Noen ganger er det gitte datasettet ikke i en enkelt CSV-fil. De er alle på forskjellige Excel-ark. Du vet allerede at det er å foretrekke å utføre alle beregnings- eller forbehandlingsaktiviteter på et enkelt datasett i stedet for flere datasett. Det kutter ned eller sparer tiden vi trenger å bruke på forbehandlingsoppgaver. Som dataanalytiker eller dataforsker kan du også oppleve at du blir overbelastet av en rekke CSV-filer som må slås sammen før du i det hele tatt starter analysen eller undersøkelsen av tilgjengelige data. På den annen side er det ikke alltid mulig at alle filene er hentet fra den samme eller samme datakilden og har samme kolonne/variablenavn og datastruktur. Dette innlegget vil lære deg å kombinere to eller flere CSV-filer med en lignende eller annen kolonnestruktur.
Hvorfor kombinere CSV-filer?
Et datasett kan være en samling eller gruppe av verdier eller tall relatert til et spesifikt emne. For eksempel er hver elevs testresultater i en bestemt klasse et eksempel på et datasett. På grunn av størrelsen på store datasett, blir de ofte lagret i separate CSV-filer for ulike kategorier. For eksempel, hvis vi er pålagt å undersøke en pasient for en spesifikk sykdom, må vi vurdere hver komponent, inkludert deres kjønn, medisinske journal, alder, alvorlighetsgrad av sykdom, osv. Følgelig er det nødvendig å kombinere CSV-data for å undersøke ulike prediktor-påvirkningsfaktorer aspekter. Det er også bedre å arbeide og administrere et enkelt datasett i stedet for flere datasett mens du utfører beregnings- eller forhåndsbehandlingsoppgavene. Det sparer minne og andre beregningsressurser
Hvordan kombinere CSV-filer i Python?
Det er flere måter og metoder for å kombinere to eller flere CSV-filer i Python. I avsnittet nedenfor vil vi bruke funksjonene append(), concat() og merge() osv., for å kombinere CSV-filer til pandas-dataramme, deretter vil datarammer bli konvertert til en enkelt CSV-fil. Vi vil lære hvordan du kombinerer flere CSV-filer med en lignende eller variabel kolonnestruktur.
Metode # 1: Kombinere CSV-er med lignende strukturer eller kolonner
Vår nåværende arbeidskatalog har to CSV-filer, 'test1' og 'test2'.
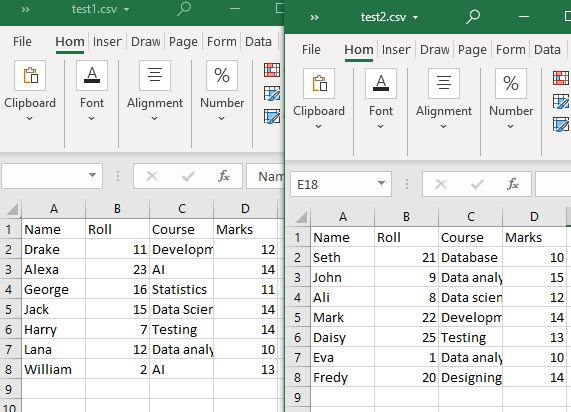
Eksempel # 1: Bruke append()-funksjonen
Begge CSV-filene har samme struktur. Glob()-funksjonen vil bli brukt i denne metoden for kun å liste CSV-filene i arbeidskatalogen. Deretter vil vi bruke 'pandas.DataFrame.append()' for å lese CSV-filene våre (med en felles tabellstruktur).

Produksjon:
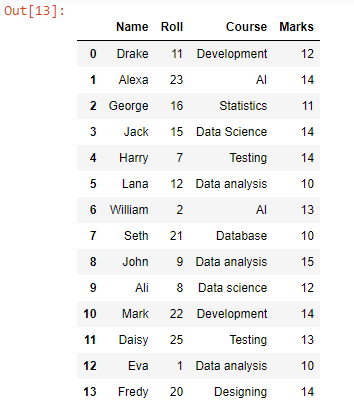
Ved å bruke append-funksjonen har vi lagt til eller lagt til hver datarad fra test2.csv under dataradene til test1.csv, siden det kan ses at alle filens datarader er kombinert. For å konvertere denne datarammen til CSV, kan vi bruke to_csv()-funksjonen.

Dette vil lage en kombinert CSV-fil med CSV-filer av «test1» og «test2» i arbeidskatalogen vår med det angitte navnet, dvs. merged.csv.
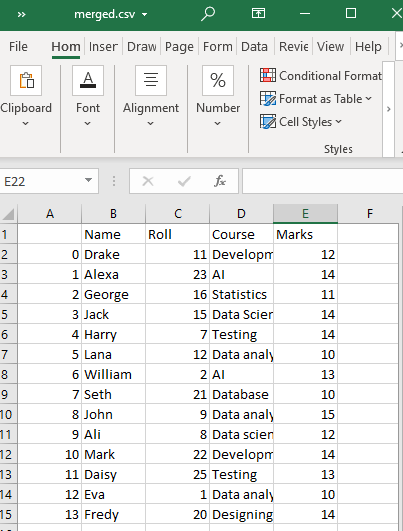
Eksempel # 2: Bruke concat()-funksjonen
Vi vil importere pandamodulen først. Kartmetoden vil lese hver CSV-fil vi har sendt ved hjelp av pd.read_csv(). Disse kartlagte filene (CSV-filer) vil deretter bli kombinert langs radaksen som standard ved å bruke funksjonen pd.concat(). Hvis vi ønsker å kombinere CSV-filer horisontalt, kan vi sende akse=1. Hvis du spesifiserer ignore index = True, opprettes også kontinuerlige indeksverdier for den kombinerte datarammen.

pd.read_csv() sendes inne i concat()-funksjonen for å lese CSV-filene inn i pandas-datarammen etter sammenkobling.
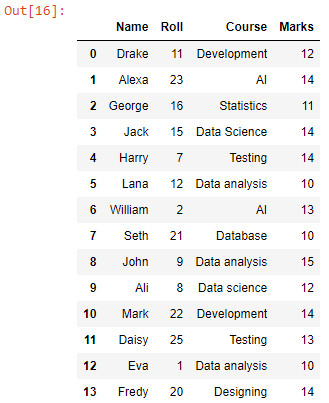
Vi har fått en dataramme med kombinerte data for alle CSV-filer i arbeidskatalogen. La oss nå konvertere den til en CSV-fil.
Vår kombinerte CSV er opprettet i gjeldende katalog.
Metode #2: Kombinere CSV-er med forskjellige strukturer eller kolonner
Vi diskuterte å kombinere CSV-filer med samme kolonner og struktur i den første metoden. I denne metoden vil vi kombinere CSV-filer med forskjellige kolonner og strukturer.
Eksempel # 1: Bruke merge()-funksjonen
«pandas.merge()»-funksjonen i pandas-modulen kan kombinere to CSV-filer. Sammenslåing refererer ganske enkelt til å kombinere to datasett til et enkelt datasett basert på delte kolonner eller attributter.
Vi kan slå sammen datarammer på fire forskjellige måter å bli med på:
- Indre
- Ikke sant
- Venstre
- Ytre
For å utføre disse typene sammenslåinger, bruker vi to CSV-filer.
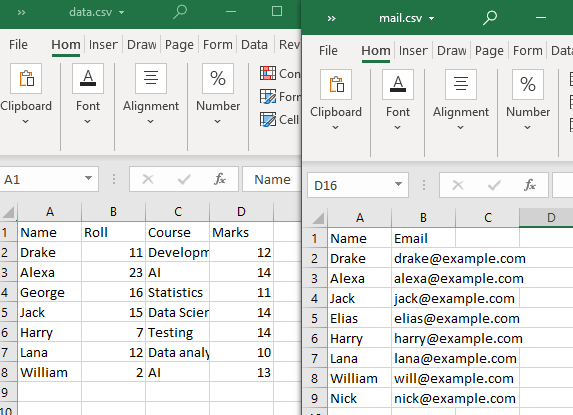
Merk at minst ett attributt eller kolonne må deles av begge CSV-filene. Som observert er kolonnen 'Navn' og noen av dens attributter delt av begge CSV-filene.
Slå sammen med Inner Join
Ved å spesifisere parameteren how=’inner’ i merge()-funksjonen vil de to datarammene kombineres i henhold til den spesifiserte kolonnen og deretter gi en ny dataramme som bare inneholder radene med identiske/samme verdier i begge originale datarammene.
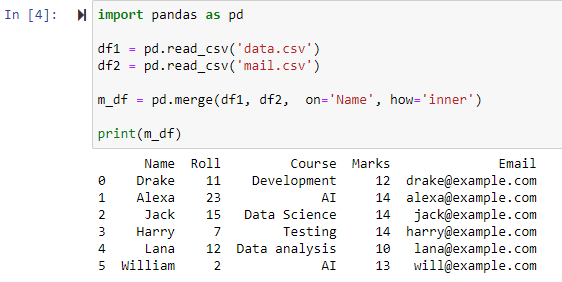
Som det kan sees at funksjonen har slått sammen begge CSV-filene og returnert radene basert på vanlige attributter til kolonnen 'Navn'.
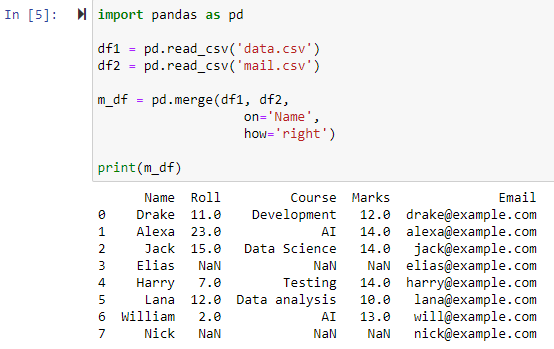
Slå sammen med høyre ytre sammenføyning
Når parameteren how=’right’ er spesifisert, vil begge datarammene bli kombinert basert på kolonnen vi spesifiserte for parameteren ‘on’. Og en ny dataramme som inneholder alle radene fra høyre dataramme, inkludert alle rader som venstre dataramme ikke inneholder verdier for, vil bli returnert, med venstre datarammes kolonneverdi satt til NAN.
Slå sammen med venstre ytre sammenføyning
Når hvordan parameteren er spesifisert som «venstre», vil de to datarammene kombineres basert på den spesifiserte kolonnen ved å bruke «på»-parameteren, og returnere en ny dataramme som har alle radene fra den venstre datarammen, så vel som alle rader som har NAN eller nullverdier i høyre dataramme og setter høyre datarammekolonneverdi til NAN.
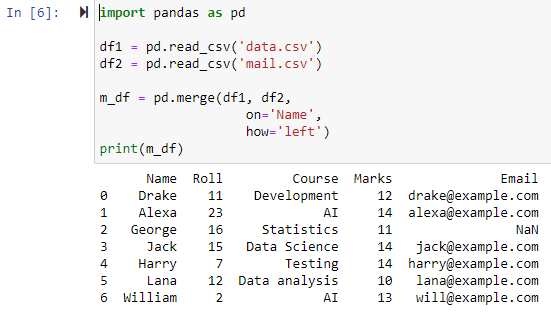
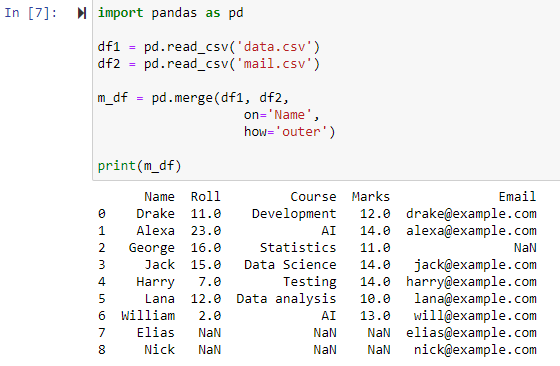
Slå sammen ved å bruke Full Outer Join
Når how='outer' er spesifisert, kombineres de to datarammene avhengig av kolonnen som er spesifisert for parameteren 'on', og returnerer en ny dataramme som inneholder radene fra både df1- og df2-datarammer og setter NAN som verdien for alle rader for hvilke data mangler i en av datarammene.
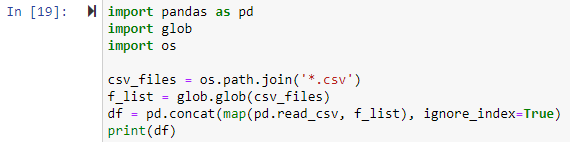
Eksempel # 2: Kombinere alle CSV-filer i arbeidskatalogen
I denne metoden bruker vi glob-modulen til å kombinere alle .csv-filer til en pandas DataFrame. Alle biblioteker måtte importeres først. Deretter vil vi sette en bane for hver CSV-fil vi ønsker å kombinere. Filbanen er det første argumentet for os.path.join()-funksjonen i eksemplet nedenfor, og det andre argumentet er enten banekomponentene eller .csv-filene som skal slås sammen. Her vil uttrykket «*.csv» finne og returnere hver fil i arbeidskatalogen som slutter med .csv-filutvidelsen. Glob.glob(files joined)-funksjonen godtar en liste over navnene på de sammenslåtte filene som input og sender ut en liste over alle sammenslåtte/kombinerte filer.
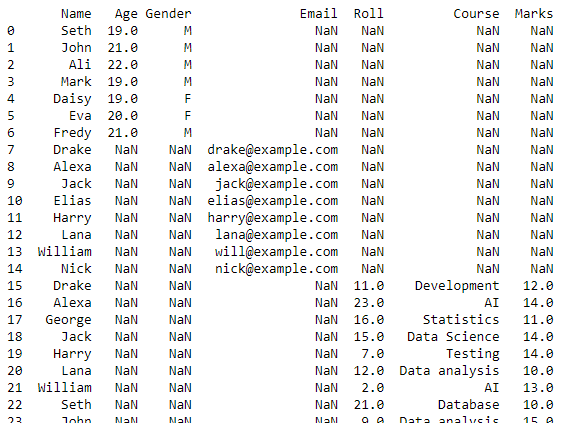
Dette skriptet vil returnere en dataramme med kombinerte data for alle CSV-filene i arbeidskatalogen vår.
Denne datarammen vil bli transformert til en CSV-fil, og to_csv()-funksjonen vil bli brukt for denne konverteringen. Denne nye CSV-filen vil være de kombinerte CSV-filene som er opprettet fra alle CSV-filene som er lagret i gjeldende arbeidskatalog.
Konklusjon
I dette innlegget diskuterte vi hvorfor vi trenger å kombinere CSV-filer. Vi diskuterte hvordan to eller flere CSV-filer kan kombineres i Python. Vi delte denne opplæringen i to deler. I den første delen forklarte vi hvordan du bruker funksjonene append() og concat() for å kombinere CSV-filer med samme struktur eller kolonnenavn. I den andre delen brukte vi merge()-metoden, os.path.join(), og glob-metoden for å kombinere CSV-filer med forskjellige kolonner og strukturer.