolvte | i=11 | falsk | Sløyfen avsluttes. |
Eksempel:
Følgende forekomst viser verdien av heltallet:
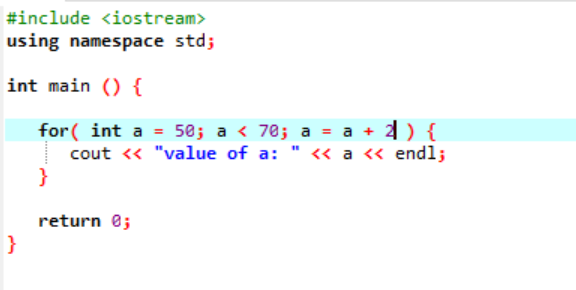
I tilfellet ovenfor initialiseres en variabel kalt 'a' med en verdi gitt 50. En betingelse brukes der variabelen 'a' er mindre enn 70. Deretter oppdateres verdien av 'a' slik at den legges til med 2. Verdien av 'a' startes deretter fra en startverdi som var 50 og 2 legges til samtidig gjennom hele sløyfen til betingelsen returnerer falsk og verdien av 'a' økes fra 70 og løkken avsluttes.
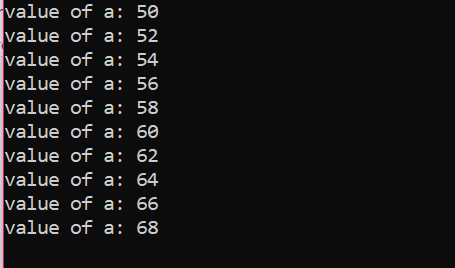
Antall iterasjoner:
| Antall av Iterasjon |
Variabel | a=50 | Handling |
| Først | a=50 | ekte | Verdien av a oppdateres ved å legge til ytterligere to heltall og 50 blir 52 |
| Sekund | a=52 | ekte | Verdien av a oppdateres ved å legge til ytterligere to heltall og 52 blir 54 |
| Tredje | a=54 | ekte | Verdien av a oppdateres ved å legge til ytterligere to heltall og 54 blir 56 |
| Fjerde | a=56 | ekte | Verdien av a oppdateres ved å legge til ytterligere to heltall og 56 blir 58 |
| Femte | a=58 | ekte | Verdien av a oppdateres ved å legge til ytterligere to heltall og 58 blir 60 |
| Sjette | a=60 | ekte | Verdien av a oppdateres ved å legge til ytterligere to heltall og 60 blir 62 |
| Syvende | a=62 | ekte | Verdien av a oppdateres ved å legge til ytterligere to heltall og 62 blir 64 |
| Åttende | a=64 | ekte | Verdien av a oppdateres ved å legge til ytterligere to heltall og 64 blir 66 |
| Niende | a=66 | ekte | Verdien av a oppdateres ved å legge til ytterligere to heltall og 66 blir 68 |
| Tiende | a=68 | ekte | Verdien av a oppdateres ved å legge til ytterligere to heltall og 68 blir 70 |
| Ellevte | a=70 | falsk | Sløyfen avsluttes |
Mens loop:
Inntil den definerte betingelsen er oppfylt, kan en eller flere setninger utføres. Når iterasjon er ukjent på forhånd, er det veldig nyttig. Først sjekkes betingelsen og kommer deretter inn i løkkens kropp for å utføre eller implementere setningen.
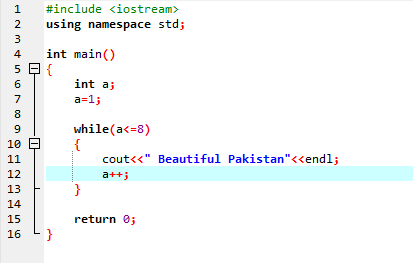
I den første linjen inkorporerer vi overskriftsfilen
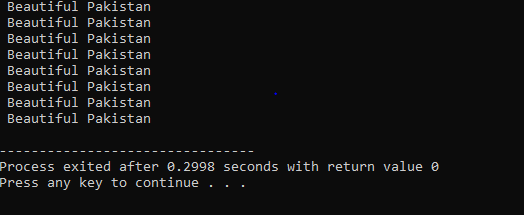
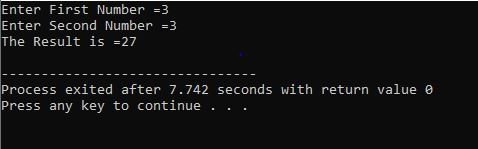
Do-While Loop:
Når den definerte betingelsen er oppfylt, utføres en rekke utsagn. Først bæres løkkens kropp ut. Etter det sjekkes tilstanden om den er sann eller ikke. Derfor utføres setningen én gang. Hoveddelen av løkken behandles i en 'Do-while'-løkke før tilstanden evalueres. Programmet kjører når den nødvendige betingelsen er oppfylt. Ellers, når betingelsen er falsk, avsluttes programmet.
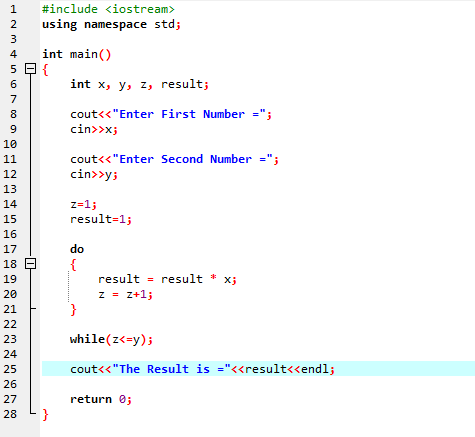
Her integrerer vi overskriftsfilen
C++ Fortsett/Break:
C++ Fortsett-erklæring:
Fortsett-setningen brukes i programmeringsspråket C++ for å unngå en gjeldende inkarnasjon av en løkke, samt flytte kontrollen til den påfølgende iterasjonen. Under looping kan fortsette-setningen brukes til å hoppe over visse utsagn. Det brukes også innenfor loopen sammen med lederuttalelser. Hvis den spesifikke betingelsen er sann, implementeres ikke alle utsagn etter fortsett-setningen.
Med for loop:
I dette tilfellet bruker vi 'for loop' med continu-setningen fra C++ for å få det nødvendige resultatet mens vi oppfyller noen spesifiserte krav.

Vi begynner med å inkludere
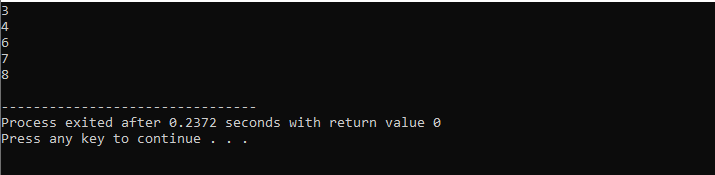
Med en while-løkke:
Gjennom denne demonstrasjonen brukte vi både «while loop» og C++ «continue»-setningen inkludert noen betingelser for å se hva slags utdata som kan genereres.
I dette eksemplet setter vi en betingelse for å legge til tall kun til 40. Hvis det angitte hele tallet er et negativt tall, vil 'mens'-løkken avsluttes. På den annen side, hvis tallet er større enn 40, vil det spesifikke tallet hoppes over fra iterasjonen.
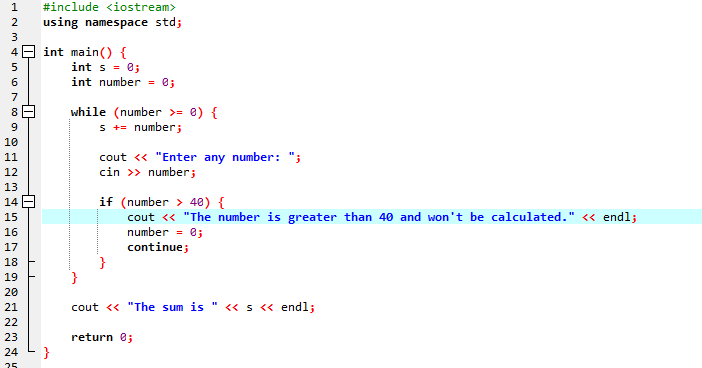
Vi vil inkludere
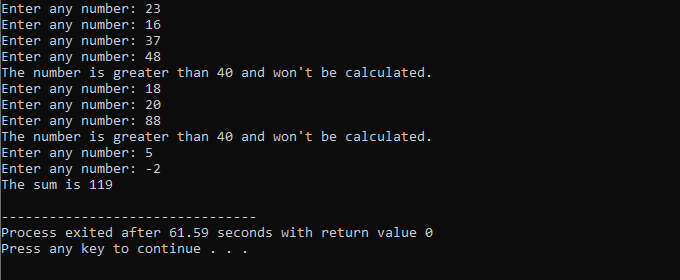
C++ break-erklæring:
Hver gang break-setningen brukes i en løkke i C++, avsluttes løkken umiddelbart, og programkontrollen starter på nytt ved setningen etter løkken. Det er også mulig å avslutte en sak i en 'switch'-erklæring.
Med for loop:
Her vil vi bruke 'for'-løkken med 'break'-setningen for å observere utdataene ved å iterere over forskjellige verdier.
Først inkorporerer vi en
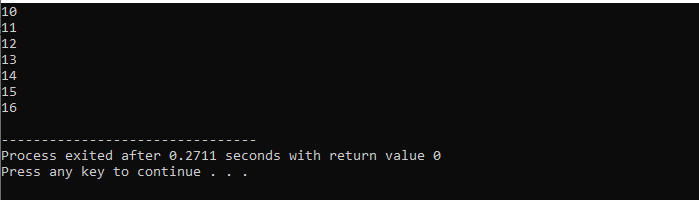
Med en while-løkke:
Vi kommer til å bruke «while»-løkken sammen med pauseerklæringen.
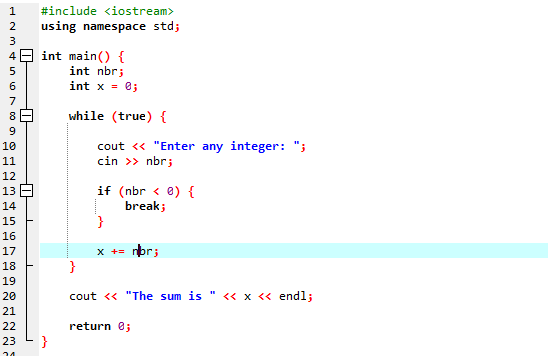
Vi starter med å importere
C++ funksjoner:
Funksjoner brukes til å strukturere et allerede kjent program i flere fragmenter av koder som bare kjøres når det kalles. I programmeringsspråket C++ er en funksjon definert som en gruppe setninger som får et passende navn og kalles opp av dem. Brukeren kan overføre data til funksjonene som vi kaller parametere. Funksjoner er ansvarlige for å implementere handlingene når koden mest sannsynlig vil bli gjenbrukt.
Oppretting av en funksjon:
Selv om C++ leverer mange forhåndsdefinerte funksjoner som hoved(), som letter utførelse av koden. På samme måte kan du opprette og definere funksjonene dine i henhold til dine behov. Akkurat som alle de vanlige funksjonene, her, trenger du et navn for funksjonen din for en erklæring som legges til med en parentes etterpå '()'.
Syntaks:
Ugyldig Arbeiderpartiet ( ){
// kroppen til funksjonen
}
Void er returtypen til funksjonen. Arbeid er navnet gitt til den, og de krøllede parentesene vil omslutte kroppen til funksjonen der vi legger til koden for utførelse.
Kalle opp en funksjon:
Funksjonene som er deklarert i koden, utføres bare når de påkalles. For å kalle en funksjon, må du spesifisere navnet på funksjonen sammen med parentesen som er etterfulgt av et semikolon ';'.
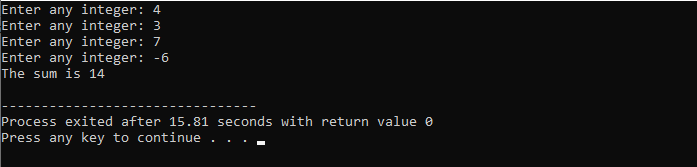
Eksempel:
La oss erklære og konstruere en brukerdefinert funksjon i denne situasjonen.
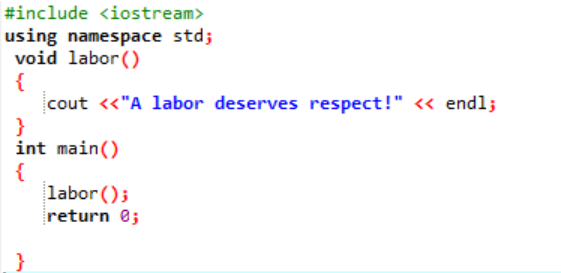
Til å begynne med, som beskrevet i hvert program, er vi tildelt et bibliotek og navneområde for å støtte kjøringen av programmet. Den brukerdefinerte funksjonen arbeid() kalles alltid før du skriver ned hoved() funksjon. En funksjon kalt arbeid() er erklært der meldingen 'A labor deserves respect!' vises. I hoved() funksjon med heltallsreturtypen kaller vi arbeid() funksjon.

Dette er den enkle meldingen som ble definert i den brukerdefinerte funksjonen som vises her ved hjelp av hoved() funksjon.
Tomrom:
I det nevnte tilfellet la vi merke til at den brukerdefinerte funksjonens returtype er ugyldig. Dette indikerer at ingen verdi returneres av funksjonen. Dette betyr at verdien ikke er tilstede eller sannsynligvis er null. Fordi når en funksjon bare skriver ut meldingene, trenger den ingen returverdi.
Dette tomrommet brukes på samme måte i parameterrommet til funksjonen for å tydelig si at denne funksjonen ikke tar noen faktisk verdi mens den kalles. I situasjonen ovenfor vil vi også kalle arbeid() fungere som:
Ugyldig arbeidskraft ( tomrom ){
Cout << «En arbeidskraft fortjener respekt ! ” ;
}
De faktiske parameterne:
Man kan definere parametere for funksjonen. Parametrene til en funksjon er definert i argumentlisten til funksjonen som legger til funksjonens navn. Hver gang vi kaller funksjonen, må vi sende de ekte verdiene til parameterne for å fullføre utførelsen. Disse konkluderes som de faktiske parameterne. Mens parameterne som er definert mens funksjonen er definert, er kjent som de formelle parametrene.
Eksempel:
I dette eksemplet er vi i ferd med å bytte ut eller erstatte de to heltallsverdiene gjennom en funksjon.
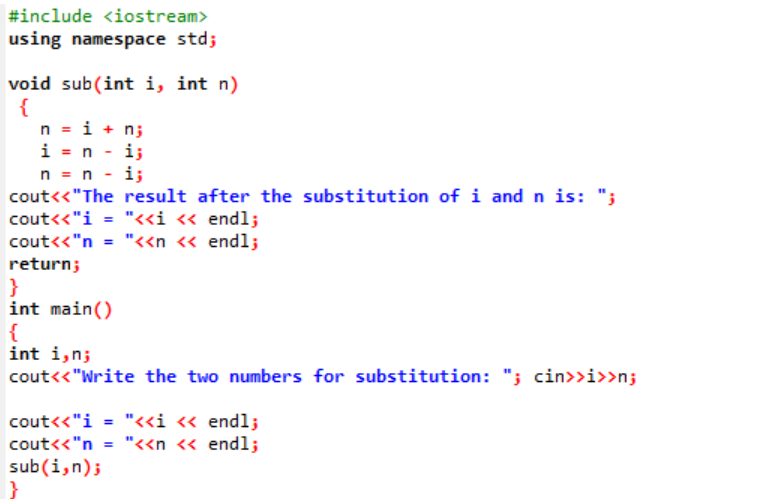
I begynnelsen tar vi inn overskriftsfilen. Den brukerdefinerte funksjonen er den deklarerte og definerte navngitte under(). Denne funksjonen brukes til å erstatte de to heltallsverdiene som er i og n. Deretter brukes de aritmetiske operatorene for utveksling av disse to heltallene. Verdien til det første heltall 'i' lagres i stedet for verdien 'n' og verdien av n lagres i stedet for verdien av 'i'. Deretter skrives resultatet etter bytte av verdier ut. Hvis vi snakker om hoved() funksjon, tar vi inn verdiene til de to heltallene fra brukeren og vises. I det siste trinnet, den brukerdefinerte funksjonen under() kalles og de to verdiene byttes.
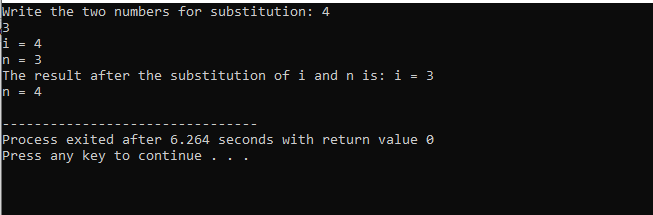
I dette tilfellet med å erstatte de to tallene, kan vi tydelig se at mens du bruker under() funksjon, er verdien av 'i' og 'n' inne i parameterlisten de formelle parameterne. De faktiske parameterne er parameteren som passerer på slutten av hoved() funksjon der substitusjonsfunksjonen kalles.
C++-pekere:
Pointer i C++ er ganske enklere å lære og flott å bruke. I C++ språk brukes pekere fordi de gjør arbeidet vårt enkelt og alle operasjoner fungerer med stor effektivitet når pekere er involvert. Det er også noen få oppgaver som ikke vil bli utført med mindre pekere brukes som dynamisk minnetildeling. Når vi snakker om pekere, er hovedideen som man må forstå at pekeren bare er en variabel som vil lagre den nøyaktige minneadressen som verdien. Den omfattende bruken av pekere i C++ er av følgende grunner:
- Å overføre en funksjon til en annen.
- For å tildele de nye objektene på haugen.
- For iterasjon av elementer i en matrise
Vanligvis brukes '&' (ampersand)-operatoren for å få tilgang til adressen til ethvert objekt i minnet.
Pekere og deres typer:
Pointer har følgende flere typer:
- Null-pekere: Dette er pekere med en verdi på null lagret i C++-bibliotekene.
- Aritmetisk peker: Den inkluderer fire store aritmetiske operatorer som er tilgjengelige som er ++, –, +, -.
- En rekke pekere: De er arrays som brukes til å lagre noen pekere.
- Peker til peker: Det er der en peker brukes over en peker.
Eksempel:
Tenk over det etterfølgende eksemplet der adressene til noen få variabler er skrevet ut.
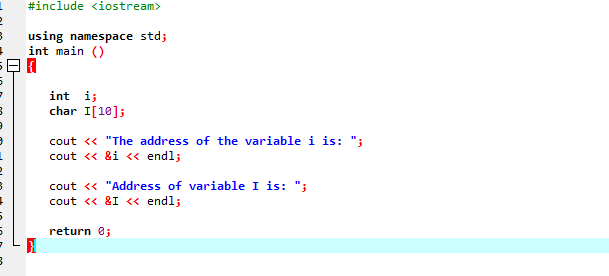
Etter å ha inkludert overskriftsfilen og standard navneområde, initialiserer vi to variabler. Den ene er en heltallsverdi representert av i' og en annen er en tegntype-array 'I' med størrelsen på 10 tegn. Adressene til begge variablene vises deretter ved å bruke 'cout'-kommandoen.
Utdataene vi har mottatt vises nedenfor:
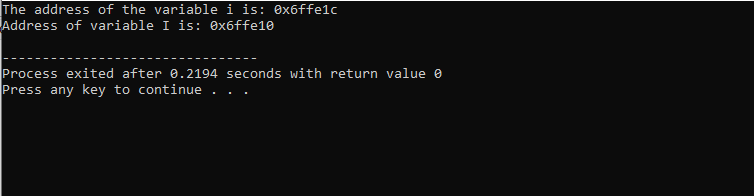
Dette utfallet viser adressen for begge variablene.
På den annen side regnes en peker som en variabel hvis verdi i seg selv er adressen til en annen variabel. En peker peker alltid på en datatype som har samme type som er opprettet med en (*)-operator.
Erklæring av en peker:
Pekeren erklæres på denne måten:
type * var - Navn ;Grunntypen til pekeren er angitt med 'type', mens pekerens navn er uttrykt med 'var-navn'. Og for å gi en variabel rett til pekeren brukes stjerne(*).
Måter å tilordne pekere til variablene:
Int * pi ; //pekeren til en heltallsdatatypeDobbelt * pd ; //peker av en dobbel datatype
Flyte * pf ; //pekeren til en flytende datatype
Char * pc ; //pekeren til en char-datatype
Nesten alltid er det et langt heksadesimalt tall som representerer minneadressen som i utgangspunktet er den samme for alle pekere uavhengig av datatypene deres.
Eksempel:
Følgende forekomst vil demonstrere hvordan pekere erstatter '&'-operatoren og lagrer adressen til variabler.
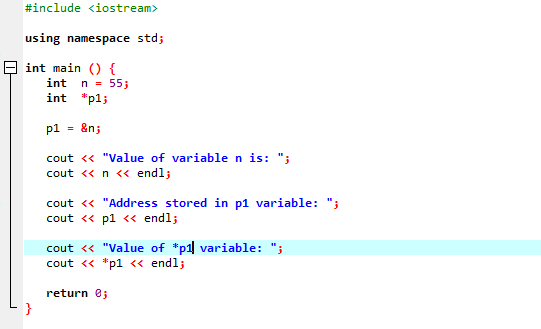
Vi skal integrere støtte for biblioteker og kataloger. Deretter vil vi påberope oss hoved() funksjon hvor vi først deklarerer og initialiserer en variabel ‘n’ av typen ‘int’ med verdien 55. I neste linje initialiserer vi en pekervariabel kalt ‘p1’. Etter dette tildeler vi adressen til 'n'-variabelen til pekeren 'p1' og så viser vi verdien til variabelen 'n'. Adressen til 'n' som er lagret i 'p1'-pekeren vises. Etterpå skrives verdien av '*p1' ut på skjermen ved å bruke 'cout'-kommandoen. Utgangen er som følger:
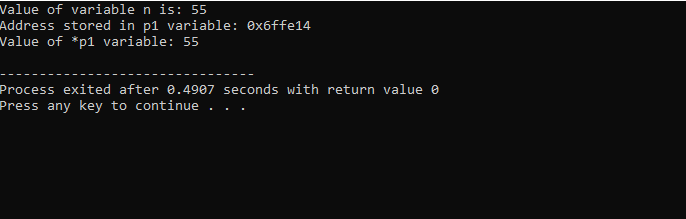
Her ser vi at verdien av 'n' er 55 og adressen til 'n' som ble lagret i pekeren 'p1' vises som 0x6ffe14. Verdien av pekervariabelen er funnet og den er 55 som er det samme som heltallsvariabelens verdi. Derfor lagrer en peker adressen til variabelen, og også *-pekeren har verdien av heltallet lagret, noe som resulterer i at verdien til variabelen som ble lagret i utgangspunktet.
Eksempel:
La oss vurdere et annet eksempel der vi bruker en peker som lagrer adressen til en streng.
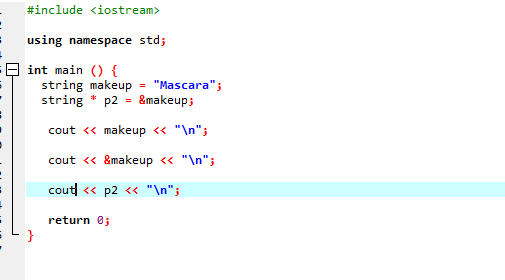
I denne koden legger vi først til biblioteker og navneområde. I hoved() funksjonen må vi deklarere en streng kalt 'sminke' som har verdien 'Mascara' i seg. En strengtypepeker '*p2' brukes til å lagre adressen til makeup-variabelen. Verdien av variabelen 'sminke' vises deretter på skjermen ved å bruke 'cout'-setningen. Etter dette skrives adressen til variabelen 'sminke' ut, og til slutt vises pekervariabelen 'p2' som viser minneadressen til 'sminke'-variabelen med pekeren.
Utgangen mottatt fra koden ovenfor er som følger:
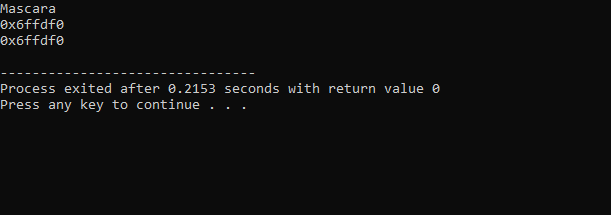
Den første linjen har verdien til «sminke»-variabelen vist. Den andre linjen viser adressen til variabelen 'sminke'. På den siste linjen vises minneadressen til 'sminke'-variabelen med bruk av pekeren.
C++ minnebehandling:
For effektiv minnebehandling i C++ er mange operasjoner nyttige for håndtering av minne mens du arbeider i C++. Når vi bruker C++, er den mest brukte minneallokeringsprosedyren dynamisk minneallokering der minner tilordnes variablene under kjøring; ikke som andre programmeringsspråk der kompilatoren kunne allokere minnet til variablene. I C++ er deallokeringen av variablene som ble dynamisk allokert nødvendig, slik at minnet frigjøres ledig når variabelen ikke lenger er i bruk.
For dynamisk allokering og deallokering av minnet i C++, gjør vi ' ny' og 'slett' operasjoner. Det er viktig å administrere minnet slik at ingen minne går til spille. Tildelingen av minnet blir enkelt og effektivt. I ethvert C++-program brukes minnet i ett av to aspekter: enten som en haug eller en stabel.
- Stable : Alle variablene som er deklarert inne i funksjonen og alle andre detaljer som er relatert til funksjonen lagres i stabelen.
- Heap : Enhver form for ubrukt minne eller delen hvorfra vi allokerer eller tildeler det dynamiske minnet under kjøringen av et program er kjent som en heap.
Når du bruker arrays, er minneallokeringen en oppgave der vi bare ikke kan bestemme minnet med mindre kjøretiden. Så vi tildeler maksimalt minne til arrayet, men dette er heller ikke en god praksis, da minnet i de fleste tilfeller forblir ubrukt og det på en eller annen måte er bortkastet, noe som ikke er et godt alternativ eller øvelse for din personlige datamaskin. Dette er grunnen til at vi har noen få operatører som brukes til å tildele minne fra heapen under kjøretiden. De to store operatørene «ny» og «slett» brukes for effektiv minneallokering og deallokering.
C++ ny operatør:
Den nye operatøren er ansvarlig for tildelingen av minnet og brukes som følger:
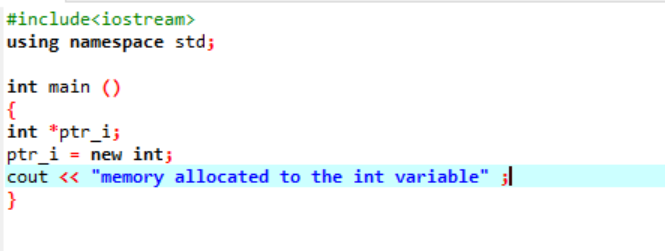
I denne koden inkluderer vi biblioteket

Minne har blitt allokert til 'int'-variabelen med hell ved bruk av en peker.
C++ sletteoperator:
Når vi er ferdige med å bruke en variabel, må vi deallokere minnet som vi en gang tildelte det fordi det ikke lenger er i bruk. For dette bruker vi 'slett'-operatoren for å frigjøre minnet.
Eksemplet som vi skal gjennomgå akkurat nå er å ha begge operatørene inkludert.
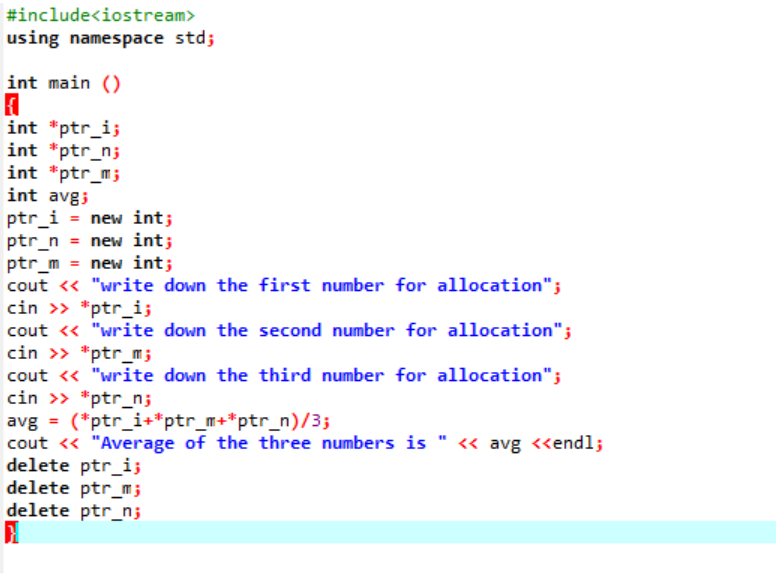
Vi beregner gjennomsnittet for tre forskjellige verdier hentet fra brukeren. Pekervariablene er tilordnet den 'nye' operatøren for å lagre verdiene. Formelen for gjennomsnitt er implementert. Etter dette brukes 'slett'-operatoren som sletter verdiene som ble lagret i pekervariablene ved å bruke 'ny'-operatoren. Dette er den dynamiske allokeringen der allokeringen gjøres i løpet av kjøretiden, og deretter deallokeringen skjer like etter at programmet avsluttes.
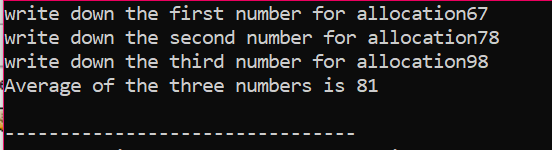
Bruk av array for minnetildeling:
Nå skal vi se hvordan de 'nye' og 'slett'-operatorene brukes mens de bruker arrays. Den dynamiske allokeringen skjer på samme måte som den skjedde for variablene da syntaksen er nesten den samme.
I det gitte tilfellet vurderer vi utvalget av elementer hvis verdi er hentet fra brukeren. Elementene i matrisen tas og pekervariabelen deklareres og minnet tildeles deretter. Rett etter minnetildelingen startes array-elementenes inndataprosedyre. Deretter vises utdataene for array-elementene ved å bruke en 'for'-løkke. Denne sløyfen har iterasjonsbetingelsen til elementer som har en størrelse mindre enn den faktiske størrelsen på matrisen som er representert av n.
Når alle elementene er brukt og det ikke er noen ytterligere krav for at de skal brukes igjen, vil minnet som er tilordnet til elementene bli deallokert ved å bruke 'slett'-operatoren.
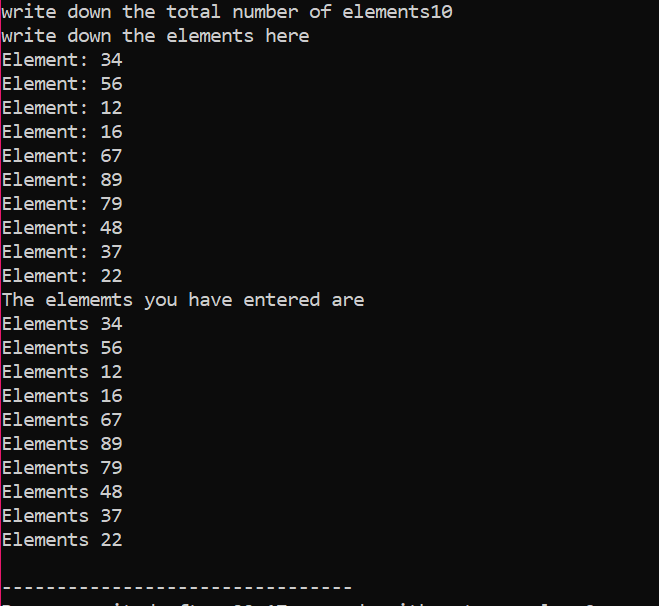
I utdataene kunne vi se sett med verdier skrevet ut to ganger. Den første 'for'-løkken ble brukt til å skrive ned verdiene for elementer, og den andre 'for'-løkken brukes til å skrive ut de allerede skrevne verdiene som viser at brukeren har skrevet disse verdiene for klarhet.
Fordeler:
Operatoren 'ny' og 'slett' er alltid prioritet i programmeringsspråket C++ og er mye brukt. Når man har en grundig diskusjon og forståelse, bemerkes det at den 'nye' operatøren har for mange fordeler. Fordelene med den 'nye' operatøren for tildeling av minnet er som følger:
- Den nye føreren kan overbelastes med større letthet.
- Når det tildeles minne under kjøretiden, vil det være et automatisk unntak når det ikke er nok minne, i stedet for bare programmet som avsluttes.
- Det travle med å bruke typecasting-prosedyren er ikke tilstede her fordi den 'nye' operatøren har akkurat samme type som minnet vi har tildelt.
- Den ‘nye’ operatoren avviser også ideen om å bruke sizeof()-operatoren da ‘new’ uunngåelig vil beregne størrelsen på objektene.
- Den 'nye' operatøren gjør det mulig for oss å initialisere og deklarere objektene selv om den genererer plass til dem spontant.
C++-matriser:
Vi skal ha en grundig diskusjon om hva arrays er og hvordan de er deklarert og implementert i et C++-program. Arrayen er en datastruktur som brukes til å lagre flere verdier i bare én variabel, og dermed reduserer stresset med å deklarere mange variabler uavhengig.
Deklarasjon av matriser:
For å deklarere en matrise, må man først definere typen variabel og gi et passende navn til matrisen som deretter legges til langs hakeparentesene. Dette vil inneholde antall elementer som viser størrelsen på en bestemt matrise.
For eksempel:
Sminke med strenger [ 5 ] ;Denne variabelen er deklarert og viser at den inneholder fem strenger i en matrise kalt 'sminke'. For å identifisere og illustrere verdiene for denne matrisen, må vi bruke de krøllede parentesene, med hvert element separat omsluttet av doble inverterte kommaer, hver atskilt med et enkelt komma i mellom.
For eksempel:
Sminke med strenger [ 5 ] = { “Mascara” , 'Fargenyanse' , 'Leppestift' , 'Fundament' , 'Først' } ;På samme måte, hvis du har lyst til å lage en annen matrise med en annen datatype som skal være 'int', vil prosedyren være den samme, du trenger bare å endre datatypen til variabelen som vist nedenfor:
int Multipler [ 5 ] = { to , 4 , 6 , 8 , 10 } ;Når man tilordner heltallsverdier til matrisen, må man ikke inneholde dem i de inverterte kommaene, som bare vil fungere for strengvariabelen. Så definitivt er en matrise en samling av innbyrdes relaterte dataelementer med avledede datatyper lagret i dem.
Hvordan får du tilgang til elementer i matrisen?
Alle elementene som er inkludert i matrisen er tildelt et distinkt nummer som er deres indeksnummer som brukes for å få tilgang til et element fra matrisen. Indeksverdien starter med 0 opp til én mindre enn størrelsen på matrisen. Den aller første verdien har indeksverdien 0.
Eksempel:
Tenk på et veldig enkelt og enkelt eksempel der vi vil initialisere variabler i en matrise.
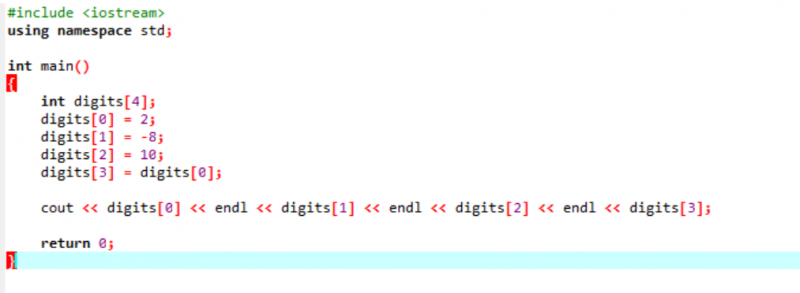
I det aller første trinnet inkorporerer vi
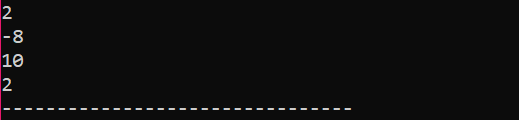
Dette er resultatet mottatt fra koden ovenfor. Nøkkelordet 'endl' flytter automatisk det andre elementet til neste linje.
Eksempel:
I denne koden bruker vi en 'for'-løkke for å skrive ut elementene i en matrise.

I tilfellet ovenfor legger vi til det essensielle biblioteket. Standard navneområde legges til. De hoved() funksjon er funksjonen der vi skal utføre alle funksjonene for kjøring av et bestemt program. Deretter erklærer vi en int type array kalt 'Num', som har en størrelse på 10. Verdien av disse ti variablene er hentet fra brukeren med bruk av 'for'-løkken. For visning av denne matrisen brukes en 'for'-løkke igjen. De 10 heltallene som er lagret i matrisen, vises ved hjelp av 'cout'-setningen.
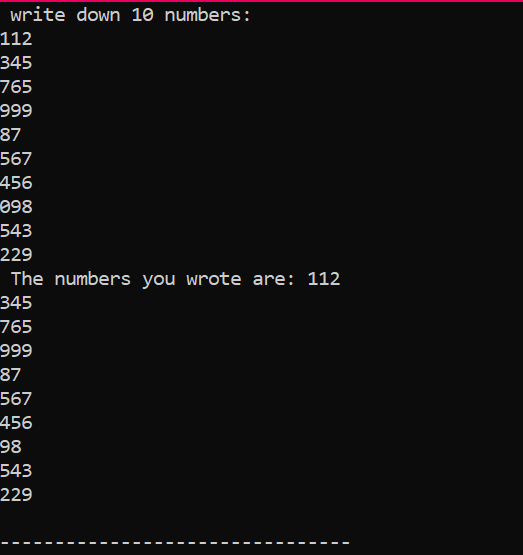
Dette er utdataene vi fikk fra utførelsen av koden ovenfor, som viser 10 heltall med forskjellige verdier.
Eksempel:
I dette scenariet er vi i ferd med å finne ut den gjennomsnittlige poengsummen til en elev og prosentandelen han har fått i klassen.
Først må du legge til et bibliotek som vil gi innledende støtte til C++-programmet. Deretter spesifiserer vi størrelsen 5 på matrisen kalt 'Score'. Deretter initialiserte vi en variabel 'sum' av datatypefloat. Poengsummene til hvert emne tas inn fra brukeren manuelt. Deretter brukes en 'for'-løkke for å finne ut gjennomsnittet og prosentandelen av alle fagene som er inkludert. Summen oppnås ved å bruke matrisen og 'for'-løkken. Deretter er gjennomsnittet funnet ved å bruke formelen for gjennomsnitt. Etter å ha funnet ut gjennomsnittet, overfører vi verdien til prosenten som legges til formelen for å få prosenten. Gjennomsnittet og prosenten beregnes deretter og vises.
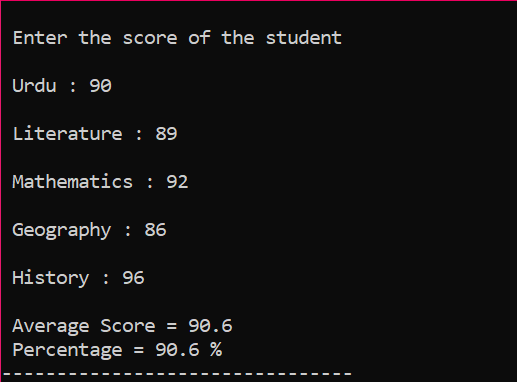
Dette er den endelige utgangen der poengsum tas inn fra brukeren for hvert emne individuelt og gjennomsnittet og prosenten beregnes henholdsvis.
Fordeler med å bruke Arrays:
- Elementer i matrisen er enkle å få tilgang til på grunn av indeksnummeret som er tildelt dem.
- Vi kan enkelt utføre søkeoperasjonen over en matrise.
- I tilfelle du ønsker kompleksitet i programmering, kan du bruke en 2-dimensjonal array som også karakteriserer matrisene.
- For å lagre flere verdier som har en lignende datatype, kan en matrise enkelt brukes.
Ulemper med å bruke Arrays:
- Arrays har en fast størrelse.
- Matriser er homogene, noe som betyr at bare en enkelt type verdi er lagret.
- Matriser lagrer data i det fysiske minnet individuelt.
- Innsettings- og slettingsprosessen er ikke lett for arrays.
C++ objekter og klasser:
C++ er et objektorientert programmeringsspråk, som betyr at objekter spiller en viktig rolle i C++. Når man snakker om objekter, må man først vurdere hva objekter er, så et objekt er en hvilken som helst forekomst av klassen. Siden C++ omhandler konseptene til OOP, er de viktigste tingene som skal diskuteres objektene og klassene. Klasser er faktisk datatyper som er definert av brukeren selv og er utpekt til å kapsle inn datamedlemmene og funksjonene som kun er tilgjengelige når forekomsten for den aktuelle klassen opprettes. Datamedlemmer er variablene som er definert i klassen.
Klasse er med andre ord en disposisjon eller design som er ansvarlig for definisjonen og erklæringen av datamedlemmene og funksjonene som er tildelt disse datamedlemmene. Hvert av objektene som er deklarert i klassen vil kunne dele alle egenskapene eller funksjonene som er demonstrert av klassen.
Anta at det er en klasse som heter fugler, nå kunne i utgangspunktet alle fuglene fly og ha vinger. Derfor er flyging en oppførsel som disse fuglene adopterer, og vingene er en del av kroppen deres eller en grunnleggende egenskap.
Definere en klasse:
For å definere en klasse, må du følge opp syntaksen og tilbakestille den i henhold til klassen din. Nøkkelordet 'klasse' brukes for å definere klassen, og alle de andre datamedlemmene og funksjonene er definert innenfor de krøllede parentesene etterfulgt av klassens definisjon.
Class NameOfClass
{
Tilgangsspesifikasjoner :
Datamedlemmer ;
Datamedlemsfunksjoner ( ) ;
} ;
Erklære objekter:
Rett etter å ha definert en klasse, må vi lage objektene for å få tilgang til og definere funksjonene som ble spesifisert av klassen. For det må vi skrive navnet på klassen og deretter navnet på objektet som skal deklareres.
Tilgang til datamedlemmer:
Du får tilgang til funksjonene og datamedlemmene ved hjelp av en enkel prikk-operatør. De offentlige datamedlemmene er også tilgjengelige med denne operatøren, men når det gjelder de private datamedlemmene, kan du bare ikke få direkte tilgang til dem. Tilgangen til datamedlemmene avhenger av tilgangskontrollene som er gitt dem av tilgangsmodifikatorene som enten er private, offentlige eller beskyttede. Her er et scenario som viser hvordan du deklarerer den enkle klassen, datamedlemmer og funksjoner.
Eksempel:
I dette eksemplet skal vi definere noen få funksjoner og få tilgang til klassefunksjonene og datamedlemmene ved hjelp av objektene.
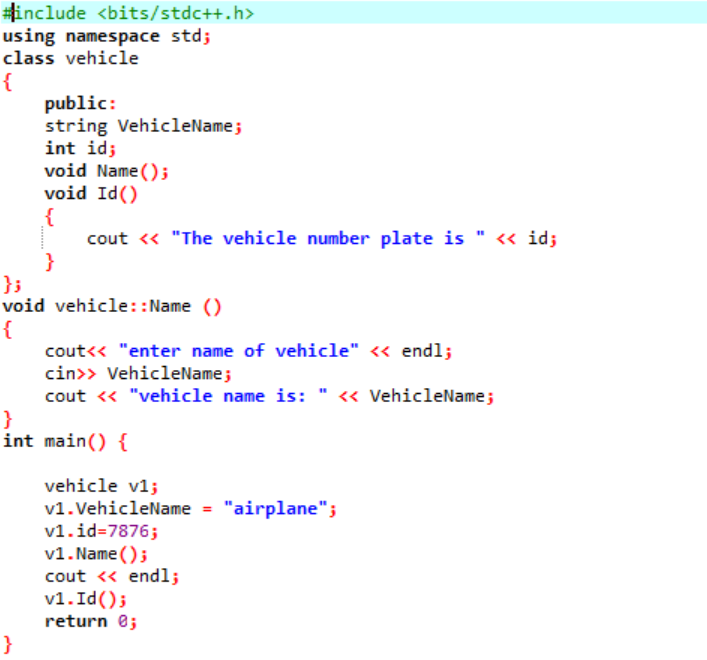
I det første trinnet integrerer vi biblioteket, hvoretter vi må inkludere støttekatalogene. Klassen er eksplisitt definert før den kalles hoved() funksjon. Denne klassen kalles 'kjøretøy'. Datamedlemmene var «navnet på kjøretøyet og «id» til det kjøretøyet, som er platenummeret for det kjøretøyet som har en streng, og int datatype. De to funksjonene er deklarert for disse to datamedlemmene. De id() funksjonen viser kjøretøyets ID. Siden datamedlemmene i klassen er offentlige, kan vi også få tilgang til dem utenfor klassen. Derfor kaller vi Navn() funksjon utenfor klassen og deretter ta inn verdien for 'VehicleName' fra brukeren og skrive den ut i neste trinn. I hoved() funksjon, erklærer vi et objekt av den nødvendige klassen som vil hjelpe med å få tilgang til datamedlemmene og funksjonene fra klassen. Videre initialiserer vi verdiene for kjøretøyets navn og dets id, bare hvis brukeren ikke oppgir verdien for kjøretøyets navn.
Dette er utgangen som mottas når brukeren oppgir navnet på kjøretøyet selv og nummerplatene er den statiske verdien som er tildelt det.
Når man snakker om definisjonen av medlemsfunksjonene, må man forstå at det ikke alltid er obligatorisk å definere funksjonen inne i klassen. Som du kan se i eksemplet ovenfor, definerer vi funksjonen til klassen utenfor klassen fordi datamedlemmene er offentlig deklarert, og dette gjøres ved hjelp av scope resolution-operatoren vist som '::' sammen med navnet på klassen og funksjonens navn.
C++ konstruktører og destruktorer:
Vi skal ha et grundig syn på dette temaet ved hjelp av eksempler. Sletting og oppretting av objektene i C++-programmering er svært viktig. For det, når vi oppretter en forekomst for en klasse, kaller vi automatisk konstruktørmetodene i noen få tilfeller.
Konstruktører:
Som navnet indikerer, er en konstruktør avledet fra ordet 'konstruksjon' som spesifiserer skapelsen av noe. Så en konstruktør er definert som en avledet funksjon av den nyopprettede klassen som deler klassens navn. Og den brukes til initialisering av objektene som er inkludert i klassen. En konstruktør har heller ikke en returverdi for seg selv, noe som betyr at dens returtype heller ikke vil være ugyldig. Det er ikke obligatorisk å akseptere argumentene, men man kan legge dem til om nødvendig. Konstruktører er nyttige ved allokering av minne til objektet til en klasse og ved å angi startverdien for medlemsvariablene. Startverdien kan sendes i form av argumenter til konstruktørfunksjonen når objektet er initialisert.
Syntaks:
NameOfTheClass ( ){
//kroppen til konstruktøren
}
Typer konstruktører:
Parameterisert konstruktør:
Som diskutert tidligere har ikke en konstruktør noen parameter, men man kan legge til en parameter etter eget valg. Dette vil initialisere verdien til objektet mens det opprettes. For å forstå dette konseptet bedre, vurder følgende eksempel:
Eksempel:
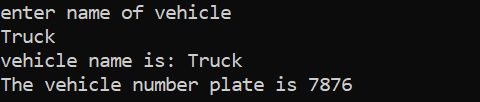
I dette tilfellet vil vi lage en konstruktør av klassen og deklarere parametere.
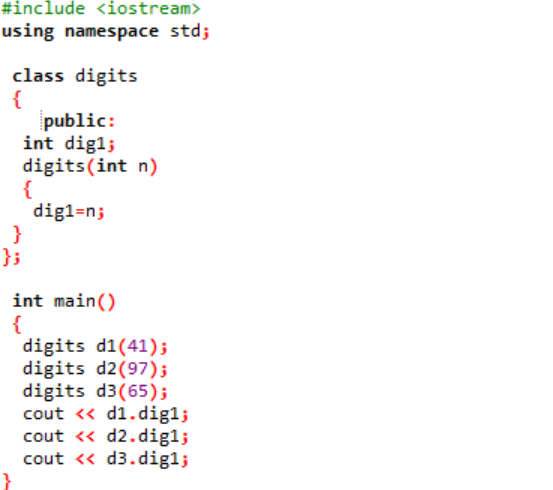
Vi inkluderer overskriftsfilen i det aller første trinnet. Det neste trinnet med å bruke et navneområde er å støtte kataloger til programmet. En klasse som heter 'siffer' er deklarert hvor først variablene initialiseres offentlig slik at de kan være tilgjengelige gjennom hele programmet. En variabel kalt 'dig1' med datatype heltall er deklarert. Deretter har vi erklært en konstruktør hvis navn ligner på navnet på klassen. Denne konstruktøren har en heltallsvariabel sendt til den som 'n' og klassevariabelen 'dig1' er satt lik n. I hoved() funksjonen til programmet opprettes tre objekter for klassen 'siffer' og tildeles noen tilfeldige verdier. Disse objektene blir deretter brukt til å kalle ut klassevariablene som automatisk er tildelt de samme verdiene.
Heltallsverdiene vises på skjermen som utdata.

Kopi konstruktør:
Det er typen konstruktør som vurderer objektene som argumentene og dupliserer verdiene til datamedlemmene til ett objekt til det andre. Derfor brukes disse konstruktørene til å deklarere og initialisere ett objekt fra det andre. Denne prosessen kalles kopiinitialisering.
Eksempel:
I dette tilfellet vil kopikonstruktøren bli erklært.

Først integrerer vi biblioteket og katalogen. En klasse kalt 'Ny' er deklarert der heltallene initialiseres som 'e' og 'o'. Konstruktøren gjøres offentlig der de to variablene blir tildelt verdiene og disse variablene er deklarert i klassen. Deretter vises disse verdiene ved hjelp av hoved() funksjon med 'int' som returtype. De vise() funksjon kalles og defineres etterpå der tallene vises på skjermen. Inne i hoved() funksjon, objektene lages og disse tilordnede objektene initialiseres med tilfeldige verdier og deretter vise() metoden benyttes.
Utdataene mottatt ved bruk av kopikonstruktøren er avslørt nedenfor.

Ødeleggere:
Som navnet definerer brukes destruktorene til å ødelegge de opprettede objektene av konstruktøren. Sammenlignet med konstruktørene har destruktorene det samme navnet som klassen, men med en ekstra tilde (~) fulgt.
Syntaks:
~Ny ( ){
}
Destruktoren tar ikke inn noen argumenter og har ikke engang noen returverdi. Kompilatoren appellerer implisitt utgangen fra programmet for oppryddingslagring som ikke lenger er tilgjengelig.
Eksempel:
I dette scenariet bruker vi en destruktor for å slette et objekt.
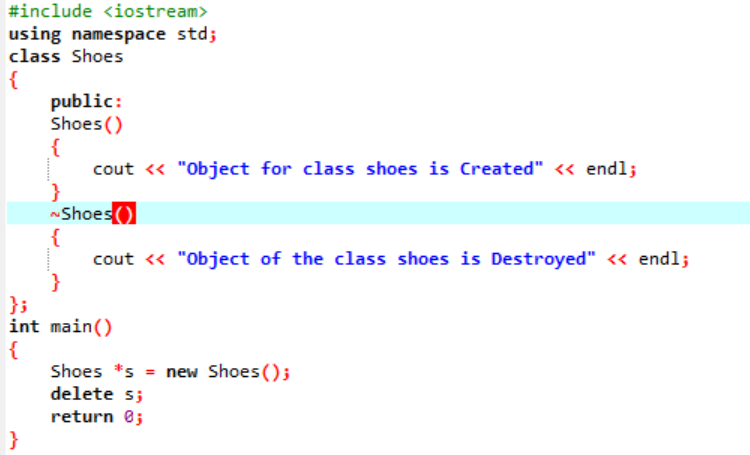
Her lages en 'Sko'-time. Det opprettes en konstruktør som har et lignende navn som klassen. I konstruktøren vises en melding der objektet er opprettet. Etter konstruktøren lages destruktoren som sletter objektene som er opprettet med konstruktøren. I hoved() funksjon, opprettes et pekerobjekt kalt 's' og et nøkkelord 'delete' brukes for å slette dette objektet.

Dette er utdataene vi mottok fra programmet der destruktoren rydder og ødelegger det opprettede objektet.
Forskjellen mellom konstruktører og destruktorer:
| Konstruktører | ødeleggere |
| Oppretter forekomsten av klassen. | Ødelegger forekomsten av klassen. |
| Den har argumenter langs klassenavnet. | Den har ingen argumenter eller parametere |
| Kalles når objektet er opprettet. | Ringes når gjenstanden er ødelagt. |
| Tildeler minnet til objekter. | Deallokerer minnet til objekter. |
| Kan overbelastes. | Kan ikke overbelastes. |
C++ arv:
Nå skal vi lære om C++-arv og dens omfang.
Arv er metoden der en ny klasse genereres eller stammer fra en eksisterende klasse. Den nåværende klassen betegnes som en 'grunnklasse' eller også en 'overordnet klasse', og den nye klassen som opprettes betegnes som en 'avledet klasse'. Når vi sier at en barneklasse er arvet fra en foreldreklasse betyr det at barnet besitter alle egenskapene til foreldreklassen.
Arv refererer til et (er et) forhold. Vi kaller ethvert forhold en arv hvis 'er-a' brukes mellom to klasser.
For eksempel:
- En papegøye er en fugl.
- En datamaskin er en maskin.
Syntaks:
I C++-programmering bruker eller skriver vi arv som følger:
klasse < avledet - klasse >: < adgang - spesifiser >< utgangspunkt - klasse >Modi for C++-arv:
Arv involverer 3 moduser for å arve klasser:
- Offentlig: I denne modusen, hvis en underordnet klasse er deklarert, arves medlemmer av en overordnet klasse av underklassen som de samme i en overordnet klasse.
- Beskyttet: I I denne modusen blir de offentlige medlemmene i foreldreklassen beskyttede medlemmer i barneklassen.
- Privat : I denne modusen blir alle medlemmene i en overordnet klasse private i barneklassen.
Typer C++ arv:
Følgende er typene C++-arv:
1. Enkeltarv:
Med denne typen arv stammer klasser fra én basisklasse.
Syntaks:
klasse M{
Kropp
} ;
klasse N : offentlig M
{
Kropp
} ;
2. Multippel arv:
I denne typen arv kan en klasse stamme fra forskjellige basisklasser.
Syntaks:
klasse M{
Kropp
} ;
klasse N
{
Kropp
} ;
klasse O : offentlig M , offentlig N
{
Kropp
} ;
3. Flernivåarv:
En barneklasse stammer fra en annen barneklasse i denne formen for arv.
Syntaks:
klasse M{
Kropp
} ;
klasse N : offentlig M
{
Kropp
} ;
klasse O : offentlig N
{
Kropp
} ;
4. Hierarkisk arv:
Flere underklasser opprettes fra én basisklasse i denne arvemetoden.
Syntaks:
klasse M{
Kropp
} ;
klasse N : offentlig M
{
Kropp
} ;
klasse O : offentlig M
{
} ;
5. Hybrid arv:
I denne typen arv kombineres flere arv.
Syntaks:
klasse M{
Kropp
} ;
klasse N : offentlig M
{
Kropp
} ;
klasse O
{
Kropp
} ;
klasse P : offentlig N , offentlig O
{
Kropp
} ;
Eksempel:
Vi skal kjøre koden for å demonstrere konseptet Multiple Inheritance i C++-programmering.
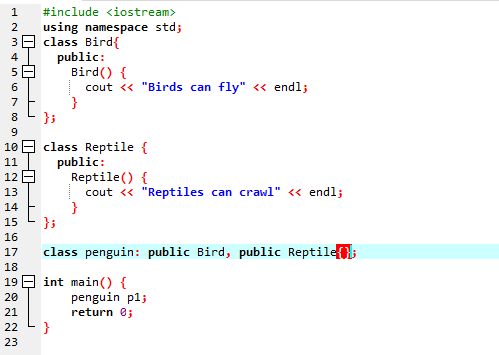
Ettersom vi har startet med et standard input-output-bibliotek, har vi gitt baseklassenavnet 'Bird' og gjort det offentlig slik at medlemmene kan være tilgjengelige. Deretter har vi baseklassen 'Reptile', og vi har også gjort den offentlig. Deretter har vi 'cout' for å skrive ut utdataene. Etter dette skapte vi en 'pingvin' i barneklassen. I hoved() funksjon vi har laget objektet til klassen pingvin 'p1'. Først vil 'Bird'-klassen utføres og deretter 'Reptile'-klassen.
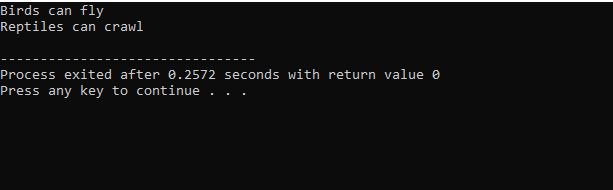
Etter utførelse av kode i C++ får vi utgangssetningene til basisklassene 'Bird' og 'Reptile'. Det betyr at en klasse 'pingvin' er avledet fra basisklassene 'Fugl' og 'Reptil' fordi en pingvin er en fugl så vel som et reptil. Den kan fly så vel som krype. Derfor beviste flere arv at en barneklasse kan avledes fra mange basisklasser.
Eksempel:
Her vil vi kjøre et program for å vise hvordan man bruker Multilevel Inheritance.
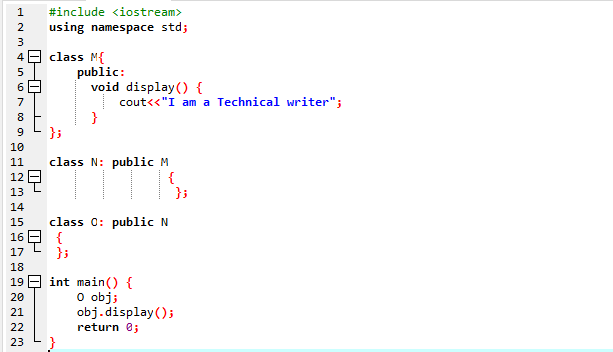
Vi startet programmet vårt ved å bruke input-output-strømmer. Deretter har vi erklært en overordnet klasse 'M' som er satt til å være offentlig. Vi har ringt til vise() funksjon og 'cout'-kommandoen for å vise uttalelsen. Deretter har vi opprettet en barneklasse 'N' som er avledet fra foreldreklassen 'M'. Vi har en ny barneklasse 'O' avledet fra barneklasse 'N' og brødteksten til begge avledede klassene er tom. Til slutt påkaller vi hoved() funksjon der vi må initialisere objektet til klassen 'O'. De vise() funksjonen til objektet brukes for å demonstrere resultatet.
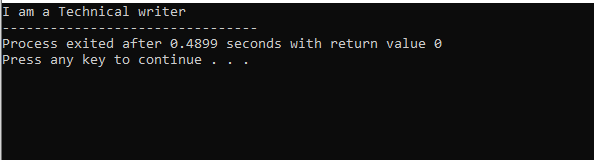
I denne figuren har vi resultatet av klassen 'M' som er foreldreklassen fordi vi hadde en vise() funksjon i den. Så, klasse 'N' er avledet fra overordnet klasse 'M' og klasse 'O' fra overordnet klasse 'N' som refererer til flernivåarven.
C++ polymorfisme:
Begrepet 'polymorfisme' representerer en samling av to ord 'poly' og ' morfisme' . Ordet 'Poly' representerer 'mange' og 'morfisme' representerer 'former'. Polymorfisme betyr at et objekt kan oppføre seg forskjellig under forskjellige forhold. Det lar en programmerer gjenbruke og utvide koden. Den samme koden fungerer forskjellig i henhold til tilstanden. Enactment av et objekt kan brukes på kjøretid.
Kategorier av polymorfisme:
Polymorfisme forekommer hovedsakelig i to metoder:
- Kompiler tidspolymorfisme
- Run Time Polymorphism
La oss forklare.
6. Kompiler tidspolymorfisme:
I løpet av denne tiden endres det angitte programmet til et kjørbart program. Før distribusjon av koden oppdages feilene. Det er først og fremst to kategorier av det.
- Funksjon Overbelastning
- Operatør overbelastning
La oss se på hvordan vi bruker disse to kategoriene.
7. Funksjonsoverbelastning:
Det betyr at en funksjon kan utføre forskjellige oppgaver. Funksjonene er kjent som overbelastet når det er flere funksjoner med et lignende navn, men forskjellige argumenter.
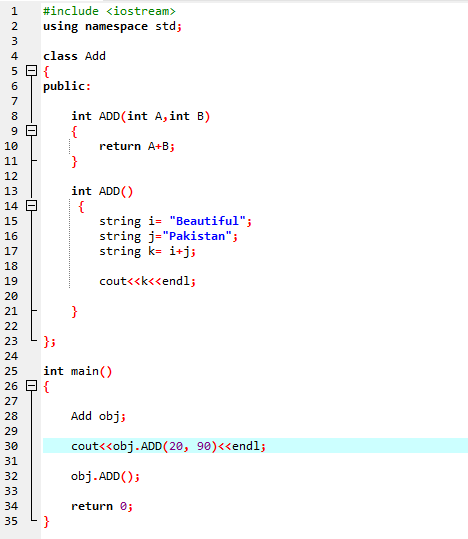
Først bruker vi biblioteket
Operatør overbelastning:
Prosessen med å definere flere funksjoner til en operatør kalles operatøroverbelastning.
Eksempelet ovenfor inkluderer overskriftsfilen
8. Kjøretidspolymorfisme:
Det er tidsrommet koden kjøres i. Etter bruk av koden kan feil oppdages.
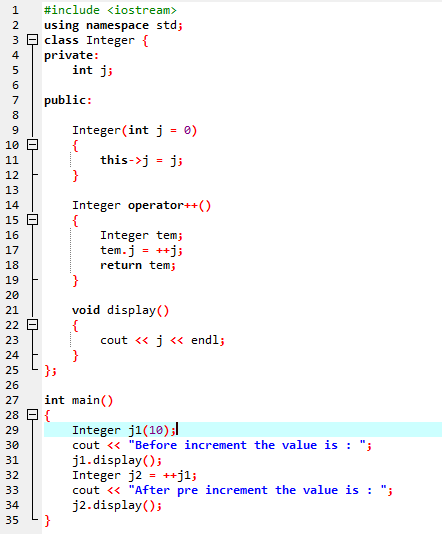
Funksjonsoverstyring:
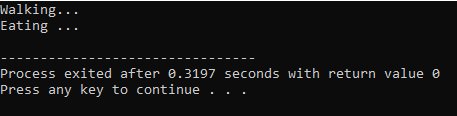
Det skjer når en avledet klasse bruker en lignende funksjonsdefinisjon som en av basisklassemedlemsfunksjonene.
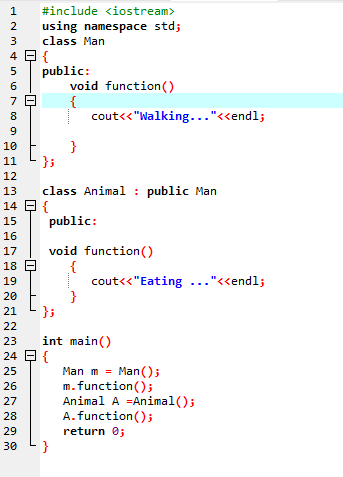
I den første linjen inkorporerer vi biblioteket
C++-strenger:
Nå vil vi finne ut hvordan du deklarerer og initialiserer strengen i C++. Strengen brukes til å lagre en gruppe tegn i programmet. Den lagrer alfabetiske verdier, sifre og spesielle typesymboler i programmet. Den reserverte tegn som en matrise i C++-programmet. Matriser brukes til å reservere en samling eller kombinasjon av tegn i C++-programmering. Et spesielt symbol kjent som et nulltegn brukes til å avslutte matrisen. Den er representert av escape-sekvensen (\0) og den brukes til å spesifisere slutten av strengen.
Få strengen ved å bruke 'cin'-kommandoen:
Den brukes til å legge inn en strengvariabel uten tomrom i den. I det gitte tilfellet implementerer vi et C++-program som får navnet på brukeren ved å bruke 'cin'-kommandoen.
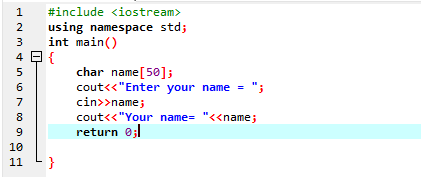
I det første trinnet bruker vi biblioteket
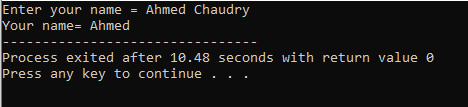
Brukeren skriver inn navnet 'Ahmed Chaudry'. Men vi får bare 'Ahmed' som utgang i stedet for hele 'Ahmed Chaudry' fordi 'cin'-kommandoen ikke kan lagre en streng med tomrom. Den lagrer bare verdien før mellomrom.
Hent strengen ved å bruke funksjonen cin.get():
De få() funksjonen til cin-kommandoen brukes til å hente strengen fra tastaturet som kan inneholde mellomrom.
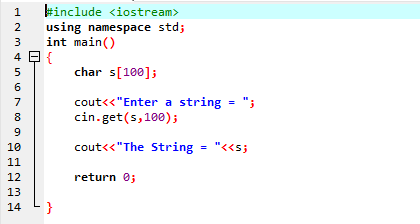
Eksemplet ovenfor inkluderer biblioteket
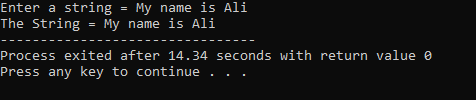
En streng 'Mitt navn er Ali' legges inn av brukeren. Vi får den komplette strengen 'Mitt navn er Ali' som utfall fordi cin.get()-funksjonen aksepterer strengene som inneholder de tomme mellomrommene.
Bruke 2D (to-dimensjonal) rekke av strenger:
I dette tilfellet tar vi input (navn på tre byer) fra brukeren ved å bruke en 2D-array med strenger.
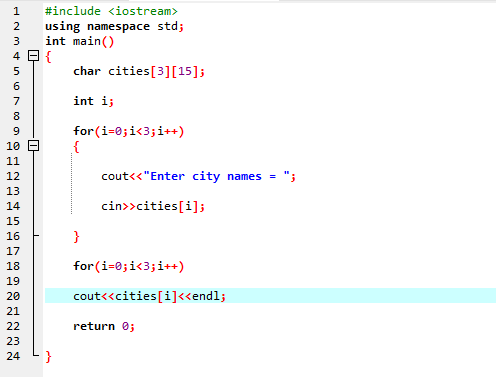
Først integrerer vi overskriftsfilen
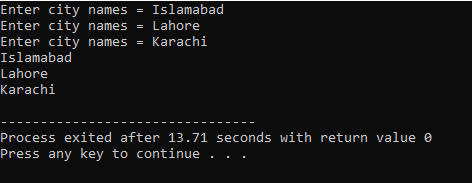
Her skriver brukeren inn navnet på tre forskjellige byer. Programmet bruker en radindeks for å få tre strengverdier. Hver verdi beholdes i sin egen rad. Den første strengen lagres i den første raden og så videre. Hver strengverdi vises på samme måte ved å bruke radindeksen.
C++ Standardbibliotek:
C++-biblioteket er en klynge eller en gruppering av mange funksjoner, klasser, konstanter og alle de relaterte elementene innelukket i ett riktig sett, nesten, alltid som definerer og erklærer de standardiserte overskriftsfilene. Implementeringen av disse inkluderer to nye overskriftsfiler som ikke kreves av C++-standarden kalt
Standardbiblioteket fjerner stresset med å skrive om instruksjonene mens du programmerer. Dette har mange biblioteker inni seg som har lagret kode for mange funksjoner. For å gjøre god bruk av disse bibliotekene er det obligatorisk å koble dem ved hjelp av header-filer. Når vi importerer inngangs- eller utdatabiblioteket, betyr dette at vi importerer all koden som er lagret i det biblioteket, og det er slik vi kan bruke funksjonene som er vedlagt det også ved å skjule all den underliggende koden som du kanskje ikke trenger å se.
C++ standardbiblioteket støtter følgende to typer:
- En vertsimplementering som sørger for alle de essensielle standardbibliotektopptekstfilene beskrevet av C++ ISO-standarden.
- En frittstående implementering som bare krever en del av overskriftsfilene fra standardbiblioteket. Det passende undersettet er:
| Atomic_signed_lock_free og atomic-unsigned_lock_free) |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
| |
| |
|
|
Noen få av overskriftsfilene har blitt beklaget siden de siste 11 C++ kom: Det er
Forskjellene mellom de vertsbaserte og frittstående implementeringene er som illustrert nedenfor:
- I den vertsbaserte implementeringen må vi bruke en global funksjon som er hovedfunksjonen. Mens i en frittstående implementering, kan brukeren deklarere og definere start- og sluttfunksjoner på egen hånd.
- En vertsimplementering har en obligatorisk tråd som kjører på matchtidspunktet. Mens, i den frittstående implementeringen, vil implementerne selv bestemme om de trenger den samtidige trådens støtte i biblioteket deres.
Typer:
Både den frittstående og den hostede støttes av C++. Overskriftsfilene er delt inn i følgende to:
- Iostream deler
- C++ STL-deler (Standard Library)
Når vi skriver et program for kjøring i C++, kaller vi alltid funksjonene som allerede er implementert inne i STL. Disse kjente funksjonene tar inn input og viser utdata ved å bruke identifiserte operatører med effektivitet.
Med tanke på historien ble STL opprinnelig kalt Standard Template Library. Deretter ble delene av STL-biblioteket standardisert i Standard Library of C++ som brukes i dag. Disse inkluderer ISO C++ runtime-biblioteket og noen få fragmenter fra Boost-biblioteket, inkludert noen annen viktig funksjonalitet. Noen ganger betegner STL beholderne eller oftere algoritmene til C++ Standard Library. Nå snakker dette STL eller Standard Template Library helt om det kjente C++ Standard Library.
Std-navneområdet og topptekstfilene:
Alle erklæringer av funksjoner eller variabler gjøres i standardbiblioteket ved hjelp av overskriftsfiler som er jevnt fordelt mellom dem. Erklæringen vil ikke skje med mindre du ikke inkluderer overskriftsfilene.
La oss anta at noen bruker lister og strenger, han må legge til følgende overskriftsfiler:
#inkluder#inkluder
Disse vinkelparentesene «<>» betyr at man må slå opp denne spesielle overskriftsfilen i katalogen som defineres og inkluderes. Man kan også legge til en '.h'-utvidelse til dette biblioteket som gjøres om nødvendig eller ønskelig. Hvis vi ekskluderer '.h'-biblioteket, trenger vi et tillegg 'c' rett før starten av navnet på filen, bare som en indikasjon på at denne overskriftsfilen tilhører et C-bibliotek. For eksempel kan du enten skrive (#include
Når vi snakker om navneområdet, ligger hele C++ standardbiblioteket inne i dette navnerommet betegnet som std. Dette er grunnen til at de standardiserte biblioteknavnene må være kompetent definert av brukerne. For eksempel:
Std :: cout << «Dette skal gå over !/ n' ;C++-vektorer:
Det er mange måter å lagre data eller verdier på i C++. Men foreløpig ser vi etter den enkleste og mest fleksible måten å lagre verdiene på mens du skriver programmene i C++-språket. Så vektorer er beholdere som er riktig sekvensert i et seriemønster hvis størrelse varierer på utførelsestidspunktet avhengig av innsetting og fradrag av elementene. Dette betyr at programmereren kan endre størrelsen på vektoren i henhold til hans ønske under utførelsen av programmet. De ligner arrayene på en slik måte at de også har kommuniserbare lagringsposisjoner for de inkluderte elementene. For å sjekke antall verdier eller elementer som er tilstede inne i vektorene, må vi bruke en ' std::count' funksjon. Vektorer er inkludert i standardmalbiblioteket til C++, så den har en klar overskriftsfil som må inkluderes først, det vil si:
#inkluderErklæring:
Deklarasjonen av en vektor er vist nedenfor.
Std :: vektor < DT > NameOfVector ;Her er vektoren nøkkelordet som brukes, DT viser datatypen til vektoren som kan erstattes med int, float, char eller andre relaterte datatyper. Ovennevnte erklæring kan skrives om som:
Vektor < flyte > Prosentdel ;Størrelsen for vektoren er ikke spesifisert fordi størrelsen kan øke eller reduseres under kjøring.
Initialisering av vektorer:
For initialisering av vektorene er det mer enn én måte i C++.
Teknikk nummer 1:
Vektor < int > v1 = { 71 , 98 , 3. 4 , 65 } ;Vektor < int > v2 = { 71 , 98 , 3. 4 , 65 } ;
I denne prosedyren tildeler vi verdiene direkte for begge vektorene. Verdiene som er tildelt begge er nøyaktig like.
Teknikk nummer 2:
Vektor < int > v3 ( 3 , femten ) ;I denne initialiseringsprosessen dikterer 3 størrelsen på vektoren og 15 er dataene eller verdien som er lagret i den. En vektor av datatype 'int' med den gitte størrelsen 3 som lagrer verdien 15, blir opprettet, noe som betyr at vektoren 'v3' lagrer følgende:
Vektor < int > v3 = { femten , femten , femten } ;Store operasjoner:
De viktigste operasjonene vi skal implementere på vektorene inne i vektorklassen er:
- Legge til en verdi
- Få tilgang til en verdi
- Endre en verdi
- Sletter en verdi
Tilføyelse og sletting:
Addisjon og sletting av elementene inne i vektoren gjøres systematisk. I de fleste tilfeller settes elementer inn ved ferdigstillelsen av vektorbeholderne, men du kan også legge til verdier på ønsket sted som til slutt vil flytte de andre elementene til deres nye plasseringer. Mens i slettingen, når verdiene slettes fra den siste posisjonen, vil det automatisk redusere størrelsen på beholderen. Men når verdiene inne i beholderen slettes tilfeldig fra et bestemt sted, blir de nye plasseringene automatisk tildelt de andre verdiene.
Funksjoner som brukes:
For å endre eller endre verdiene som er lagret inne i vektoren, er det noen forhåndsdefinerte funksjoner kjent som modifikatorer. De er som følger:
- Insert(): Den brukes for å legge til en verdi inne i en vektorbeholder på et bestemt sted.
- Erase(): Den brukes til å fjerne eller slette en verdi inne i en vektorbeholder på et bestemt sted.
- Swap(): Den brukes for swap av verdiene inne i en vektorbeholder som tilhører samme datatype.
- Assign(): Den brukes til å tildele en ny verdi til den tidligere lagrede verdien inne i vektorbeholderen.
- Begin(): Den brukes til å returnere en iterator inne i en løkke som adresserer den første verdien til vektoren inne i det første elementet.
- Clear(): Den brukes til å slette alle verdiene som er lagret i en vektorbeholder.
- Push_back(): Den brukes for å legge til en verdi ved ferdigstillelse av vektorbeholderen.
- Pop_back(): Den brukes til å slette en verdi ved ferdigstillelse av vektorbeholderen.
Eksempel:
I dette eksemplet brukes modifikatorer langs vektorene.
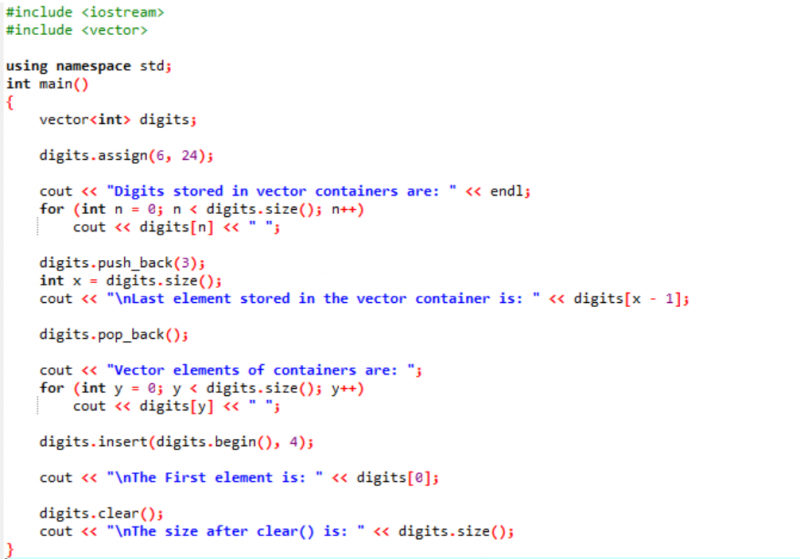
Først inkluderer vi
Utgangen er vist nedenfor.

C++ Files Input Output:
En fil er en samling av innbyrdes relaterte data. I C++ er en fil en sekvens av byte som er samlet i kronologisk rekkefølge. De fleste filene finnes inne på disken. Men også maskinvareenheter som magnetbånd, skrivere og kommunikasjonslinjer er også inkludert i filene.
Inndata og utdata i filer er preget av de tre hovedklassene:
- 'istream'-klassen brukes for å ta innspill.
- Klassen 'ostream' brukes for å vise utdata.
- For input og output, bruk 'iostream'-klassen.
Filer håndteres som strømmer i C++. Når vi tar input og output i en fil eller fra en fil, er følgende klasser som brukes:
- Offstream: Det er en strømklasse som brukes til å skrive til en fil.
- Ifstream: Det er en strømklasse som brukes til å lese innhold fra en fil.
- Strøm: Det er en stream-klasse som brukes til både lesing og skriving i en fil eller fra en fil.
Klassene 'istream' og 'ostream' er forfedrene til alle klassene som er nevnt ovenfor. Filstrømmene er like enkle å bruke som kommandoene 'cin' og 'cout', med bare forskjellen på å knytte disse filstrømmene til andre filer. La oss se et eksempel for å studere kort om 'fstream'-klassen:
Eksempel:
I dette tilfellet skriver vi data i en fil.
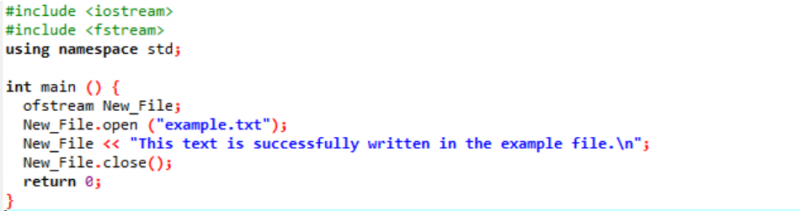
Vi integrerer input- og outputstrømmen i det første trinnet. Header-filen

Fil ‘eksempel’ åpnes fra den personlige datamaskinen og teksten skrevet på filen er trykt inn på denne tekstfilen som vist ovenfor.
Åpne en fil:
Når en fil åpnes, er den representert av en strøm. Et objekt er opprettet for filen som New_File ble opprettet i forrige eksempel. Alle inn- og utdataoperasjonene som er utført på strømmen, blir automatisk brukt på selve filen. For åpning av en fil brukes open()-funksjonen som:
Åpen ( NameOfFile , modus ) ;Her er modusen ikke-obligatorisk.
Lukke en fil:
Når alle inn- og utdataoperasjoner er fullført, må vi lukke filen som ble åpnet for redigering. Vi er pålagt å ansette en Lukk() funksjon i denne situasjonen.
Ny_fil. Lukk ( ) ;Når dette er gjort, blir filen utilgjengelig. Hvis objektet under noen omstendigheter blir ødelagt, selv om det er koblet til filen, vil destruktoren spontant kalle close()-funksjonen.
Tekstfiler:
Tekstfiler brukes til å lagre teksten. Derfor, hvis teksten enten legges inn eller vises, skal den ha noen formateringsendringer. Skriveoperasjonen inne i tekstfilen er den samme som vi utfører 'cout'-kommandoen.
Eksempel:
I dette scenariet skriver vi data i tekstfilen som allerede ble laget i forrige illustrasjon.
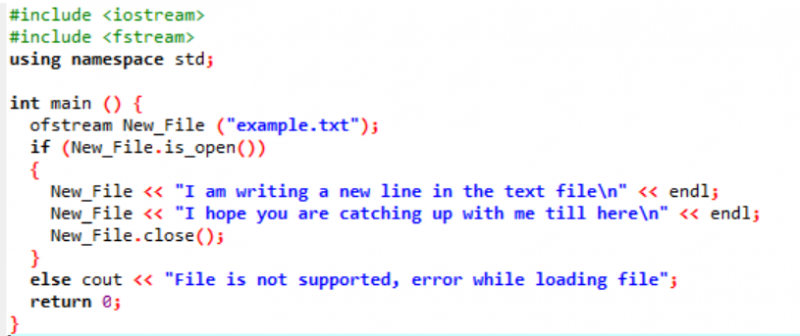
Her skriver vi data i filen som heter 'eksempel' ved å bruke New_File()-funksjonen. Vi åpner filen 'eksempel' ved å bruke åpen() metode. 'Ofstream' brukes til å legge til dataene i filen. Etter å ha utført alt arbeidet inne i filen, lukkes den nødvendige filen ved å bruke Lukk() funksjon. Hvis filen ikke åpnes, vises feilmeldingen 'Fil støttes ikke, feil under lasting av fil'.

Filen åpnes og teksten vises på konsollen.
Lese en tekstfil:
Lesingen av en fil vises ved hjelp av det etterfølgende eksemplet.
Eksempel:
'ifstream' brukes til å lese dataene som er lagret i filen.
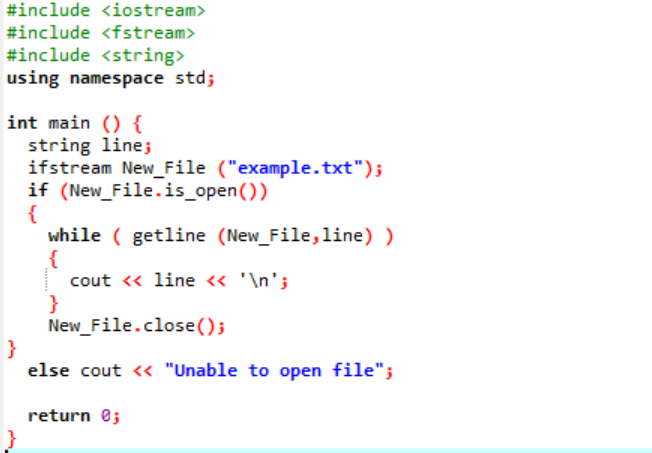
Eksemplet inkluderer hovedhodefilene
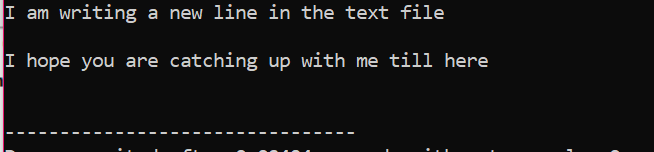
All informasjon som er lagret i tekstfilen vises på skjermen som vist.
Konklusjon
I veiledningen ovenfor har vi lært om C++-språket i detalj. Sammen med eksemplene blir hvert emne demonstrert og forklart, og hver handling er utdypet.