Eksempel 1: Få posisjonen til mønsteret fra strengen ved å bruke Grep()-funksjonen i R
For å trekke ut posisjonen til det spesifiserte mønsteret fra strengen, brukes grep()-funksjonen til R.
grep('i+', c('fix', 'split', 'mais n', 'maling'), perl=TRUE, value=FALSE)Her bruker vi grep()-funksjonen der '+i'-mønsteret er spesifisert som et argument som skal matches innenfor vektoren av strenger. Vi setter tegnvektorene som inneholder fire strenger. Etter det setter vi 'perl'-argumentet med TRUE-verdien som indikerer at R bruker et perl-kompatibelt regeluttrykksbibliotek, og 'value'-parameteren er spesifisert med 'FALSE'-verdien som brukes til å hente indeksene til elementene i vektoren som samsvarer med mønsteret.
'+i'-mønsterposisjonen fra hver streng med vektortegn vises i følgende utdata:

Eksempel 2: Match mønsteret ved å bruke Gregexpr()-funksjonen i R
Deretter henter vi indeksposisjonen sammen med lengden på den bestemte strengen i R ved å bruke gregexpr()-funksjonen.
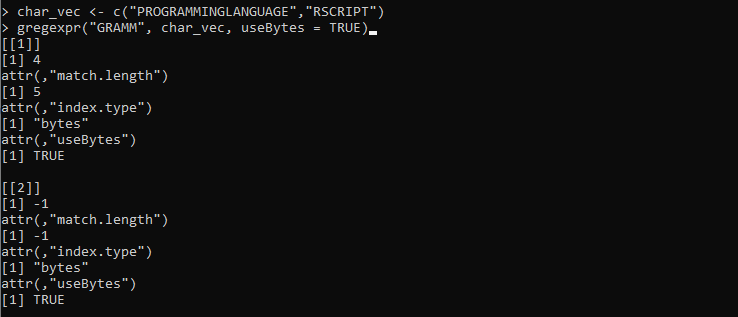
char_vec <- c('PROGRAMMINGLANGUAGE','RSCRIPT')
gregexpr('GRAMM', char_vec, useBytes = TRUE)
Her setter vi 'char_vect'-variabelen der strengene er utstyrt med forskjellige tegn. Etter det definerer vi gregexpr()-funksjonen som tar 'GRAMM'-strengmønsteret til å bli matchet med strengene som er lagret i 'char_vec'. Deretter setter vi useBytes-parameteren med 'TRUE'-verdien. Denne parameteren indikerer at samsvaret bør oppnås byte-for-byte i stedet for tegn-for-tegn.
Følgende utdata som hentes fra gregexpr()-funksjonen representerer indeksene og lengden på begge vektorstrengene:
Eksempel 3: Tell totalt antall tegn i streng ved å bruke Nchar()-funksjonen i R
Metoden nchar() som vi implementerer i det følgende lar oss også bestemme hvor mange tegn som er i strengen:
Res <- nchar('Tell hvert tegn')print(res)
Her kaller vi nchar()-metoden som er satt i 'Res'-variabelen. nchar()-metoden er utstyrt med den lange strengen av tegn som telles av nchar()-metoden og gir antall tellertegn i den angitte strengen. Deretter sender vi 'Res'-variabelen til print()-metoden for å se resultatene av nchar()-metoden.
Resultatet mottas i følgende utgang som viser at den angitte strengen inneholder 20 tegn:

Eksempel 4: Trekk ut delstrengen fra strengen ved å bruke Substring()-funksjonen i R
Vi bruker substring()-metoden med 'start' og 'stopp'-argumentene for å trekke ut den spesifikke understrengen fra strengen.
str <- substring('MORNING', 2, 4)print(str)
Her har vi en 'str'-variabel der substring()-metoden kalles opp. Substring()-metoden tar 'MORNING'-strengen som det første argumentet og verdien av '2' som det andre argumentet som indikerer at det andre tegnet fra strengen skal trekkes ut, og verdien av '4'-argumentet indikerer at det fjerde tegnet skal trekkes ut. Substring()-metoden trekker ut tegnene fra strengen mellom den angitte posisjonen.
Følgende utgang viser den utpakkede delstrengen som ligger mellom den andre og den fjerde posisjonen i strengen:

Eksempel 5: Sammenknytt strengen ved å bruke Paste()-funksjonen i R
Paste()-funksjonen i R brukes også for strengmanipulasjon som sammenkobler de spesifiserte strengene ved å skille skilletegnene.
msg1 <- 'Innhold'msg2 <- 'Skriver'
lim inn(msg1, msg2)
Her spesifiserer vi strengene til henholdsvis 'msg1' og 'msg2' variablene. Deretter bruker vi paste()-metoden til R for å sette sammen den angitte strengen til en enkelt streng. Paste()-metoden tar strengvariabelen som et argument og returnerer enkeltstrengen med standardmellomrommet mellom strengene.
Ved kjøring av paste()-metoden, representerer utdata den enkelt strengen med mellomrommet i den.

Eksempel 6: Endre strengen ved å bruke Substring()-funksjonen i R
Videre kan vi også oppdatere strengen ved å legge til understrengen eller et hvilket som helst tegn i strengen ved å bruke substring()-funksjonen ved å bruke følgende skript:
str1 <- 'Helter'substring(str1, 5, 6) <- 'ic'
cat(' Modified String:', str1)
Vi setter 'Heroes' -strengen i 'str1' -variabelen. Deretter distribuerer vi substring()-metoden der 'str1' er spesifisert sammen med understrengens 'start' og 'stop' indeksverdier. Substring()-metoden er tilordnet 'iz'-delstrengen som er plassert på posisjonen som er spesifisert i funksjonen for den gitte strengen. Etter det bruker vi cat() funksjonen til R som representerer den oppdaterte strengverdien.
Utdataene som viser strengen oppdateres med den nye ved å bruke substring ()-metoden:

Eksempel 7: Formater strengen ved å bruke Format()-funksjonen i R
Imidlertid inkluderer strengmanipuleringsoperasjonen i R også formatering av strengen tilsvarende. For dette bruker vi format()-funksjonen der strengen kan justeres og angi bredden på den spesifikke strengen.
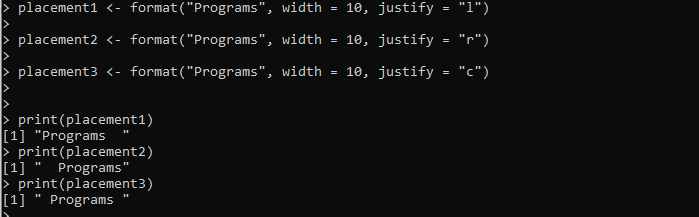
plassering1 <- format('Programmer', width = 10, justify = 'l')plassering2 <- format('Programmer', width = 10, justify = 'r')
plassering3 <- format('Programmer', width = 10, justify = 'c')
print (plassering1)
print (plassering2)
print (plassering3)
Her setter vi 'placement1'-variabelen som er utstyrt med format()-metoden. Vi sender 'programmer'-strengen som skal formateres til format()-metoden. Bredden settes, og justeringen av strengen settes til venstre ved å bruke 'justifiser'-argumentet. På samme måte oppretter vi ytterligere to variabler, 'placement2' og 'placement2', og bruker format()-metoden for å formatere den angitte strengen tilsvarende.
Utdataene viser tre formateringsstiler for den samme strengen i følgende bilde, inkludert venstre-, høyre- og senterjustering:
Eksempel 8: Transformer strengen til små og store bokstaver i R
I tillegg kan vi også transformere strengen med små og store bokstaver ved å bruke funksjonene tolower() og toupper() som følger:
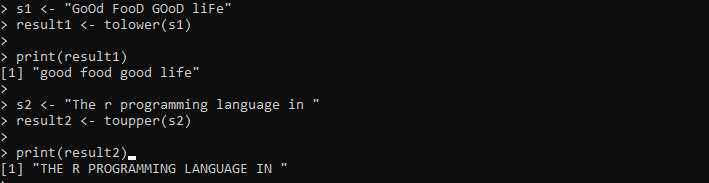
s1 <- 'GOD MAT GODT LIV'resultat1 <- lavere(s1)
print (resultat1)
s2 <- 'Programmeringsspråket r i '
resultat2 <- topp(e2)
print (resultat2)
Her gir vi strengen som inneholder store og små bokstaver. Etter det holdes strengen i 's1'-variabelen. Deretter kaller vi tolower()-metoden og sender 's1'-strengen inni den for å transformere alle tegnene inne i strengen med små bokstaver. Deretter skriver vi ut resultatene av tolower()-metoden som er lagret i 'result1'-variabelen. Deretter setter vi en annen streng i 's2'-variabelen som inneholder alle tegnene med små bokstaver. Vi bruker toupper()-metoden på denne 's2'-strengen for å transformere den eksisterende strengen til store bokstaver.
Utdataene viser begge strengene i det angitte tilfellet i følgende bilde:
Konklusjon
Vi lærte de ulike måtene å administrere og analysere strengene på, som omtales som strengmanipulasjon. Vi hentet ut karakterens posisjon fra strengen, sammenkoblet de forskjellige strengene og forvandlet strengen til det angitte tilfellet. Dessuten formaterte vi strengen, modifiserte strengen, og forskjellige andre operasjoner utføres her for å manipulere strengen.