6.1 Introduksjon
Moderne generelle datamaskiner er av to typer: CISC og RISC. CISC står for Complex Instruction Set Computer. RISK står for Reduced Instruction Set Computer. Mikroprosessorene 6502 eller 6510, som gjelder Commodore-64-datamaskinen, ligner mer på RISC-arkitekturen enn en CISC-arkitektur.
RISC-datamaskiner har generelt kortere monteringsspråkinstruksjoner (etter antall byte) sammenlignet med CISC-datamaskiner.
Merk : Enten du har å gjøre med CISC, RISC eller gammel datamaskin, begynner en perifer enhet fra en intern port og går utover gjennom en ekstern port på den vertikale overflaten av datamaskinens systemenhet (baseenhet) og til den eksterne enheten.
En typisk instruksjon for en CISC-datamaskin kan ses som å slå sammen flere korte assembly-språkinstruksjoner til en en lengre assembly-språkinstruksjon som gjør den resulterende instruksjonen kompleks. Spesielt laster en CISC-datamaskin operandene fra minnet inn i mikroprosessorregistrene, utfører en operasjon og lagrer deretter resultatet tilbake i minnet, alt i én instruksjon. På den annen side er dette minst tre instruksjoner (kort) for RISC-datamaskinen.
Det er to populære serier med CISC-datamaskiner: Intel mikroprosessordatamaskiner og AMD mikroprosessordatamaskiner. AMD står for Advanced Micro Devices; det er et halvlederproduksjonsselskap. Intels mikroprosessorserier, i utviklingsrekkefølge, er 8086, 8088, 80186, 80286, 80386, 80486, Pentium, Core, i Series, Celeron og Xeon. Monteringsspråkinstruksjonene for de tidlige Intel-mikroprosessorene som 8086 og 8088 er ikke veldig komplekse. De er imidlertid komplekse for de nye mikroprosessorene. De siste AMD-mikroprosessorene for CISC-serien er Ryzen, Opteron, Athlon, Turion, Phenom og Sempron. Intel- og AMD-mikroprosessorene er kjent som x86-mikroprosessorene.
ARM står for Advanced RISC Machine. ARM-arkitekturene definerer en familie av RISC-prosessorer som er egnet for bruk i en lang rekke applikasjoner. Mens mange Intel- og AMD-mikroprosessorer brukes i stasjonære personlige datamaskiner, fungerer mange ARM-prosessorer som innebygde prosessorer i sikkerhetskritiske systemer som anti-låsebremser til biler og som generelle prosessorer i smartklokker, bærbare telefoner, nettbrett og bærbare datamaskiner . Selv om begge typer mikroprosessorer kan sees i små og store enheter, finnes RISC-mikroprosessorene mer i små enheter enn i store enheter.
Datamaskin Word
Hvis en datamaskin sies å være en datamaskin med 32 bits ord, betyr det at informasjonen lagres, overføres og manipuleres i form av trettito-bits binære koder i den indre delen av hovedkortet. Det betyr også at de generelle registrene i mikroprosessoren til datamaskinen er 32-bits brede. A-, X- og Y-registrene til 6502-mikroprosessoren er registre for generelle formål. De er åtte-bits brede, og derfor er Commodore-64-datamaskinen en åtte-bits orddatamaskin.
Litt ordforråd
X86 datamaskiner
Betydningen av byte, ord, doubleword, quadword og double-quadword er som følger for x86-datamaskiner:
- Byte : 8 biter
- Ord : 16 biter
- Dobbeltord : 32 biter
- Quadword : 64 biter
- Dobbelt firord : 128 biter
ARM datamaskiner
Betydningen av byte, halvord, ord og dobbeltord er som følger for ARM-datamaskiner:
- Byte : 8 biter
- Bli halvparten : 16 biter
- Ord : 32 biter
- Dobbeltord : 64 biter
Forskjellene og likhetene for x86- og ARM-navnene (og verdiene) bør noteres.
Merk : Heltallene for tegn i begge datamaskintypene er tos komplement.
Minneplassering
Med Commodore-64-datamaskinen er en minneplassering vanligvis én byte, men kan av og til være to påfølgende byte når man vurderer pekerne (indirekte adressering). Med en moderne x86-datamaskin er en minneplassering 16 påfølgende byte når man arbeider med et dobbelt quadword på 16 byte (128 bits), 8 påfølgende byte når man arbeider med quadword på 8 byte (64 bits), 4 påfølgende byte når man arbeider med dobbeltord av 4 byte (32 bits), 2 påfølgende byte når man arbeider med et ord på 2 byte (16 bits), og 1 byte når man arbeider med en byte (8 bits). Med en moderne ARM-datamaskin er en minneplassering 8 påfølgende byte når man arbeider med et dobbeltord på 8 byte (64 biter), 4 påfølgende byte når man arbeider med et ord på 4 byte (32 biter), 2 påfølgende byte når man arbeider med et halvord på 2 byte (16 bits) og 1 byte når det gjelder en byte (8 bits).
Dette kapittelet forklarer hva som er vanlig i CISC- og RISC-arkitekturene og hva deres forskjeller er. Dette gjøres i sammenligning med 6502 µP og commodore-64-datamaskinen der det er aktuelt.
6.2 Hovedkortblokkdiagram for moderne PC
PC står for Personal Computer. Følgende er et generisk grunnleggende blokkskjema for et moderne hovedkort med en enkelt mikroprosessor for en personlig datamaskin. Det representerer et CISC- eller RISC-hovedkort.
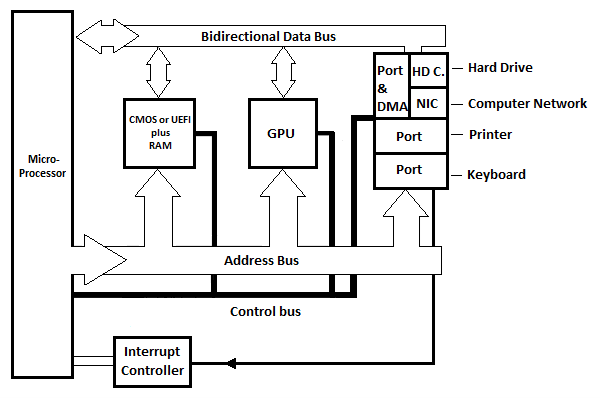
Fig. 6.21 Grunnleggende hovedkortblokkdiagram for moderne PC
Tre interne porter er vist i diagrammet, men det er flere i praksis. Hver port har et register som kan sees på som selve porten. Hver portkrets har minst et annet register som kan kalles et 'statusregister'. Statusregisteret indikerer porten til programmet som sender avbruddssignalet til mikroprosessoren. Det er en avbruddskontrollerkrets (ikke vist) som skiller mellom de forskjellige avbruddslinjene fra de forskjellige portene og har bare noen få linjer til µP.
HD.C i diagrammet står for Hard Drive Card. NIC står for Network Interface Card. Harddiskkortet (kretsen) er koblet til harddisken som er inne i basisenheten (systemenheten) til den moderne datamaskinen. Nettverksgrensesnittkortet (kretsen) er koblet til en annen datamaskin via en ekstern kabel. I diagrammet er det én port og en DMA (se følgende illustrasjon) som er koblet til harddiskkortet og/eller til nettverkskortet. DMA står for Direct Memory Access.
Husk fra datamaskinkapittelet Commodore-64 at for å sende bytene fra minnet til diskstasjonen eller en annen datamaskin, må hver byte kopieres til et register i mikroprosessoren før den kopieres til den tilsvarende interne porten, og deretter automatisk til enheten. For å motta byte fra diskstasjonen eller en annen datamaskin til minnet, må hver byte kopieres fra det tilsvarende interne portregisteret til et mikroprosessorregister før den kopieres til minnet. Dette tar normalt lang tid hvis antallet byte i strømmen er stort. Løsningen for rask overføring er bruk av direkte minnetilgang (krets) uten å gå gjennom mikroprosessoren.
DMA-kretsen er mellom porten og HD. C eller NIC. Med direkte minnetilgang til DMA-kretsen er overføringen av store strømmer av byte direkte mellom DMA-kretsen og minnet (RAM) uten fortsatt deltakelse fra mikroprosessoren. DMA bruker adressebussen og databussen i stedet for µP. Den totale varigheten av overføringen er kortere enn hvis µP hard skal brukes. Både HD C. eller NIC bruker DMA når de har en stor strøm av data (bytes) for overføring med RAM (minnet).
GPU står for Graphics Processing Unit. Denne blokken på hovedkortet er ansvarlig for å sende teksten og de bevegelige eller stillbildene til skjermen.
Med de moderne datamaskinene (PC-er) er det ikke noe Read Only Memory (ROM). Det er imidlertid BIOS eller UEFI som er en slags ikke-flyktig RAM. Informasjonen i BIOS vedlikeholdes faktisk av et batteri. Batteriet er det som faktisk opprettholder klokketimeren også, til riktig tid og dato for datamaskinen. UEFI ble oppfunnet etter BIOS, og har erstattet BIOS, selv om BIOS fortsatt er ganske relevant i moderne PC-er. Vi diskuterer mer om disse senere!
I moderne PC-er er ikke adresse- og databussene mellom µP og de interne portkretsene (og minnet) parallelle busser. De er seriebusser som trenger to ledere for overføring i én retning og ytterligere to ledere for overføring i motsatt retning. Dette betyr for eksempel at 32-biter kan sendes i serie (den ene biten etter den andre) i begge retninger.
Hvis den serielle overføringen bare er i én retning med to ledere (to linjer), sies det å være halv-dupleks. Hvis den serielle overføringen er i begge retninger med fire ledere, ett par i hver retning, sies det å være full-dupleks.
Hele minnet til den moderne datamaskinen består fortsatt av en rekke byteplasseringer: åtte biter per byte. En moderne datamaskin har en minneplass på minst 4 gigabyte = 4 x 210 x 2 10 x 2 10 = 4 x 1 073 741 824 10 byte = 4 x 1024 10/sub> x 1024 10 x 1024 10 = 4 x 1 073 741 824 10 .
Merk : Selv om ingen timerkrets vises på det forrige hovedkortet, har alle moderne hovedkort timerkretser.
6.3 Grunnleggende om x64-datamaskinarkitektur
6.31 x64-registersettet
64-bits mikroprosessoren til x86-serien med mikroprosessorer er en 64-bits mikroprosessor. Det er ganske moderne å erstatte 32-bits prosessoren i samme serie. 64-bits mikroprosessorens generelle registre og navnene deres er som følger:
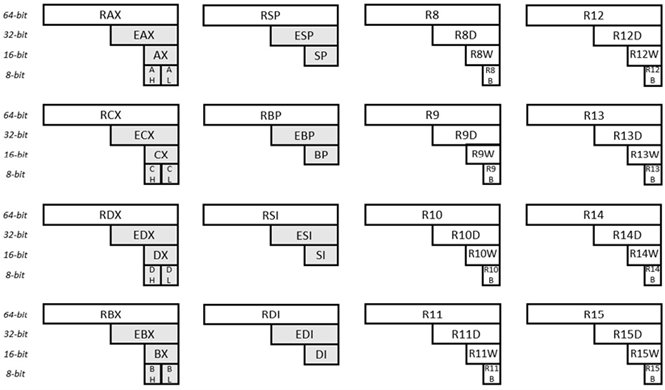
Fig. 6.31 Generelle formålsregistre for x64
Seksten (16) registre for generell bruk er vist i den gitte illustrasjonen. Hvert av disse registerene er 64-biters brede. Ser vi på registeret øverst til venstre, er de 64 bitene identifisert som RAX. De første 32 bitene i det samme registeret (fra høyre) er identifisert som EAX. De første 16 bitene i det samme registeret (fra høyre) er identifisert som AX. Den andre byten (fra høyre) i det samme registeret er identifisert som AH (H betyr her høy). Og den første byten (av dette samme registeret) er identifisert som AL (L her betyr lav). Ser vi på registeret nederst til høyre, er de 64 bitene identifisert som R15. De første 32 bitene i dette samme registeret er identifisert som R15D. De første 16 bitene i det samme registeret er identifisert som R15W. Og den første byten er identifisert som R15B. Navnene på de andre registrene (og underregistrene) er på samme måte forklart.
Det er noen forskjeller mellom Intel og AMD µPs. Informasjonen i denne delen er for Intel.
Med 6502 µP er programtellerregisteret (ikke tilgjengelig direkte) som inneholder den neste instruksjonen som skal utføres 16-bits bredt. Her (x64) kalles programtelleren Instruction Pointer, og den er 64-bits bred. Den er merket som RIP. Dette betyr at x64 µP kan adressere opptil 264 = 1,844674407 x 1019 (faktisk 18,446,744,073,709,551,616) minnebyteplasseringer. RIP er ikke et generell register.
Stack Pointer Register eller RSP er blant de 16 generelle registrene. Den peker på den siste stabeloppføringen i minnet. Som med 6502 µP, vokser stabelen for x64 nedover. Med x64 brukes stabelen i RAM til å lagre returadressene for subrutiner. Den brukes også til å lagre 'skyggerommet' (se følgende diskusjon).
6502 µP har et 8-bits prosessorstatusregister. Ekvivalenten i x64 kalles RFLAGS-registeret. Dette registeret lagrer flaggene som brukes for resultatene av operasjoner og for å kontrollere prosessoren (µP). Den er 64-bits bred. De høyere 32 bitene er reservert og brukes ikke for øyeblikket. Følgende tabell gir navn, indeks og betydning for de vanligste bitene i RFLAGS-registeret:
| Tabell 6.31.1 Mest brukte RFLAGS-flagg (biter) |
|||
|---|---|---|---|
| Symbol | Bit | Navn | Hensikt |
| CF | 0 | Bære | Det settes hvis en aritmetisk operasjon genererer en carry eller et lån ut av den mest signifikante biten av resultatet; ryddet ellers. Dette flagget indikerer en overløpsbetingelse for aritmetikk uten fortegn. Den brukes også i aritmetikk med flere presisjoner. |
| PF | 2 | Paritet | Det settes hvis den minst signifikante byten av resultatet inneholder et partall på 1 bit; ryddet ellers. |
| AV | 4 | Justere | Det settes hvis en aritmetisk operasjon genererer en carry eller et lån ut av bit 3 av resultatet; ryddet ellers. Dette flagget brukes i binærkodet desimal (BCD) aritmetikk. |
| ZF | 6 | Null | Det settes hvis resultatet er null; ryddet ellers. |
| SF | 7 | Skilt | Den settes hvis den er lik den mest signifikante biten av resultatet som er fortegnsbiten til et heltall med fortegn (0 indikerer en positiv verdi og 1 indikerer en negativ verdi). |
| AV | elleve | Flyte | Det settes hvis heltallsresultatet er et for stort positivt tall eller et for lite negativt tall (eksklusive fortegnsbiten) til å passe inn i destinasjonsoperanden; ryddet ellers. Dette flagget indikerer en overløpsbetingelse for regnestykket med fortegnet heltall (to-komplement). |
| DF | 10 | Retning | Den angis om retningsstrenginstruksjonene fungerer (øke eller redusere). |
| ID | tjueen | Identifikasjon | Den angis hvis den kan endres angir tilstedeværelsen av CPUID-instruksjonen. |
I tillegg til de atten 64-bits registrene som tidligere er indikert, har x64-arkitekturen µP åtte 80-bits brede registre for flytende kommaaritmetikk. Disse åtte registrene kan også brukes som MMX-registre (se følgende diskusjon). Det er også seksten 128-biters registre for XMM (se følgende diskusjon).
Det handler ikke bare om registre. Det er flere x64-registre som er segmentregistre (for det meste ubrukt i x64), kontrollregistre, minnestyringsregistre, feilsøkingsregistre, virtualiseringsregistre, ytelsesregistre som sporer alle slags interne parametere (cache-treff/misser, utførte mikrooperasjoner, timing , og mye mer).
SIMD
SIMD står for Single Instruction Multiple Data. Dette betyr at én assemblerspråkinstruksjon kan virke på flere data samtidig i én mikroprosessor. Tenk på følgende tabell:
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
| + | 9 | 10 | elleve | 12 | 1. 3 | 14 | femten | 16 |
| = | 10 | 12 | 14 | 16 | 18 | tjue | 22 | 24 |
I denne tabellen legges åtte tallpar til parallelt (i samme varighet) for å gi åtte svar. Én assembly-språkinstruksjon kan gjøre de åtte parallelle heltallstilleggene i MMX-registrene. En lignende ting kan gjøres med XMM-registrene. Så det er MMX-instruksjoner for heltall og XMM-instruksjoner for flyter.
6.32 Minnekart og x64
Med instruksjonspekeren (programtelleren) som har 64 biter, betyr dette at 264 = 1,844674407 x 1019 minnebyteplasseringer kan adresseres. I heksadesimal er den høyeste byteplasseringen FFFF, FFFF, FFFF, FFFF16. Ingen vanlig datamaskin i dag kan gi så stor (komplett) minneplass. Så et passende minnekart for x64-datamaskinen er som følger:

Legg merke til at gapet fra 0000,8000,0000,000016 til FFFF,7FFF,FFFF,FFFF16 har ingen minneplasseringer (ingen minne RAM-banker). Dette er en forskjell på FFFF,0000,0000,000116 som er ganske stor. Den kanoniske høye halvdelen har operativsystemet, mens den kanoniske lave halvdelen har brukerprogrammene (applikasjonene) og data. Operativsystemet består av to deler: en liten UEFI (BIOS) og en stor del som lastes fra harddisken. Det neste kapittelet snakker mer om de moderne operativsystemene. Legg merke til likheten med dette minnekartet og det for Commodore-64 når 64KB kan ha sett ut som mye minne.
I denne sammenhengen kalles operativsystemet grovt sett 'kjernen'. Kjernen ligner på Kernal til Commodore-64-datamaskinen, men har langt flere subrutiner.
Endianheten for x64 er liten endian, noe som betyr at for en plassering peker den nedre adressen til den lavere innholdsbyten i minnet.
6.33 Assembly Language Addressing Modes for x64
Adresseringsmoduser er måtene en instruksjon kan få tilgang til µP-registrene og minnet (inkludert de interne portregistrene). x64 har mange adresseringsmoduser, men bare de vanlig brukte adresseringsmodusene er adressert her. Den generelle syntaksen for en instruksjon her er:
opcode-destinasjon, kilde
Desimaltallene skrives uten prefiks eller suffiks. Med 6502 er kilden implisitt. x64 har flere op-koder enn 6502, men noen av op-kodene har samme mnemonics. De individuelle x64-instruksjonene har variabel lengde og kan variere i størrelse fra 1 til 15 byte. De vanligste adresseringsmodusene er som følger:
Umiddelbar adresseringsmodus
Her er kildeoperanden en faktisk verdi og ikke en adresse eller etikett. Eksempel (les kommentaren):
ADD EAX, 14 ; legg til desimal 14 til 32-biters EAX av 64-biters RAX, svaret forblir i EAX (destinasjon)
Registrer deg for å registrere adresseringsmodus
Eksempel:
ADD R8B, AL ; legg til 8-bits AL av RAX til R8B av 64-bits R8 – svarene forblir i R8B (destinasjon)
Indirekte og indeksert adresseringsmodus
Indirekte adressering med 6502 µP betyr at plasseringen til den gitte adressen i instruksjonen har den effektive adressen (pekeren) til den endelige plasseringen. En lignende ting skjer med x64. Indeksadressering med 6502 µP betyr at innholdet i et µP-register legges til den gitte adressen i instruksjonen for å ha den effektive adressen. En lignende ting skjer med x64. Med x64 kan innholdet i registeret også multipliseres med 1 eller 2 eller 4 eller 8 før det legges til den gitte adressen. mov (kopi)-instruksjonen til x64 kan kombinere både indirekte og indeksert adressering. Eksempel:
MOV R8W, 1234[8*RAX+RCX] ; flytt ord på adressen (8 x RAX + RCX) + 1234
Her har R8W de første 16-bitene av R8. Den oppgitte adressen er 1234. RAX-registeret har et 64-bits tall som multipliseres med 8. Resultatet legges til innholdet i 64-biters RCX-registeret. Dette andre resultatet legges til den gitte adressen som er 1234 for å oppnå den effektive adressen. Nummeret i plasseringen av den effektive adressen flyttes (kopieres) til det første 16-bits stedet (R8W) i R8-registeret, og erstatter det som var der. Legg merke til bruken av firkantede parenteser. Husk at et ord i x64 er 16-bits bredt.
RIP relativ adressering
For 6502 µP brukes relativ adressering kun med greninstruksjoner. Der er enkeltoperanden til opkoden en offset som legges til eller trekkes fra innholdet i programtelleren for den effektive instruksjonsadressen (ikke dataadressen). En lignende ting skjer med x64 der programtelleren kalles som instruksjonspeker. Instruksjonen med x64 trenger ikke bare være en greninstruksjon. Et eksempel på RIP-relativ adressering er:
MOV AL, [RIP]
AL av RAX har et 8-bits signert tall som legges til eller trekkes fra innholdet i RIP (64-bits instruksjonspeker) for å peke til neste instruksjon. Merk at kilden og destinasjonen unntaksvis byttes i denne instruksjonen. Legg også merke til bruken av hakeparentesene som refererer til innholdet i RIP.
6.34 Vanlige instruksjoner for x64
I den følgende tabellen betyr * forskjellige mulige suffikser for et undersett av opkoder:
| Tabell 6.34.1 Vanlig brukte instruksjoner i x64 |
|
|---|---|
| Opcode | Betydning |
| MOV | Flytt (kopier) til/fra/mellom minne og registre |
| CMOV* | Ulike betingede trekk |
| XCHG | Utveksling |
| BSWAP | Bytebytte |
| PUSH/POP | Stabelbruk |
| ADD/ADC | Legg til/med bære |
| SUB/SBC | Trekk fra/med bære |
| MUL/IMUL | Multiplisere/usignert |
| DIV/IDIV | Del/usignert |
| INC/DES | Øke/minske |
| NEG | Neger |
| CMP | Sammenligne |
| OG/ELLER/XOR/IKKE | Bitvise operasjoner |
| SHR/SAR | Skift til høyre logisk/aritmetikk |
| SHL/SAL | Skift til venstre logisk/aritmetikk |
| ROR/ROLE | Roter til høyre/venstre |
| RCR/RCL | Roter til høyre/venstre gjennom bærebiten |
| BT/BTS/BTR | Bit test/og sett/og reset |
| JMP | Ubetinget hopp |
| JE/JNE/JC/JNC/J* | Hopp hvis lik / ikke lik / bære / ikke bære / mange andre |
| GÅ/GÅ/GÅ | Løkke med ECX |
| RING/RET | Ring subrutine/retur |
| NOP | Ingen operasjon |
| CPUID | CPU-informasjon |
x64 har multiplikasjons- og divideringsinstruksjoner. Den har multiplikasjons- og divisjonsmaskinvarekretser i µP. 6502 µP har ikke multiplikasjons- og divisjonsmaskinvarekretser. Det er raskere å gjøre multiplikasjon og divisjon etter maskinvare enn med programvare (inkludert forskyvning av biter).
Strenginstruksjoner
Det finnes en rekke strenginstruksjoner, men den eneste som skal diskuteres her er MOVS (for move string) instruksjonen for å kopiere en streng som starter på adressen C000 H . For å starte på adresse C100 H , bruk følgende instruksjon:
MOVS [C100H], [C000H]
Legg merke til suffikset H for heksadesimal.
6.35 Løkker inn x64
6502 µP har greninstruksjoner for looping. En greninstruksjon hopper til en adresseplassering som har den nye instruksjonen. Adresseplasseringen kan kalles 'løkke'. x64 har LOOP/LOOPE/LOOPNE-instruksjoner for looping. Disse reserverte samlingsspråkordene må ikke forveksles med 'løkke'-etiketten (uten anførselstegn). Oppførselen er som følger:
LOOP reduserer ECX og sjekker om ECX ikke er null. Hvis denne betingelsen (null) er oppfylt, hopper den til en spesifisert etikett. Ellers faller det igjennom (fortsett med resten av instruksjonene i den følgende diskusjonen).
LOOPE reduserer ECX og sjekker at ECX ikke er null (kan være 1 for eksempel) og ZF er satt (til 1). Hvis disse betingelsene er oppfylt, hopper den på etiketten. Ellers faller det igjennom.
LOOPNE reduserer ECX og sjekker at ECX ikke er null og ZF IKKE ER satt (dvs. være null). Hvis disse betingelsene er oppfylt, hopper den til etiketten. Ellers faller det igjennom.
Med x64 holder RCX-registeret eller dets underdeler som ECX eller CX tellerheltallet. Med LOOP-instruksjonene teller telleren normalt ned, og reduseres med 1 for hvert hopp (løkke). I følgende sløyfekodesegment øker tallet i EAX-registeret fra 0 til 10 i ti iterasjoner mens tallet i ECX teller (minsker) ned 10 ganger (les kommentarene):
MOV EAX, 0 ;
MOV ECX, 10 ; teller ned 10 ganger som standard, én gang for hver iterasjon
merkelapp:
INC EAX ; øke EAX som loop body
LOOP-etikett ; redusere EAX, og hvis EAX ikke er null, utfør loop body fra 'label:' på nytt
Sløyfekodingen begynner fra 'label:'. Legg merke til bruken av kolon. Sløyfekodingen avsluttes med 'LOOP-etiketten' som sier dekrement EAX. Hvis innholdet ikke er null, gå tilbake til instruksjonen etter 'label:' og utfør alle instruksjoner på nytt (alle kroppsinstruksjoner) som kommer nedover til 'LOOP label'. Merk at 'etikett' fortsatt kan ha et annet navn.
6.36 Inngang/utgang av x64
Denne delen av kapittelet omhandler sending av data til en utgangsport (intern) eller mottak av data fra en inngangsport (intern). Brikkesettet har åtte-bits porter. Hvilke som helst to påfølgende 8-bits porter kan behandles som en 16-bits port, og alle fire påfølgende porter kan være en 32-bits port. På denne måten kan prosessoren overføre 8, 16 eller 32 biter til eller fra en ekstern enhet.
Informasjonen kan overføres mellom prosessoren og en intern port på to måter: ved å bruke det som er kjent som minnetilordnet input/output eller ved å bruke et separat input/output adresserom. Den minnetilordnede I/O-en er som det som skjer med 6502-prosessoren der portadressene faktisk er en del av hele minneplassen. I dette tilfellet, når dataene sendes til et bestemt adressested, går de til en port og ikke til en minnebank. Porter kan ha et eget I/O-adresseområde. I dette sistnevnte tilfellet har alle minnebankene sine adresser fra null. Det er et eget adresseområde fra 0000H til FFFF16. Disse brukes av portene i brikkesettet. Hovedkortet er programmert for ikke å forveksle mellom minnetilordnet I/O og separat I/O-adresserom.
Minnetilordnet I/O
Med dette betraktes portene som minneplasseringer, og de vanlige opkodene som skal brukes mellom minnet og µP brukes for dataoverføring mellom µP og porter. Så for å flytte en byte fra en port på adressen F000H til µP-registeret RAX:EAX:AX:AL, gjør du følgende:
MOV AL, [F000H]
En streng kan flyttes fra minnet til en port og omvendt. Eksempel:
MOVS [F000H], [C000H]; kilden er C000H, og destinasjonen er port på F000H.
Separat I/O-adresserom
Med dette må de spesielle instruksjonene for input og output brukes.
Overføring av enkeltelementer
Behandlerregisteret for overføringen er RAX. Faktisk er det RAX:EAX for dobbeltord, RAX:EAX:AX for ord og RAX:EAX:AX:AL for byte. Så for å overføre en byte fra en port ved FFF0h til RAX:EAX:AX:AL, skriv inn følgende:
I AL, [FFF0H]
For omvendt overføring, skriv inn følgende:
UT [FFF0H], AL
Så for enkeltvarer er instruksjonene INN og UT. Portadressen kan også oppgis i RDX:EDX:DX-registeret.
Overføre strenger
En streng kan overføres fra minnet til en brikkesettport og omvendt. For å overføre en streng fra en port på adressen FFF0H til minnet, start på C100H, skriv:
INS [ESI], [DX]
som har samme effekt som:
INS [EDI], [DX]
Programmereren bør sette to-byte-portadressen til FFF0H i RDX:EDX:Dx-registeret, og bør sette to-byte-adressen til C100H i RSI:ESI- eller RDI:EDI-registeret. For omvendt overføring, gjør følgende:
INS [DX], [ESI]
som har samme effekt som:
INS [DX], [EDI]
6.37 The Stack i x64
I likhet med 6502-prosessoren har også x64-prosessoren en stabel i RAM. Stabelen for x64 kan være 2 16 = 65 536 byte lang eller den kan være 2 32 = 4 294 967 296 byte lang. Den vokser også nedover. Når innholdet i et register skyves inn i stabelen, reduseres tallet i RSP-stabelpekeren med 8. Husk at en minneadresse for x64 er 64 bit bred. Verdien i stabelpekeren i µP peker til neste plassering i stabelen i RAM. Når innholdet i et register (eller en verdi i en operand) blir poppet fra stabelen inn i et register, økes tallet i RSP-stabelpekeren med 8. Operativsystemet bestemmer størrelsen på stabelen og hvor den starter i RAM og vokser nedover. Husk at en stack er en Last-In-First-Out (LIFO) struktur som vokser nedover og krymper oppover i dette tilfellet.
For å skyve innholdet i µP RBX-registeret til stabelen, gjør følgende:
PUSH RBX
For å få den siste oppføringen i stabelen tilbake til RBX, gjør følgende:
POP RBX
6.38 Prosedyre i x64
Subrutinen i x64 kalles 'prosedyre'. Stabelen brukes her mer enn den brukes til 6502 µP. Syntaksen for en x64-prosedyre er:
proc_name:
prosedyreorgan
…
Ikke sant
Før du fortsetter, legg merke til at op-kodene og etikettene for en x64-subrutine (sammenstillingsspråkinstruksjoner generelt) ikke skiller mellom store og små bokstaver. Det er proc_name er det samme som PROC_NAME. I likhet med 6502 starter navnet på prosedyrenavnet (etiketten) på begynnelsen av en ny linje i tekstredigeringsprogrammet for assembly-språket. Dette etterfølges av et kolon og ikke av mellomrom og opkode som med 6502. Subrutinekroppen følger, og slutter med RET og ikke RTS som med 6502 µP. Som med 6502, begynner ikke hver instruksjon i kroppen, inkludert RET, på begynnelsen av linjen. Merk at en etikett her kan være på mer enn 8 tegn. For å kalle denne prosedyren, fra over eller under den maskinskrevne prosedyren, gjør du følgende:
RING proc_name
Med 6502 er navnet på etiketten bare type for å ringe. Men her skrives det reserverte ordet 'CALL' eller 'call', etterfulgt av navnet på prosedyren (subrutinen) etter et mellomrom.
Når det gjelder prosedyrer, er det vanligvis to prosedyrer. Den ene prosedyren kaller den andre. Prosedyren som anroper (har anropsinstruksjonen) kalles 'oppringeren', og prosedyren som kalles kalles 'kalleren'. Det er en konvensjon (regler) å følge.
Ringerens regler
Den som ringer bør overholde følgende regler når han påkaller en subrutine:
1. Før du ringer en subrutine, bør den som ringer lagre innholdet i visse registre som er utpekt som innringer-lagret til stabel. De oppringerlagrede registrene er R10, R11 og eventuelle registre som parametrene er satt inn i (RDI, RSI, RDX, RCX, R8, R9). Hvis innholdet i disse registrene skal bevares på tvers av subrutineanropet, skyver du dem på stabelen i stedet for å lagre deretter i RAM. Disse må gjøres fordi registrene må brukes av den som kalles for å slette det tidligere innholdet.
2. Hvis prosedyren er å legge til to tall for eksempel, er de to tallene parametrene som skal sendes til stabelen. For å sende parametrene til subrutinen, sett opp seks av dem i følgende registre i rekkefølge: RDI, RSI, RDX, RCX, R8, R9. Hvis det er mer enn seks parametere til subrutinen, skyv resten på stabelen i omvendt rekkefølge (dvs. siste parameter først). Siden stabelen vokser ned, blir den første av de ekstra parameterne (egentlig den syvende parameteren) lagret på den laveste adressen (denne inversjonen av parametere ble historisk brukt for å la funksjonene (subrutinene) sendes med et variabelt antall parametere).
3. For å ringe subrutinen (prosedyren), bruk anropsinstruksjonen. Denne instruksjonen plasserer returadressen på toppen av parameterne på stabelen (laveste posisjon) og grenene til subrutinekoden.
4. Etter at subrutinen kommer tilbake (dvs. umiddelbart etter anropsinstruksjonen), må den som ringer fjerne eventuelle tilleggsparametre (utover de seks som er lagret i registre) fra stabelen. Dette gjenoppretter stabelen til dens tilstand før anropet ble utført.
5. Den som ringer kan forvente å finne returverdien (adressen) til subrutinen i RAX-registeret.
6. Den som ringer gjenoppretter innholdet i de oppringer-lagrede registrene (R10, R11 og alle i parameter-passeringsregistrene) ved å sprette dem ut av stabelen. Den som ringer kan anta at ingen andre registre ble modifisert av subrutinen.
På grunn av måten anropskonvensjonen er strukturert på, er det vanligvis slik at noen (eller de fleste) av disse trinnene ikke vil gjøre noen endringer i stabelen. For eksempel, hvis det er seks eller færre parametere, blir ingenting skjøvet inn på stabelen i det trinnet. På samme måte holder programmererne (og kompilatorene) vanligvis resultatene de bryr seg om, utenfor de oppringerlagrede registrene i trinn 1 og 6 for å forhindre overflødige push og pops.
Det er to andre måter å overføre parametrene til en subrutine på, men de vil ikke bli behandlet i dette online karrierekurset. En av dem bruker selve stabelen i stedet for de generelle registrene.
The Callees regler
Definisjonen av den kalte subrutinen bør følge følgende regler:
1. Tildel de lokale variablene (variabler som er utviklet innenfor prosedyren) ved å bruke registrene eller lage plass på stabelen. Husk at stabelen vokser nedover. Så for å få plass på toppen av stabelen, bør stabelpekeren reduseres. Mengden som stabelpekeren dekrementeres med avhenger av det nødvendige antallet lokale variabler. For eksempel, hvis en lokal flyter og en lokal lang (totalt 12 byte) kreves, må stabelpekeren reduseres med 12 for å gjøre plass til disse lokale variablene. I et høynivåspråk som C betyr dette å deklarere variablene uten å tilordne (initialisere) verdiene.
2. Deretter må verdiene til eventuelle registre som er de utpekte oppringte-lagrede (generelle registre som ikke lagres av den som ringer) som brukes av funksjonen, lagres. For å lagre registrene, skyv dem på stabelen. De oppringte lagrede registrene er RBX, RBP og R12 til og med R15 (RSP er også bevart av samtalekonvensjonen, men trenger ikke skyves på stabelen under dette trinnet).
Etter at disse tre handlingene er utført, kan den faktiske operasjonen av subrutinen fortsette. Når subrutinen er klar til å returnere, fortsetter samtalekonvensjonens regler.
3. Når subrutinen er ferdig, skal returverdien for subrutinen plasseres i RAX hvis den ikke allerede er der.
4. Subrutinen må gjenopprette de gamle verdiene til alle oppringte-lagrede registre (RBX, RBP og R12 til R15) som ble endret. Registerinnholdet gjenopprettes ved å sprette dem fra stabelen. Merk at registrene skal vises i omvendt rekkefølge som de ble skjøvet.
5. Deretter deallokerer vi de lokale variablene. Den enkleste måten å gjøre dette på er å legge til RSP det samme beløpet som ble trukket fra det i trinn 1.
6. Til slutt går vi tilbake til den som ringer ved å utføre en ret-instruksjon. Denne instruksjonen vil finne og fjerne riktig returadresse fra stabelen.
Et eksempel på kroppen til en subrutine som ringer for å ringe en annen subrutine som er 'myFunc' er som følger (les kommentarene):
; Ønsker å kalle en funksjon 'myFunc' som tar tre
; heltallsparameter. Første parameter er i RAX.
; Andre parameter er konstanten 456. Tredje
; parameteren er i minneplasseringen 'variabel'
push rdi ; rdi vil være en param, så du lagrer den
; long retVal = myFunc (x, 456, z);
mov rdi , rax ; sette første parameter i RDI
mov rsi, 456; sette andre parameter i RSI
mov rdx , [variabel] ; sette tredje parameter i RDX
ring myFunc ; kall opp funksjonen
pop rdi ; gjenopprett lagret RDI-verdi
; returverdien til myFunc er nå tilgjengelig i RAX
Et eksempel på en callee-funksjon (myFunc) er (les kommentarene):
myFunc:
; ∗∗∗ Standard subrutineprolog ∗∗∗
under rsp, 8; plass til en 64-bit lokal variabel (resultat) ved å bruke 'sub'-opkoden
push rbx ; lagre callee-lagre registre
push rbp ; begge vil bli brukt av myFunc
; ∗∗∗ Underrutine Kropp ∗∗∗
mov rax , rdi ; parameter 1 til RAX
mov rbp , rsi ; parameter 2 til RBP
mov rbx , rdx ; parameter 3 til rb x
mov [rsp + 1 6], rbx; legg rbx inn i lokal variabel
legg til [rsp + 1 6], rbp; legg til rbp i lokal variabel
mov rax, [rsp +16]; flytt innholdet i lokal variabel til RAX
; (returverdi/sluttresultat)
; ∗∗∗ Standard subrutine epilog ∗∗∗
pop rbp ; gjenopprette callee lagre registre
pop rbx ; revers av når den trykkes
legg til rsp, 8; deallokere lokale variabler. 8 betyr 8 byte
ret ; pop toppverdi fra stabelen, hopp dit
6.39 Avbrudd og unntak for x64
Prosessoren gir to mekanismer for å avbryte programkjøringen, avbrudd og unntak:
- Et avbrudd er en asynkron (kan skje når som helst) hendelse som vanligvis utløses av en I/O-enhet.
- Et unntak er en synkron hendelse (som skjer når koden kjøres, forhåndsprogrammeres, basert på en eller annen forekomst) som genereres når prosessoren oppdager en eller flere forhåndsdefinerte forhold mens den utfører en instruksjon. Tre klasser av unntak er spesifisert: feil, feller og avbrudd.
Prosessoren reagerer på avbrudd og unntak i hovedsak på samme måte. Når et avbrudd eller unntak signaliseres, stopper prosessoren utførelsen av gjeldende program eller oppgave og bytter til en behandlerprosedyre som er skrevet spesifikt for å håndtere avbrudds- eller unntakstilstanden. Prosessoren får tilgang til behandlerprosedyren gjennom en oppføring i Interrupt Descriptor Table (IDT). Når behandleren har fullført håndteringen av avbruddet eller unntaket, returneres programkontrollen til det avbrutte programmet eller oppgaven.
Operativsystemet, executive og/eller enhetsdrivere håndterer vanligvis avbruddene og unntakene uavhengig av applikasjonsprogrammene eller oppgavene. Applikasjonsprogrammene kan imidlertid få tilgang til avbrudds- og unntaksbehandlerne som er integrert i et operativsystem eller utføre det gjennom assembly-språk-kallene.
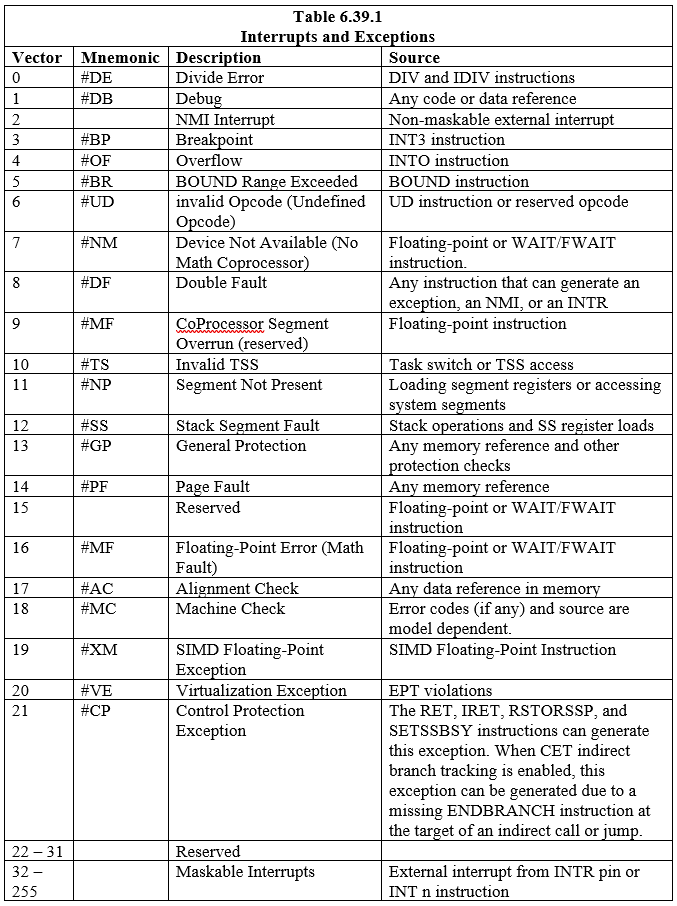
Atten (18) forhåndsdefinerte avbrudd og unntak, som er knyttet til oppføringer i IDT, er definert. To hundre og tjuefire (224) brukerdefinerte avbrudd kan også gjøres og assosieres med tabellen. Hvert avbrudd og unntak i IDT er identifisert med et nummer som kalles en 'vektor'. Tabell 6.39.1 viser avbrudd og unntak med oppføringer i IDT og deres respektive vektorer. Vektorene 0 til 8, 10 til 14 og 16 til 19 er forhåndsdefinerte avbrudd og unntak. Vektorene 32 til og med 255 er for programvaredefinerte avbrudd (bruker) som er for enten programvareavbrudd eller maskerbare maskinvareavbrudd.
Når prosessoren oppdager et avbrudd eller unntak, gjør den en av følgende ting:
- Utfør et implisitt kall til en behandlerprosedyre
- Utfør et implisitt kall til en behandleroppgave
6.4 Grunnleggende om 64-biters ARM-datamaskinarkitektur
ARM-arkitekturene definerer en familie av RISC-prosessorer som er egnet for bruk i en lang rekke applikasjoner. ARM er en load/store-arkitektur som krever at dataene lastes fra minnet til et register før noen behandling som en ALU-operasjon (Aritmetic Logic Unit) kan finne sted med den. En påfølgende instruksjon lagrer resultatet tilbake i minnet. Selv om dette kan virke som et skritt tilbake fra x86- og x64-arkitekturene, som opererer direkte på operandene i minnet i en enkelt instruksjon (ved hjelp av prosessorregistre, selvfølgelig), tillater load/store-tilnærmingen i praksis flere sekvensielle operasjoner skal utføres med høy hastighet på en operand når den er lastet inn i et av de mange prosessorregistrene. ARM-prosessorer har valget mellom liten eller stor endianness. Standard ARM 64-innstillingen er little-endian, som er konfigurasjonen som vanligvis brukes av operativsystemene. 64-biters ARM-arkitekturen er moderne, og den er satt til å erstatte 32-biters ARM-arkitekturen.
Merk : Hver instruksjon for 64-biters ARM µP er 4 byte (32 biter) lang.
6.41 64-biters ARM-registersett
Det er 31 generelle formål med 64-bits registre for 64-biters ARM µP. Følgende diagram viser de generelle registrene og noen viktige registre:
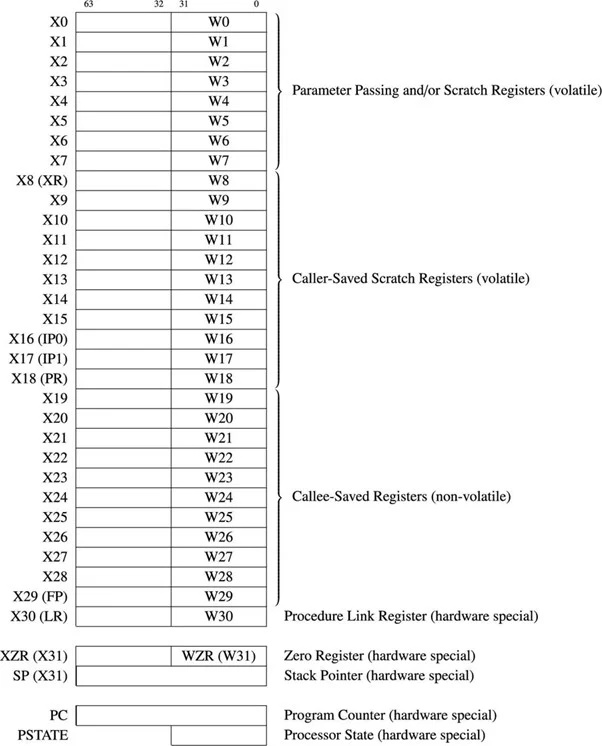
Fig.4.11.1 64-biters generelle formål og noen viktige registre
De generelle registrene refereres til som X0 til X30. Den første 32-bits delen for hvert register blir referert til som W0 til W30. Når forskjellen mellom 32 bits og 64 bits ikke er vektlagt, brukes prefikset 'R'. For eksempel refererer R14 til W14 eller X14.
6502 µP har en 16-bits programteller og kan adressere 2 16 minnebyteplasseringer. 64-biters ARM µP har en 64-bits programteller og kan adressere opptil 2 64 = 1,844674407 x 1019 (faktisk 18.446.744.073.709.551.616) minnebyteplasseringer. Programtelleren holder adressen til den neste instruksjonen som skal utføres. Lengden på instruksjonen til ARM64 eller AArch64 er vanligvis fire byte. Prosessoren øker automatisk dette registeret med fire etter at hver instruksjon er hentet fra minnet.
Stack Pointer-registeret eller SP er ikke blant de 31 generelle registrene. Stabelpekeren til enhver arkitektur peker til den siste stabeloppføringen i minnet. For ARM-64 vokser stabelen nedover.
6502 µP har et 8-bits prosessorstatusregister. Ekvivalenten i ARM64 kalles PSTATE-registeret. Dette registeret lagrer flaggene som brukes for resultatene av operasjoner og for å kontrollere prosessoren (µP). Den er 32-bits bred. Følgende tabell gir navn, indeks og betydninger for de vanligste bitene i PSTATE-registeret:
| Tabell 6.41.1 Mest brukte PSTATE-flagg (biter) |
||
|---|---|---|
| Symbol | Bit | Hensikt |
| M | 0-3 | Modus: Gjeldende rettighetsnivå for utførelse (USR, SVC, og så videre). |
| T | 4 | Tommel: Den settes hvis T32 (Tommel) instruksjonssettet er aktivt. Hvis det er klart, er ARM-instruksjonssettet aktivt. Brukerkoden kan angi og slette denne biten. |
| OG | 9 | Endianness: Innstilling av denne biten aktiverer big-endian-modusen. Hvis den er klar, er den lille endian-modusen aktiv. Standard er den lille endian-modusen. |
| Q | 27 | Kumulativt metningsflagg: Det settes hvis det på et tidspunkt i en serie operasjoner oppstår et overløp eller metning |
| I | 28 | Overløpsflagg: Det settes hvis operasjonen resulterte i et signert overløp. |
| C | 29 | Carry-flagg: Det indikerer om addisjonen ga en carry eller subtraksjonen ga et lån. |
| MED | 30 | Nullflagg: Det settes hvis resultatet av en operasjon er null. |
| N | 31 | Negativt flagg: Det settes hvis resultatet av en operasjon er negativt. |
ARM-64 µP har mange andre registre.
SIMD
SIMD står for Single Instruction, Multiple Data. Dette betyr at én assemblerspråkinstruksjon kan virke på flere data samtidig i én mikroprosessor. Det er trettito 128-bits brede registre for bruk med SIMD- og flyttalloperasjoner.
6.42 Minnekartlegging
RAM og DRAM er begge Random Access-minner. DRAM er tregere i drift enn RAM. DRAM er billigere enn RAM. Hvis det er mer enn 32 gigabyte (GB) med kontinuerlig DRAM i minnet, vil det være flere problemer med minneadministrasjon: 32 GB = 32 x 1024 x 1024 x 1024 byte. For en hel minneplass som er langt større enn 32 GB, bør DRAM over 32 GB være ispedd RAM-er for bedre minnehåndtering. For å forstå ARM-64 minnekartet, bør du først forstå 4GB minnekartet for 32-biters ARM Central Processing Unit (CPU). CPU betyr µP. For en 32-bits datamaskin er den maksimale minneadresserbare plassen 2 32 = 4 x 2 10 x 2 10 x 2 10 = 4 x 1024 x 1024 x 1024 = 4 294 967 296 = 4 GB.
32-biters ARM-minnekart
Minnekartet for en 32-biters ARM er:

For en 32-bits datamaskin er maksimal størrelse på hele minnet 4 GB. Fra 0GB-adressen til 1GB-adressen er ROM-operativsystemet, RAM- og I/O-plasseringene. Hele ideen med ROM OS, RAM og I/O-adresser ligner situasjonen til Commodore-64 med en mulig 6502 CPU. OS ROM for Commodore-64 er øverst på minneplassen. ROM OS her er mye større enn Commodore-64, og det er i begynnelsen av hele minneadresserommet. Sammenlignet med andre moderne datamaskiner, er ROM OS her komplett, i den forstand at det er sammenlignbart med mengden OS på harddiskene deres. Det er to hovedgrunner for å ha OS i de integrerte ROM-kretsene: 1) ARM-CPU-er brukes mest i små enheter som smarttelefoner. Mange harddisker er større enn smarttelefoner og andre små enheter, 2) for sikkerhet. Når operativsystemet er i skrivebeskyttet minne, kan det ikke ødelegges (deler overskrives) av hackere. RAM-seksjonene og input/output-seksjonene er også veldig store sammenlignet med Commodore-64.
Når strømmen slås på med 32-biters ROM OS, må operativsystemet starte på (starte opp fra) 0x00000000-adressen eller 0xFFFF0000-adressen hvis HiVECs er aktivert. Så når strømmen settes på etter tilbakestillingsfasen, laster CPU-maskinvaren 0x00000000 eller 0xFFFF0000 til programtelleren. Prefikset '0x' betyr Heksadesimal. Oppstartsadressen til ARMv8 64bit CPUer er en definert implementering. Forfatteren råder imidlertid dataingeniøren til å starte på 0x00000000 eller 0xFFFF0000 av hensyn til bakoverkompatibilitet.
Fra 1 GB til 2 GB er den kartlagte inngangen/utgangen. Det er en forskjell mellom kartlagt I/O og bare I/O som finnes mellom 0GB og 1GB. Med I/O er adressen for hver port fast som med Commodore-64. Med kartlagt I/O er ikke adressen for hver port nødvendigvis den samme for hver operasjon av datamaskinen (dynamisk).
Fra 2 GB til 4 GB er DRAM. Dette er forventet (eller vanlig) RAM. DRAM står for Dynamic RAM, ikke er følelsen av å endre adresse under datamaskindrift, men i den forstand at verdien av hver celle i den fysiske RAM-en må oppdateres ved hver klokkepuls.
Merk :
- Fra 0x0000,0000 til 0x0000, FFFF er OS ROM.
- Fra 0x0001,0000 til 0x3FFF,FFFF kan det være mer ROM, deretter RAM, og så litt I/O.
- Fra 0x4000,0000 til 0x7FFF,FFFF, en ekstra I/O og/eller kartlagt I/O er tillatt.
- Fra 0x8000 0000 til 0xFFFF er FFFF forventet DRAM.
Disse betyr at forventet DRAM ikke trenger å starte ved 2GB-minnegrensen, i praksis. Hvorfor skal programmereren respektere de ideelle grensene når det ikke er nok fysiske RAM-banker som er plassert på hovedkortet? Dette er fordi kunden ikke har nok penger til alle RAM-bankene.
36-biters ARM-minnekart
For en 64-bits ARM-datamaskin brukes alle de 32 bitene til å adressere hele minnet. For en 64-bits ARM-datamaskin kan de første 36 bitene brukes til å adressere hele minnet, som i dette tilfellet er 2 36 = 68 719 476 736 = 64 GB. Dette er mye minne allerede. De vanlige datamaskinene i dag trenger ikke denne mengden minne. Dette er ennå ikke opp til det maksimale minneområdet som kan nås med 64 biter. Minnekartet for 36-biter for ARM CPU er:
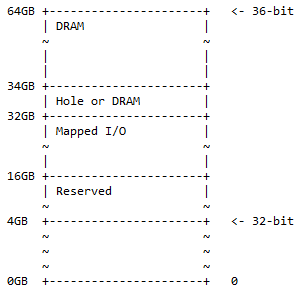
Fra 0GB-adressen til 4GB-adressen er 32-bits minnekartet. 'Reservert' betyr ikke brukt og oppbevares for fremtidig bruk. Det trenger ikke å være fysiske minnebanker som er plassert på hovedkortet for den plassen. Her har DRAM og kartlagt I/O samme betydning som for 32-bits minnekartet.
Følgende situasjon kan oppstå i praksis:
- 0x1 0000 0000 – 0x3 FFFF FFFF; forbeholdt. 12 GB adresseplass er reservert for fremtidig bruk.
- 0x4 0000 0000 – 0x7 FFFF FFFF; kartlagt I/O. 16 GB adresseplass er tilgjengelig for dynamisk kartlagt I/O.
- 0x8 0000 0000 – 0x8 7FFF FFFF FFFF; Hull eller DRAM. 2 GB adresseplass kan inneholde ett av følgende:
- Hull for å aktivere DRAM-enhetspartisjonering (som beskrevet i den følgende diskusjonen).
- DRAM.
- 0x8 8000 0000 – 0xF FFFF FFFF; DRAM. 30 GB adresseplass for DRAM.
Dette minnekartet er et supersett av 32-biters adressekart, med den ekstra plassen deles som 50 % DRAM (1/2) med et valgfritt hull i og 25 % kartlagt I/O-plass og reservert plass (1/4) ). De resterende 25 % (1/4) er for 32-bits minnekartet ½ + ¼ + ¼ = 1.
Merk : Fra 32 bits til 360 bits er et tillegg av 4 bits til den mest signifikante siden av 36 bits.
40-biters minnekart
40-biters adressekartet er et supersett av 36-biters adressekartet og følger det samme mønsteret med 50 % DRAM til et valgfritt hull i det, 25 % kartlagt I/O-rom og reservert plass, og resten av de 25 % plass til forrige minnekart (36-bit). Diagrammet for minnekartet er:
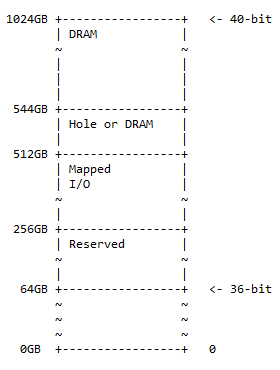
Størrelsen på hullet er 544 – 512 = 32 GB. Følgende situasjon kan oppstå i praksis:
- 0x10 0000 0000 – 0x3F FFFF FFFF; forbeholdt. 192 GB adresseplass er reservert for fremtidig bruk.
- 0x40 0000 0000 – 0x7F FFFF FFFF; kartlagt. I/O 256 GB adresseplass er tilgjengelig for dynamisk kartlagt I/O.
- 0x80 0000 0000 – 0x87 FFFF FFFF; hull eller DRAM. 32 GB adresseplass kan inneholde ett av følgende:
- Hull for å aktivere DRAM-enhetspartisjonering (som beskrevet i følgende diskusjon)
- DRAM
- 0x88 0000 0000 – 0xFF FFFF FFFF; DRAM. 480 GB adresseplass for DRAM.
Merk : Fra 36 bits til 40 bits er et tillegg av 4 bits til den mest signifikante siden av 36 bits.
DRAM-hull
I minnekartet utover 32-biter er det enten et DRAM-hull eller en fortsettelse av DRAM fra toppen. Når det er et hull, skal det forstås som følger: DRAM-hull gir en måte å partisjonere en stor DRAM-enhet i flere adresseområder. Det valgfrie DRAM-hullet er foreslått ved starten av den høyere DRAM-adressegrensen. Dette muliggjør et forenklet dekodingsskjema ved partisjonering av en DRAM-enhet med stor kapasitet over den nedre fysisk adresserte regionen.
For eksempel er en 64 GB DRAM-del delt inn i tre regioner med adresseforskyvninger utført ved en enkel subtraksjon i høyordens adressebiter som følger:
| Tabell 6.42.1 Eksempel på 64 GB DRAM-partisjonering med hull |
|||
|---|---|---|---|
| Fysiske adresser i SoC | Offset | Intern DRAM-adresse | |
| 2 GByte (32-bit kart) | 0x00 8000 0000 – 0x00 FFFF FFFF | -0x00 8000 0000 | 0x00 0000 0000 – 0x00 7FFF FFFF |
| 30 GByte (36-bit kart) | 0x08 8000 0000 – 0x0F FFFF FFFF | -0x08 0000 0000 | 0x00 8000 0000 – 0x07 FFFF FFFF |
| 32 GByte (40-bit kart) | 0x88 0000 0000 – 0x8F FFFF FFFF | -0x80 0000 0000 | 0x08 0000 0000 – 0x0F FFFF FFFF |
Foreslåtte 44-biters og 48-biters adresserte minnekart for ARM CPUer
Anta at en personlig datamaskin har 1024 GB (= 1 TB) minne; det er for mye minne. Og derfor er 44-biters og 48-biters adresserte minnekart for ARM CPUer for henholdsvis 16 TB og 256 TB bare forslag for fremtidige datamaskinbehov. Faktisk følger disse forslagene for ARM-CPU-ene samme inndeling av minne etter forhold som de tidligere minnekartene. Det vil si: 50 % DRAM med et valgfritt hull i, 25 % kartlagt I/O-plass og reservert plass, og resten av 25 % plass for forrige minnekart.
52-biters, 56-biters, 60-biters og 64-biters adresserte minnekart skal fortsatt foreslås for ARM 64-bitene i lang fremtid. Hvis forskerne på den tiden fortsatt finner 50 : 25 : 25-partisjoneringen av hele minneplassen nyttig, vil de opprettholde forholdet.
Merk : SoC står for System-on-Chip som refererer til kretser i µP-brikken som ellers ikke ville vært der.
SRAM eller Static Random Access Memory er raskere enn den mer tradisjonelle DRAM, men krever mer silisiumareal. SRAM krever ikke oppfriskning. Leseren kan forestille seg RAM som SRAM.
6.43 Assembly Language Addressing Modes for ARM 64
ARM er en load/store-arkitektur som krever at dataene lastes fra minnet til et prosessorregister før noen behandling som en aritmetisk logisk operasjon kan finne sted med den. En påfølgende instruksjon lagrer resultatet tilbake i minnet. Selv om dette kan virke som et skritt tilbake fra x86 og dens påfølgende x64-arkitekturer, som opererer direkte på operandene i minnet i en enkelt instruksjon, tillater load/store-tilnærmingen i praksis flere sekvensielle operasjoner med høy hastighet på en operand når den er lastet inn i et av de mange prosessorregistrene.
Formatet til ARM-monteringsspråket har likheter og forskjeller med x64 (x86)-serien.
- Offset : En fortegnet konstant kan legges til basisregisteret. Offset skrives inn som en del av instruksjonen. For eksempel: ldr x0, [rx, #10] laster r0 med ordet på r1+10-adressen.
- Registrere : Et usignert inkrement som er lagret i et register kan legges til eller trekkes fra verdien i et basisregister. For eksempel: ldr r0, [x1, x2] laster r0 med ordet på x1+x2-adressen. Begge registrene kan betraktes som basisregisteret.
- Skalert register : Et inkrement i et register forskyves til venstre eller høyre med et spesifisert antall bitposisjoner før det legges til eller trekkes fra basisregisterverdien. For eksempel: ldr x0, [x1, x2, lsl #3] laster r0 med ordet på r1+(r2×8)-adressen. Skiftet kan være et logisk venstre- eller høyreskift (lsl eller lsr) som setter inn nullbiter i de ledige bitposisjonene eller et aritmetisk høyreskift (asr) som replikerer fortegnsbiten i de ledige posisjonene.
Når to operander er involvert, kommer destinasjonen før (til venstre) kilden (det er noen unntak fra dette). Op-kodene for ARM-monteringsspråket skiller ikke mellom store og små bokstaver.
Umiddelbar ARM64-adresseringsmodus
Eksempel:
mov r0, #0xFF000000 ; Last inn 32-biters verdi FF000000h til r0
En desimalverdi er uten 0x, men har fortsatt # foran.
Registrer deg direkte
Eksempel:
mov x0, x1 ; Kopier x1 til x0
Registrer indirekte
Eksempel:
str x0, [x3]; Lagre x0 til adressen i x3
Registrer Indirekte med Offset
Eksempler:
ldr x0, [x1, #32] ; Last r0 med verdien på adressen [r1+32]; r1 er basisregisteret
str x0, [x1, #4] ; Lagre r0 til adressen [r1+4]; r1 er basisregisteret; tallene er base 10
Registrer indirekte med forskyvning (forhåndsinkrementert)
Eksempler:
ldr x0, [x1, #32]! ; Last r0 med [r1+32] og oppdater r1 til (r1+32)
str x0, [x1, #4]! ; Lagre r0 til [r1+4] og oppdater r1 til (r1+4)
Legg merke til bruken av '!' symbol.
Registrer Indirekte med Offset (Post-incremented)
Eksempler:
ldr x0, [x1], #32 ; Last [x1] til x0, og oppdater deretter x1 til (x1+32)
str x0, [x1], #4 ; Lagre x0 til [x1], og oppdater deretter x1 til (x1+4)
Dobbeltregister Indirekte
Adressen til operanden er summen av et basisregister og et inkrementregister. Registernavnene er omgitt av firkantede parenteser.
Eksempler:
ldr x0, [x1, x2]; Last inn x0 med [x1+x2]
str x0, [rx, x2]; Lagre x0 til [x1+x2]
Relativ adresseringsmodus
I relativ adresseringsmodus er den effektive instruksjonen den neste instruksjonen i programtelleren, pluss en indeks. Indeksen kan være positiv eller negativ.
Eksempel:
ldr x0, [pc, #24]
Dette betyr lastregisteret X0 med ordet som er pekt på av PC-innholdet pluss 24.
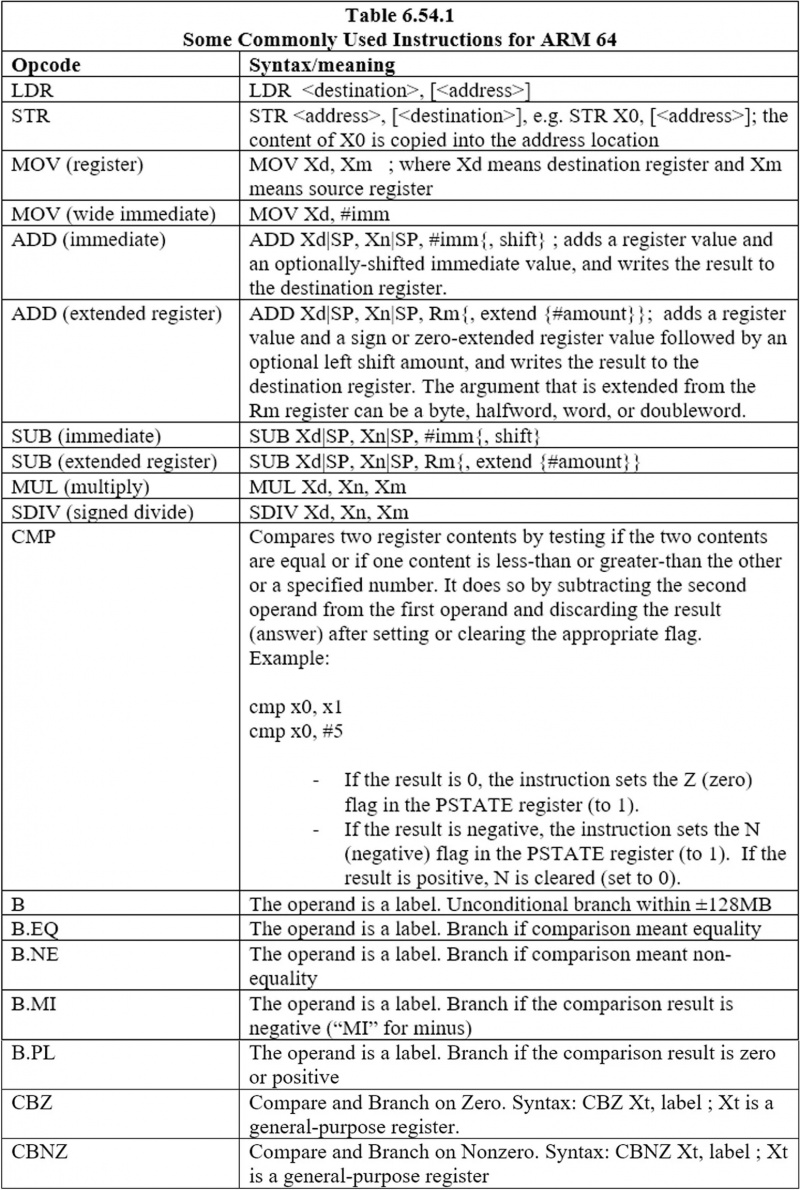
6.44 Noen ofte brukte instruksjoner for ARM 64
Her er de vanligste instruksjonene:
6.45 Looping
Illustrasjon
Følgende kode fortsetter å legge til verdien i X10-registeret til verdien i X9 til verdien i X8 er null. Anta at alle verdiene er heltall. Verdien i X8 trekkes fra med 1 i hver iterasjon:
Løkke:
CBZ X8, hopp over
LEGG TIL X9, X9, X10; første X9 er destinasjon og andre X9 er kilde
SUB X8, X8, #1 ; første X8 er destinasjon og andre X8 er kilde
B-løkke
hopp over:
Som med 6502 µP og X64 µP, begynner etiketten i ARM 64 µP på begynnelsen av linjen. Resten av instruksjonene starter på noen mellomrom etter begynnelsen av linjen. Med x64 og ARM 64 blir etiketten etterfulgt av et kolon og en ny linje. Mens med 6502, er etiketten etterfulgt av en instruksjon etter et mellomrom. I den forrige koden betyr den første instruksjonen som er 'CBZ X8, hopp over' at hvis verdien i X8 er null, fortsett ved 'hopp over:'-etiketten, hopp over instruksjonene i mellom og fortsett med resten av instruksjonene nedenfor 'hopp over:'. 'B loop' er et ubetinget hopp til 'loop'-etiketten. Ethvert annet etikettnavn kan brukes i stedet for 'løkke'.
Så, som med 6502 µP, bruk greninstruksjonene for å ha en sløyfe med ARM 64.
6.46 ARM 64 inngang/utgang
Alle ARM perifere enheter (interne porter) er minnekartlagt. Dette betyr at programmeringsgrensesnittet er et sett med minneadresserte registre (interne porter). Adressen til et slikt register er en offset fra en spesifikk minnebaseadresse. Dette ligner på hvordan 6502 gjør input/output. ARM har ikke mulighet for separat I/O-adresserom.
6.47 Stabel med ARM 64
ARM 64 har en stabel i minnet (RAM) på lignende måte som 6502 og x64 har. Men med ARM64 er det ingen push- eller pop-op-kode. Stakken i ARM 64 vokser også nedover. Adressen i stabelpekeren peker like etter den siste byten av den siste verdien som er plassert i stabelen.
Grunnen til at det ikke er noen generisk pop- eller push-op-kode for ARM64 er at ARM 64 administrerer stabelen sin i grupper med påfølgende 16 byte. Imidlertid finnes verdiene i bytegrupper på én byte, to byte, fire byte og 8 byte. Så én verdi kan plasseres i stabelen, og resten av stedene (byteplasseringer) for å gjøre opp for 16 byte er polstret med dummy-byte. Dette har den ulempen at det kaster bort minne. En bedre løsning er å fylle 16-byte lokasjonen med mindre verdier og ha en programmerer skrevet kode som sporer hvor verdiene i 16-byte lokasjonen kommer fra (registre). Denne ekstra koden er også nødvendig for å trekke tilbake verdiene. Et alternativ til dette er å fylle to 8-byte generelle registre med de forskjellige verdiene, og deretter sende innholdet i de to 8-byte registrene til en stabel. En ekstra kode er fortsatt nødvendig her for å spore de spesifikke små verdiene som går inn i stabelen og forlater stabelen.
Følgende kode lagrer fire 4-byte data i stabelen:
str w0, [sp, #-4]!
str w1, [sp, #-8]!
str w2, [sp, #-12]!
str w3, [sp, #-16]!
De første fire bytene (w) av registre – x0, x1, x2 og x3 – sendes til 16 påfølgende byteplasseringer i stabelen. Legg merke til bruken av 'str' og ikke 'push'. Legg merke til utropssymbolet på slutten av hver instruksjon. Siden minnestabelen vokser nedover, starter den første firebyte-verdien på en posisjon som er minus-fire byte under den forrige stabelpekerposisjonen. Resten av fire-byte-verdiene følger etter og går ned. Følgende kodesegment vil gjøre den riktige (og i rekkefølge) ekvivalenten til å poppe de fire bytene:
ldr w3, [sp], #0
ldr w2, [sp], #4
ldr w1, [sp], #8
ldr w0, [sp], #12
Legg merke til bruken av ldr-opkoden i stedet for pop. Merk også at utropssymbolet ikke brukes her.
Alle byte i X0 (8 byte) og X1 (8 byte) kan sendes til 16 byte-plasseringen i stabelen som følger:
stp x0, x1, [sp, #-16]! ; 8 + 8 = 16
I dette tilfellet er det ikke nødvendig med x2 (w2) og x3 (w3) registre. Alle de ønskede bytene er i X0- og X2-registrene. Legg merke til stp-opkoden for lagring av registerinnholdsparene i RAM-en. Legg også merke til utropssymbolet. Popekvivalenten er:
ldp x0, x1, [sp], #0
Det er ikke noe utropstegn for denne instruksjonen. Legg merke til op-koden LDP i stedet for LDR for å laste to påfølgende dataplasseringer fra minnet til to µP-registre. Husk også at kopiering fra minnet til et µP-register laster, ikke å forveksle med å laste en fil fra disken til RAM, og kopiering fra et µP-register til RAM er lagring.
6.48 Subrutine
En subrutine er en kodeblokk som utfører en oppgave, eventuelt basert på noen argumenter og eventuelt returnerer et resultat. Etter konvensjon brukes R0 til R3-registrene (fire registre) for å sende argumentene (parametrene) til en subrutine, og R0 brukes til å sende et resultat tilbake til den som ringer. En subrutine som trenger mer enn 4 innganger bruker stabelen for de ekstra inngangene. For å ringe en subrutine, bruk lenken eller den betingede greninstruksjonen. Syntaksen for koblingsinstruksjonen er:
BL-etikett
Der BL er opkoden og etiketten representerer starten (adressen) til subrutinen. Denne grenen er ubetinget, forover eller bakover innenfor 128 MB. Syntaksen for den betingede greninstruksjonen er:
B.cond etikett
Der cond er betingelsen, f.eks. eq (lik) eller ne (ikke lik). Følgende program har doadd-subrutinen som legger til verdiene til to argumenter og returnerer et resultat i R0:
AREA subrute, CODE, READONLY ; Gi denne kodeblokken et navn
PÅGANG ; Merk første instruksjon som skal utføres
start MOV r0, #10 ; Sett opp parametere
MOV r1, #3
BL doadd ; Ring subrutine
stopp MOV r0, #0x18 ; angel_SWIreason_ReportException
LDR r1, =0x20026; ADP_Stopped_ApplicationExit
SVC #0x123456 ; ARM semihosting (tidligere SWI)
doadd ADD r0, r0, r1; Subrutinekode
BX lr ; Retur fra subrutine
;
SLUTT ; Merk slutten av filen
Tallene som skal legges til er desimal 10 og desimal 3. De to første linjene i denne kodeblokken (programmet) vil bli forklart senere. De neste tre linjene sender 10 til R0 register og 3 til R1 register, og kaller også doadd-subrutinen. 'Doadd' er etiketten som inneholder adressen til begynnelsen av subrutinen.
Subrutinen består av bare to linjer. Den første linjen legger til innholdet 3 i R til innholdet 10 i R0 som tillater resultatet av 13 i R0. Den andre linjen med BX-opkoden og LR-operanden går tilbake fra subrutinen til anropskoden.
IKKE SANT
RET-opkoden i ARM 64 omhandler fortsatt subrutinen, men fungerer annerledes enn RTS i 6502 eller RET på x64, eller 'BX LR'-kombinasjonen i ARM 64. I ARM 64 er syntaksen for RET:
RETT {Xn}
Denne instruksjonen gir programmet muligheten til å fortsette med en subrutine som ikke er subrutinen som ringer, eller bare fortsette med en annen instruksjon og dens følgende kodesegment. Xn er et generell register som inneholder adressen som programmet skal fortsette til. Denne instruksen forgrener seg ubetinget. Den er standard til innholdet i X30 hvis Xn ikke er gitt.
Prosedyre Call Standard
Hvis programmereren vil at koden hans skal samhandle med en kode som er skrevet av noen andre eller med en kode som er produsert av en kompilator, må programmereren bli enig med personen eller kompilatorskriveren om reglene for registerbruk. For ARM-arkitekturen kalles disse reglene Procedure Call Standard eller PCS. Dette er avtaler mellom de to eller tre partene. PCS spesifiserer følgende:
- Hvilke µP-registre brukes til å sende argumentene inn i funksjonen (subrutinen)
- Hvilke µP-registre brukes for å returnere resultatet til funksjonen som kaller opp, som er kjent som anroperen
- Hvilken µP som registrerer funksjonen som blir kalt, som er kjent som callee, kan ødelegge
- Hvilken µP registrerer den som kaller, kan ikke ødelegge
6.49 Avbryter
Det er to typer avbruddskontrollerkretser tilgjengelig for ARM-prosessoren:
- Standard avbruddskontroller: Avbruddsbehandleren bestemmer hvilken enhet som krever service ved å lese et punktgrafikkregister for enheten i avbruddskontrolleren.
- Vector Interrupt Controller (VIC): Prioriterer avbruddene og forenkler bestemmelsen av hvilken enhet som forårsaket avbruddet. Etter å ha assosiert en prioritet og en behandleradresse med hvert avbrudd, hevder VIC bare et avbruddssignal til prosessoren hvis prioriteten til et nytt avbrudd er høyere enn den for øyeblikket utførende avbruddsbehandleren.
Merk : Unntak refererer til feil. Detaljene for vektoravbruddskontrolleren for 32-biters ARM-datamaskinen er som følger (64-biters ligner):
| Tabell 6.49.1 ARM-vektorunntak/avbrudd for 32-biters datamaskin |
|||
|---|---|---|---|
| Unntak/avbrudd | Kort hånd | Adresse | Høy adresse |
| Nullstille | NULLSTILLE | 0x00000000 | 0xffff0000 |
| Udefinert instruksjon | UNDEF | 0x00000004 | 0xffff0004 |
| Programvareavbrudd | SWI | 0x00000008 | 0xffff0008 |
| Forhåndshent avbryt | pabt | 0x0000000C | 0xffff000C |
| Abort dato | DABT | 0x00000010 | 0xffff0010 |
| Forbeholdt | – | 0x00000014 | 0xffff0014 |
| Avbruddsforespørsel | IRQ | 0x00000018 | 0xffff0018 |
| Rask avbruddsforespørsel | FIQ | 0x0000001C | 0xffff001C |
Dette ser ut som arrangementet for 6502-arkitekturen hvor NMI , BR , og IRQ kan ha pekere på side null, og de tilsvarende rutinene er høyt oppe i minnet (ROM OS). Korte beskrivelser av radene i den forrige tabellen er som følger:
NULLSTILLE
Dette skjer når prosessoren slås på. Den initialiserer systemet og setter opp stablene for forskjellige prosessormoduser. Det er det høyest prioriterte unntaket. Ved innføring i tilbakestillingsbehandleren er CPSR i SVC-modus og både IRQ- og FIQ-biter er satt til 1, og maskerer eventuelle avbrudd.
DATO FOR ABORT
Den nest høyeste prioritet. Dette skjer når vi prøver å lese/skrive til en ugyldig adresse eller få tilgang til feil tilgangstillatelse. Når du går inn i Data Abort Handler, vil IRQ-ene bli deaktivert (I-bit sett 1) og FIQ vil bli aktivert. IRQ-ene er maskert, men FIQ-ene holdes umaskerte.
FIQ
Avbruddet med høyest prioritet, IRQ og FIQ, er deaktivert til FIQ er håndtert.
IRQ
Det høyprioriterte avbruddet, IRQ-behandleren, legges inn bare hvis det ikke er noen pågående FIQ og dataavbrudd.
Forhåndshenting Avbryt
Dette ligner på dataavbrudd, men skjer ved feil ved adressehenting. Ved innreise til behandleren er IRQer deaktivert, men FIQer forblir aktivert og kan skje under en forhåndshentingsavbrudd.
SWI
Et programvareavbrudd (SWI)-unntak oppstår når SWI-instruksjonen utføres og ingen av de andre unntakene med høyere prioritet har blitt flagget.
Udefinert instruksjon
Undefined Instruction-unntaket oppstår når en instruksjon som ikke er i ARM- eller Thumb-instruksjonssettet når utføringsstadiet av rørledningen og ingen av de andre unntakene har blitt flagget. Dette er samme prioritet som SWI som man kan skje om gangen. Dette betyr at instruksjonen som utføres ikke både kan være en SWI-instruksjon og en udefinert instruksjon på samme tid.
ARM Unntakshåndtering
Følgende hendelser oppstår når et unntak skjer:
- Lagre CPSR til SPSR for unntaksmodus.
- PC er lagret i LR for unntaksmodus.
- Koblingsregisteret settes til en bestemt adresse basert på gjeldende instruksjon. For eksempel: for ISR, LR = sist utførte instruksjon + 8.
- Oppdater CPSR om unntaket.
- Sett PC-en til adressen til unntaksbehandleren.
6.5 Instruksjoner og data
Data refererer til variabler (etiketter med deres verdier) og arrays og andre strukturer som ligner array. Strengen er som en rekke tegn. En rekke heltall er sett i et av de foregående kapitlene. Instruksjoner refererer til opkoder og deres operander. Et program kan skrives med op-kodene og data blandet i en fortsettelse av minnet. Den tilnærmingen har ulemper, men anbefales ikke.
Et program bør skrives med instruksjonene først, etterfulgt av dataene (flertall av datum er data). Skillet mellom instruksjonene og dataene kan bare være noen få byte. For et program kan både instruksjonene og dataene være i en eller to separate seksjoner i minnet.
6.6 Harvard-arkitekturen
En av de tidlige datamaskinene heter Harvard Mark I (1944). En streng Harvard-arkitektur bruker ett adresseområde for programinstruksjoner og et annet separat adresseområde for data. Dette betyr at det er to separate minner. Følgende viser arkitekturen:
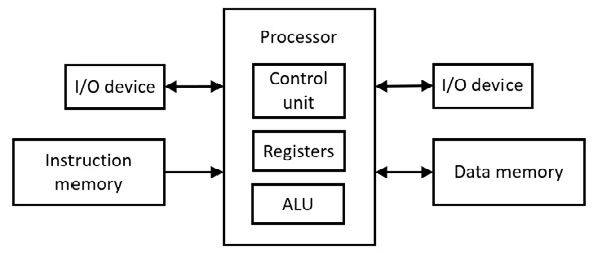
Figur 6.71 Harvard-arkitektur
Kontrollenheten utfører instruksjonsdekodingen. Den aritmetiske logiske enheten (ALU) utfører de aritmetiske operasjonene med kombinasjonslogikk (porter). ALU gjør også de logiske operasjonene (f.eks. skifting).
Med 6502-mikroprosessoren går en instruksjon først til mikroprosessoren (kontrollenheten) før datumet (entall for data) går til µP-registeret før de samhandler. Dette trenger minst to klokkepulser og det er ikke en samtidig tilgang til instruksjonen og datumet. På den annen side gir Harvard-arkitekturen samtidig tilgang til instruksjonene og dataene, med både instruksjon og datum som går inn i µP på samme tid (opkode til kontrollenhet og datum til µP-register), og sparer minst én klokkepuls. Dette er en form for parallellisme. Denne formen for parallellitet brukes i maskinvarebufferen i moderne hovedkort (se følgende diskusjon).
6.7 Bufferminne
Cache Memory (RAM) er en høyhastighets minneregion (sammenlignet med hastigheten til hovedminnet) som midlertidig lagrer programinstruksjonene eller dataene for fremtidig bruk. Bufferminnet fungerer raskere enn hovedminnet. Vanligvis blir disse instruksjonene eller dataelementene hentet fra det nylige hovedminnet og vil sannsynligvis bli nødvendig igjen om kort tid. Hovedformålet med hurtigbufferminnet er å øke hastigheten på gjentatt tilgang til de samme hovedminneplasseringene. For å være effektiv må tilgangen til de bufrede elementene være betydelig raskere enn å få tilgang til den opprinnelige kilden til instruksjonene eller dataene, som refereres til som Backing Store.
Når caching er i bruk, begynner hvert forsøk på å få tilgang til en hovedminneplassering med et søk i cachen. Hvis den forespurte varen er til stede, henter og bruker prosessoren umiddelbart. Dette kalles et cache-treff. Hvis cache-søket ikke lykkes (en cache-miss), må instruksjonen eller dataelementet hentes fra backing-lageret (hovedminnet). I prosessen med å hente det forespurte elementet, legges en kopi til hurtigbufferen for en forventet bruk i nær fremtid.
Minnestyringsenhet
Memory Management Unit (MMU) er en krets som administrerer hovedminnet og tilhørende minneregistre på hovedkortet. Tidligere var det en egen integrert krets på hovedkortet; men i dag er det vanligvis en del av mikroprosessoren. MMU skal også administrere cachen (kretsen) som også er en del av mikroprosessoren i dag. Cache-kretsen er en separat integrert krets i fortiden.
Statisk RAM
Statisk RAM (SRAM) har en betydelig raskere tilgangstid enn DRAM, om enn på bekostning av betydelig mer komplekse kretser. SRAM-bitcellene tar opp mye mer plass på den integrerte kretsformen enn cellene til en DRAM-enhet som er i stand til å lagre en tilsvarende mengde data. Hovedminnet (RAM) består vanligvis av DRAM (dynamisk RAM).
Bufferminnet forbedrer datamaskinens ytelse fordi mange algoritmer som kjøres av operativsystemer og applikasjoner viser referanselokaliteten. The Locality of Reference refererer til gjenbruk av data som nylig har blitt åpnet. Dette omtales som Temporal Locality. På et moderne hovedkort er cache-minnet i samme integrerte krets som mikroprosessoren. Hovedminnet (DRAM) er langt og er tilgjengelig via bussene. Referanselokaliteten refererer også til romlig lokalitet. Den romlige lokaliteten har å gjøre med den høyere hastigheten på datatilgang på grunn av fysisk nærhet.
Som regel er cache-minneområdene små (i antall byteplasseringer) sammenlignet med backing-lageret (hovedminnet). Bufferminneenhetene er designet for maksimal hastighet, noe som generelt betyr at de er mer komplekse og kostbare per bit enn datalagringsteknologien som brukes i støttelageret. På grunn av deres begrensede størrelse har cache-minneenhetene en tendens til å fylles raskt. Når en hurtigbuffer ikke har en tilgjengelig plassering for å lagre en ny oppføring, må en eldre oppføring forkastes. Bufferkontrolleren bruker en buffererstatningspolicy for å velge hvilken bufferoppføring som skal overskrives av den nye oppføringen.
Målet med mikroprosessorens hurtigbufferminne er å maksimere prosentandelen av hurtigbuffertreff over tid, og dermed gi den høyeste vedvarende hastigheten for instruksjonsutførelse. For å oppnå dette målet, må bufringslogikken bestemme hvilke instruksjoner og data som skal plasseres i hurtigbufferen og beholdes for nær fremtidig bruk.
En prosessor sin hurtigbufferlogikk har ikke sikkerhet for at et bufret dataelement noen gang vil bli brukt igjen når det har blitt satt inn i hurtigbufferen.
Logikken til caching er avhengig av sannsynligheten for at på grunn av temporal (gjentakende over tid) og romlig (rom) lokalitet, er det en veldig god sjanse for at de hurtigbufrede dataene vil få tilgang til i nær fremtid. I praktiske implementeringer på moderne prosessorer forekommer cachetreff vanligvis på 95 til 97 prosent av minnetilgangene. Siden ventetiden til hurtigbufferminnet er en liten brøkdel av ventetiden til DRAM, fører en høy hurtigbuffertrefffrekvens til en betydelig ytelsesforbedring sammenlignet med en hurtigbufferfri design.
Noe parallellisme med cache
Som nevnt tidligere har et godt program i minnet instruksjonene atskilt fra dataene. I noen hurtigbuffersystemer er det en hurtigbufferkrets til 'venstre' av prosessoren, og det er en annen hurtigbufferkrets til 'høyre' av prosessoren. Den venstre cachen håndterer instruksjonene til et program (eller en applikasjon), og den høyre cachen håndterer dataene til det samme programmet (eller samme applikasjon). Dette fører til bedre økt hastighet.
6.8 Prosesser og tråder
Både CISC- og RISC-datamaskiner har prosesser. En prosess er på programvaren. Et program som kjører (utfører) er en prosess. Operativsystemet kommer med egne programmer. Mens datamaskinen er i drift, kjører også programmene til operativsystemet som gjør at datamaskinen fungerer. Dette er operativsystemprosesser. Brukeren eller programmereren kan skrive sine egne programmer. Når brukerens program kjører, er det en prosess. Det spiller ingen rolle om programmet er skrevet på assemblerspråk eller på høynivåspråk som C eller C++. Alle prosesser (bruker eller OS) administreres av en annen prosess kalt en 'planlegger'.
En tråd er som en delprosess som tilhører en prosess. En prosess kan starte og splittes i tråder og fortsetter deretter som én prosess. En prosess uten tråder kan betraktes som hovedtråden. Prosesser og deres tråder administreres av den samme planleggeren. Planleggeren i seg selv er et program når den er bosatt på OS-disken. Når du kjører i minnet, er planleggeren en prosess.
6.9 Multiprosessering
Tråder administreres nesten som prosesser. Multiprosessering betyr å kjøre mer enn én prosess samtidig. Det finnes datamaskiner med bare én mikroprosessor. Det finnes datamaskiner med mer enn én mikroprosessor. Med en enkelt mikroprosessor bruker prosessene og/eller trådene den samme mikroprosessoren på en interleaving (eller tidsskjærende) måte. Det betyr at en prosess bruker prosessoren og stopper uten å fullføre. En annen prosess eller tråd bruker prosessoren og stopper uten å fullføre. Deretter bruker en annen prosess eller tråd mikroprosessoren og stopper uten å fullføre. Dette fortsetter til alle prosessene og trådene som ble satt i kø av planleggeren har hatt en del av prosessoren. Dette omtales som samtidig multiprosessering.
Når det er mer enn én mikroprosessor, er det en parallell multiprosessering, i motsetning til samtidighet. I dette tilfellet kjører hver prosessor en bestemt prosess eller tråd, forskjellig fra hva den andre prosessoren kjører. Alle prosessorene på samme hovedkort kjører sine forskjellige prosesser og/eller forskjellige tråder samtidig i parallell multiprosessering. Prosessene og trådene i parallell multiprosessering administreres fortsatt av planleggeren. Parallell multiprosessering er raskere enn samtidig multiprosessering.
På dette tidspunktet kan leseren lure på hvordan parallell behandling er raskere enn samtidig behandling. Dette er fordi prosessorene deler (må bruke til forskjellige tider) samme minne og inn-/utgangsporter. Vel, med bruk av cache, er den generelle driften av hovedkortet raskere.
6.10 Personsøking
Memory Management Unit (MMU) er en krets som er nær mikroprosessoren eller i mikroprosessorbrikken. Den håndterer minnekartet eller personsøking og andre minneproblemer. Verken 6502 µP eller Commodore-64-datamaskinen har en MMU i seg selv (selv om det fortsatt er noe minnebehandling i Commodore-64). Commodore-64 håndterer minnet ved å søke der hver side er 256 10 byte lang (100 16 byte lang). Det var ikke obligatorisk for den å håndtere minnet ved å søke. Det kan fortsatt bare ha et minnekart og deretter programmer som bare passer seg inn i de forskjellige utpekte områdene. Vel, personsøking er en måte å gi en effektiv bruk av minnet uten å ha mange minneseksjoner som ikke kan ha data eller program.
x86 386-datamaskinarkitekturen ble utgitt i 1985. Adressebussen er 32-bits bred. Altså totalt 2 32 = 4.294.967.296 adresseplass er mulig. Denne adresseplassen er delt inn i 1 048 576 sider = 1 024 KB sider. Med dette antallet sider består én side av 4 096 byte = 4 KB. Følgende tabell viser de fysiske adressesidene for x86 32-bits arkitekturen:
| Tabell 6.10.1 Fysisk adresserbare sider for x86-arkitekturen |
||
|---|---|---|
| Base 16 adresser | Sider | Base 10 adresser |
| FFFFF000 – FFFFFFFF | Side 1 048 575 | 4 294 963 200 – 4 294 967 295 |
| FFFFE000 – FFFFEFFF | Side 1 044 479 | 4 294 959 104 – 4 294 963 199 |
| FFFFD000 – FFFFDFFF | Side 1 040 383 | 4 294 955 008 – 4 294 959 103 |
| | | | |
| | | |
| | | |
| 00002000 – 00002FFF | Side 2 | 8 192 – 12 288 |
| 00001000 – 00001FFF | Side 1 | 4.096 – 8.191 |
| 00000000 – 00000FFF | Side 0 | 0 – 4.095 |
En søknad består i dag av mer enn ett program. Ett program kan ta mindre enn en side (mindre enn 4096), eller det kan ta to eller flere sider. Så en applikasjon kan ta en eller flere sider der hver side er 4096 byte lang. Ulike personer kan skrive en søknad, med hver person tildelt en eller flere sider.
Legg merke til at side 0 er fra 00000000H til 00000FFF
side 1 er fra 00001000H til 00001FFFH, side 2 er fra 00002000 H – 00002FFF H , og så videre. For en 32-bits datamaskin er det to 32-bits registre i prosessoren for fysisk sideadressering: ett for baseadressen og det andre for indeksadressen. For å få tilgang til byteplasseringene på side 2, for eksempel, bør registeret for baseadressen være 00002 H som er de første 20 bitene (fra venstre) for startadressene på side 2. Resten av bitene i området 000 H til FFF H er i registeret kalt 'indeksregisteret'. Så alle bytene på siden kan nås ved å bare øke innholdet i indeksregisteret fra 000 H til FFF H . Innholdet i indeksregisteret legges til innholdet som ikke endres i basisregisteret for å få den effektive adressen. Dette indeksadresseskjemaet gjelder for de andre sidene.
Men det er egentlig ikke slik assembly-språkprogrammet er skrevet for hver side. For hver side skriver programmereren koden fra side 000 H til side FFF H . Siden koden på forskjellige sider er koblet sammen, bruker kompilatoren indeksadresseringen for å koble alle de relaterte adressene på forskjellige sider. For eksempel, forutsatt at side 0, side 1 og side 2 er for én applikasjon og hver har 555 H adresse som er koblet til hverandre, kompilerer kompilatoren på en slik måte at når 555 H av side 0 skal åpnes, 00000 H vil være i basisregisteret og 555 H vil stå i indeksregisteret. Når 555 H av side 1 skal åpnes, 00001 H vil være i basisregisteret og 555 H vil stå i indeksregisteret. Når 555 H av side 2 skal åpnes, 00002 H vil være i basisregisteret og 555H vil være i indeksregisteret. Dette er mulig fordi adressene kan identifiseres ved hjelp av etiketter (variabler). De forskjellige programmererne må bli enige om navnet på etikettene som skal brukes for de forskjellige tilkoblingsadressene.
Side Virtuelt minne
Personsøking, som tidligere beskrevet, kan modifiseres for å øke størrelsen på minnet i en teknikk som omtales som 'Page Virtual Memory'. Forutsatt at alle de fysiske minnesidene, som tidligere beskrevet, har noe (instruksjoner og data), er ikke alle sidene aktive for øyeblikket. Sidene som for øyeblikket ikke er aktive sendes til harddisken og erstattes av sidene fra harddisken som må kjøres. På den måten øker størrelsen på minnet. Ettersom datamaskinen fortsetter å fungere, byttes sidene som blir inaktive med sidene på harddisken som fortsatt kan være sidene som ble sendt fra minnet til disken. Alt dette gjøres av Memory Management Unit (MMU).
6.11 Problemer
Leseren anbefales å løse alle oppgavene i et kapittel før han går videre til neste kapittel.
1) Gi likhetene og forskjellene til CISC- og RISC-datamaskinarkitekturene. Nevn ett eksempel på hver SISC- og RISC-datamaskin.
2) a) Hva er følgende navn for CISC-datamaskinen når det gjelder bits: byte, ord, dobbeltord, fireord og dobbelt fireord.
b) Hva er følgende navn for RISC-datamaskinen når det gjelder biter: byte, halvord, ord og dobbeltord.
c) Ja eller Nei. Betyr doubleword og quadword de samme tingene i både CISC og RISC arkitekturer?
3 a) For x64 varierer antall byte for assembly-språkinstruksjonene fra hva til hva?
b) Er antall byte for alle monteringsspråkinstruksjoner for ARM 64 fast? Hvis ja, hva er antallet byte for alle instruksjoner?
4) List opp de mest brukte assembly-språkinstruksjonene for x64 og deres betydning.
5) List opp de mest brukte monteringsspråkinstruksjonene for ARM 64 og deres betydning.
6) Tegn et merket blokkdiagram av den gamle datamaskinen Harvard Architecture. Forklar hvordan instruksjonene og datafunksjonene brukes i hurtigbufferen til moderne datamaskiner.
7) Skille mellom en prosess og en tråd og gi navnet på prosessen som håndterer prosessene og trådene i de fleste datasystemer.
8) Forklar kort hva som er multiprosessering.
9) a) Forklar personsøking som er relevant for x86 386 µP datamaskinarkitektur.
b) Hvordan kan denne personsøkingen endres for å øke størrelsen på hele minnet?