Optimalisering av Python-koden med profileringsverktøy
Når vi setter opp Google Colab for å optimalisere Python-koden med profileringsverktøy, begynner vi med å sette opp et Google Colab-miljø. Hvis vi er nye til Colab, er det en viktig, kraftig skybasert plattform som gir tilgang til Jupyter-notebooks og en rekke Python-biblioteker. Vi får tilgang til Colab ved å besøke (https://colab.research.google.com/) og lage en ny Python-notisbok.
Importer profilbibliotekene
Vår optimering er avhengig av dyktig bruk av profileringsbiblioteker. To viktige biblioteker i denne sammenhengen er cProfile og line_profiler.
import cProfil
import line_profiler
'cProfile'-biblioteket er et innebygd Python-verktøy for profilering av kode, mens 'line_profiler' er en ekstern pakke som lar oss gå enda dypere, analysere koden linje for linje.
I dette trinnet lager vi et eksempel på et Python-skript for å beregne Fibonacci-sekvensen ved å bruke en rekursiv funksjon. La oss analysere denne prosessen i større dybde. Fibonacci-sekvensen er et sett med tall der hvert påfølgende tall er summen av de to før det. Den starter vanligvis med 0 og 1, så sekvensen ser ut som 0, 1, 1, 2, 3, 5, 8, 13, 21 og så videre. Det er en matematisk sekvens som ofte brukes som et eksempel i programmering på grunn av dens rekursive natur.
Vi definerer en Python-funksjon kalt 'Fibonacci' i den rekursive Fibonacci-funksjonen. Denne funksjonen tar et 'n' heltall som argument, som representerer posisjonen i Fibonacci-sekvensen som vi ønsker å beregne. Vi ønsker å finne det femte tallet i Fibonacci-sekvensen, for eksempel hvis 'n' er lik 5.
def fibonacci ( n ) :
Deretter etablerer vi en base case. Et basistilfelle i rekursjon er et scenario som avslutter samtalene og returnerer en forhåndsbestemt verdi. I Fibonacci-sekvensen, når 'n' er 0 eller 1, vet vi allerede resultatet. 0. og 1. Fibonacci-tallene er henholdsvis 0 og 1.
hvis n <= 1 :komme tilbake n
Denne 'hvis'-setningen bestemmer om 'n' er mindre enn eller lik 1. Hvis den er det, returnerer vi selve 'n', siden det ikke er behov for ytterligere rekursjon.
Rekursiv beregning
Hvis 'n' overstiger 1, fortsetter vi med den rekursive beregningen. I dette tilfellet må vi finne det 'n'-te Fibonacci-tallet ved å summere det '(n-1)' og '(n-2)'-te Fibonacci-tallet. Dette oppnår vi ved å foreta to rekursive anrop innenfor funksjonen.
ellers :komme tilbake fibonacci ( n - 1 ) + fibonacci ( n - 2 )
Her beregner “fibonacci(n – 1)” det “(n-1)”th Fibonacci-tallet, og “fibonacci(n – 2)” beregner det “(n-2)”th Fibonacci-tallet. Vi legger til disse to verdiene for å få ønsket Fibonacci-nummer i 'n'-posisjon.
Oppsummert beregner denne 'fibonacci'-funksjonen rekursivt Fibonacci-tallene ved å dele opp problemet i mindre underoppgaver. Den foretar rekursive anrop til den når basistilfellene (0 eller 1), og returnerer kjente verdier. For alle andre 'n' beregner den Fibonacci-tallet ved å summere resultatene av to rekursive anrop for '(n-1)' og '(n-2)'.
Selv om denne implementeringen er enkel å beregne Fibonacci-tallene, er den ikke den mest effektive. I de senere trinnene vil vi bruke profileringsverktøyene til å identifisere og optimalisere ytelsesbegrensningene for bedre utførelsestider.
Profilering av koden med CProfile
Nå profilerer vi vår 'fibonacci'-funksjon ved å bruke 'cProfile'. Denne profileringsøvelsen gir innsikt i tiden som brukes av hvert funksjonskall.
cprofiler = cProfil. Profil ( )cprofiler. muliggjøre ( )
resultat = fibonacci ( 30 )
cprofiler. deaktiver ( )
cprofiler. print_stats ( sortere = 'kumulativ' )
I dette segmentet initialiserer vi et 'cProfile'-objekt, aktiverer profileringen, ber om 'fibonacci'-funksjonen med 'n=30', deaktiverer profileringen og viser statistikken som er sortert etter kumulativ tid. Denne første profileringen gir oss en oversikt på høyt nivå over hvilke funksjoner som bruker mest tid.
! pip install line_profilerimport cProfil
import line_profiler
def fibonacci ( n ) :
hvis n <= 1 :
komme tilbake n
ellers :
komme tilbake fibonacci ( n - 1 ) + fibonacci ( n - 2 )
cprofiler = cProfil. Profil ( )
cprofiler. muliggjøre ( )
resultat = fibonacci ( 30 )
cprofiler. deaktiver ( )
cprofiler. print_stats ( sortere = 'kumulativ' )
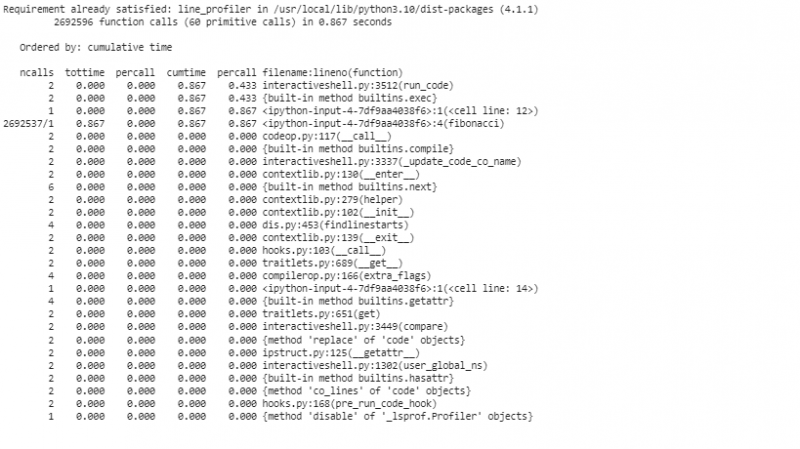
For å profilere koden linje for linje med line_profiler for en mer detaljert analyse, bruker vi 'line_profiler' for å segmentere koden linje for linje. Før vi bruker 'line_profiler', må vi installere pakken i Colab-depotet.
! pip install line_profilerNå som vi har 'line_profiler' klar, kan vi bruke den på vår 'fibonacci'-funksjon:
%load_ext line_profilerdef fibonacci ( n ) :
hvis n <= 1 :
komme tilbake n
ellers :
komme tilbake fibonacci ( n - 1 ) + fibonacci ( n - 2 )
%lprun -f fibonacci fibonacci ( 30 )
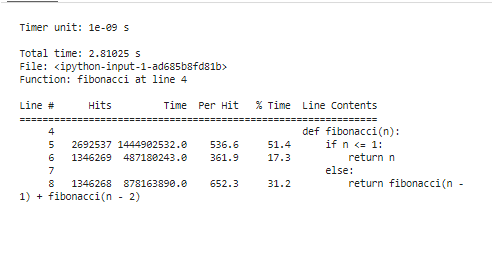
Denne kodebiten begynner med å laste 'line_profiler'-utvidelsen, definerer 'fibonacci'-funksjonen vår, og til slutt bruker '%lprun' for å profilere 'fibonacci'-funksjonen med 'n=30'. Den tilbyr en linje-for-linje-segmentering av utførelsestider, og tømmer nøyaktig hvor koden vår bruker ressursene sine.
Etter å ha kjørt profileringsverktøyene for å analysere resultatene, vil den bli presentert med en rekke statistikker som viser kodens ytelsesegenskaper. Denne statistikken involverer den totale tiden som brukes innenfor hver funksjon og varigheten av hver kodelinje. For eksempel kan vi skille at Fibonacci-funksjonen bruker litt mer tid på å beregne de identiske verdiene på nytt flere ganger. Dette er den overflødige beregningen, og det er et klart område hvor optimalisering kan brukes, enten gjennom memoisering eller ved å bruke de iterative algoritmene.
Nå foretar vi optimaliseringer der vi identifiserte en potensiell optimalisering i Fibonacci-funksjonen vår. Vi la merke til at funksjonen beregner de samme Fibonacci-tallene på nytt flere ganger, noe som resulterer i unødvendig redundans og langsommere utførelsestid.
For å optimere dette implementerer vi memoiseringen. Memoisering er en optimaliseringsteknikk som innebærer å lagre de tidligere beregnede resultatene (i dette tilfellet Fibonacci-tall) og gjenbruke dem ved behov i stedet for å beregne dem på nytt. Dette reduserer de redundante beregningene og forbedrer ytelsen, spesielt for rekursive funksjoner som Fibonacci-sekvensen.
For å implementere memoiseringen i Fibonacci-funksjonen vår, skriver vi følgende kode:
# Ordbok for å lagre beregnede Fibonacci-tallfib_cache = { }
def fibonacci ( n ) :
hvis n <= 1 :
komme tilbake n
# Sjekk om resultatet allerede er bufret
hvis n i fib_cache:
komme tilbake fib_cache [ n ]
ellers :
# Beregn og cache resultatet
fib_cache [ n ] = fibonacci ( n - 1 ) + fibonacci ( n - 2 )
komme tilbake fib_cache [ n ] ,
I denne modifiserte versjonen av 'fibonacci'-funksjonen introduserer vi en 'fib_cache'-ordbok for å lagre de tidligere beregnede Fibonacci-tallene. Før vi beregner et Fibonacci-tall, sjekker vi om det allerede er i hurtigbufferen. Hvis det er det, returnerer vi det bufrede resultatet. I alle andre tilfeller beregner vi den, holder den i hurtigbufferen og returnerer den.
Gjenta profilering og optimalisering
Etter å ha implementert optimaliseringen (memoisering i vårt tilfelle), er det avgjørende å gjenta profileringsprosessen for å vite virkningen av endringene våre og sikre at vi forbedret kodens ytelse.
Profilering etter optimalisering
Vi kan bruke de samme profileringsverktøyene, 'cProfile' og 'line_profiler', for å profilere den optimaliserte Fibonacci-funksjonen. Ved å sammenligne de nye profileringsresultatene med de tidligere, kan vi måle effektiviteten til optimaliseringen vår.
Slik kan vi profilere den optimaliserte 'fibonacci'-funksjonen ved å bruke 'cProfile':
cprofiler = cProfil. Profil ( )cprofiler. muliggjøre ( )
resultat = fibonacci ( 30 )
cprofiler. deaktiver ( )
cprofiler. print_stats ( sortere = 'kumulativ' )
Ved å bruke «line_profiler» profilerer vi den linje for linje:
%lprun -f fibonacci fibonacci ( 30 )Kode:
# Ordbok for å lagre beregnede Fibonacci-tallfib_cache = { }
def fibonacci ( n ) :
hvis n <= 1 :
komme tilbake n
# Sjekk om resultatet allerede er bufret
hvis n i fib_cache:
komme tilbake fib_cache [ n ]
ellers :
# Beregn og cache resultatet
fib_cache [ n ] = fibonacci ( n - 1 ) + fibonacci ( n - 2 )
komme tilbake fib_cache [ n ]
cprofiler = cProfil. Profil ( )
cprofiler. muliggjøre ( )
resultat = fibonacci ( 30 )
cprofiler. deaktiver ( )
cprofiler. print_stats ( sortere = 'kumulativ' )
%lprun -f fibonacci fibonacci ( 30 )
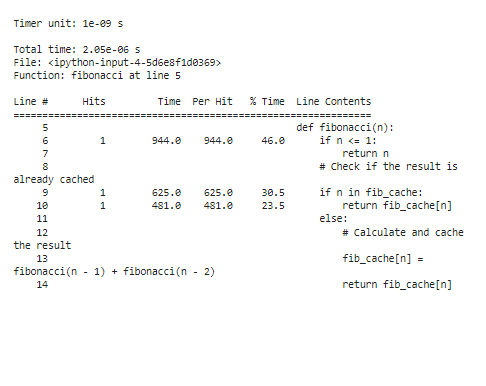
For å analysere profileringsresultatene etter optimalisering, vil det være betydelig reduserte utførelsestider, spesielt for store 'n'-verdier. På grunn av memoisering observerer vi at funksjonen nå bruker langt mindre tid på å beregne Fibonacci-tallene på nytt.
Disse trinnene er avgjørende i optimaliseringsprosessen. Optimalisering innebærer å gjøre informerte endringer i koden vår basert på observasjonene som oppnås fra profilering, mens gjentatt profilering sikrer at optimaliseringene våre gir de forventede ytelsesforbedringene. Ved iterativ profilering, optimalisering og validering kan vi finjustere Python-koden vår for å levere bedre ytelse og forbedre brukeropplevelsen av applikasjonene våre.
Konklusjon
I denne artikkelen diskuterte vi eksemplet der vi optimaliserte Python-koden ved hjelp av profileringsverktøy i Google Colab-miljøet. Vi initialiserte eksemplet med oppsettet, importerte de essensielle profileringsbibliotekene, skrev eksempelkodene, profilerte det ved å bruke både 'cProfile' og 'line_profiler', beregnet resultatene, brukte optimaliseringene og foredlet kodens ytelse iterativt.