Denne artikkelen gir brukerne en dypere forståelse for implementering av Data Warehouse med AWS Redshift.
Hva er AWS Redshift?
AWS Redshift lar brukerne hente og manipulere dataene uten alle konfigurasjonene til en tradisjonell database. Den skalerer kapasiteten på en intelligent måte avhengig av applikasjonens krav, gir raske og nøyaktige svar og administreres fullt ut av AWS. AWS Redshift er mye brukt for sine enorme applikasjoner for Big Data Analysing. Videre følger den betal-som-du-bruk-modellen og påløper ikke ekstra kostnader når lageret står ubrukt:
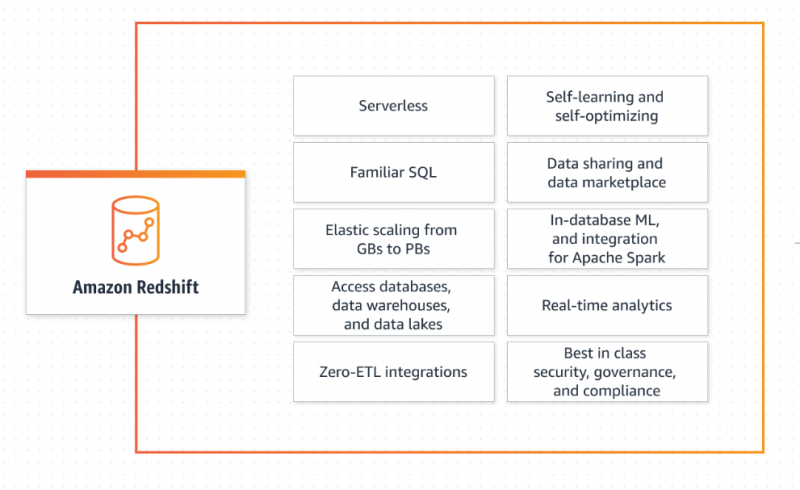
Lær mer om Redshift ved å referere til denne artikkelen: 'Hva er Amazon Redshift-datatypene' :
Hvordan implementere datavarehus med Amazon Redshift?
Amazon Redshift bruker Standard Query Language (SQL) på tvers av forskjellige varehus for å utføre spørringer. Å trekke ut maksimale verdier mens du overvåker kostnadene ved å manuelt sette opp et datavarehus er slitsomt. Derfor øker AWS Redshift nøyaktig og intelligent din datarelaterte forretningsoppgave og hjelper deg med å akselerere tiden din til å få innsikt i data på en rask, enkel, pålitelig og sikker måte. Det er mange fordeler med å implementere datavarehus med Amazon Redshift:
- Datakryptering
- Intelligent optimalisering
- Kostnadsoptimal
- Automatiser repeterende oppgaver
- Kapasitet for automatisk skalering
- Støtte til ulike AWS-ressurser
Nedenfor er noen trinn der vi kan implementere datavarehus med Amazon Redshift:
Trinn 1: Opprett en IAM-rolle
Det første trinnet i å implementere et datavarehus på AWS rødskifte begynner med å opprette en IAM-rolle. For dette formålet, søk og velg IAM-rollen på AWS-administrasjonskonsoll :
Klikk på 'Roller' alternativ fra sidefeltet til IAM-rollen:
Klikk på 'Skap rolle' knappen neste:
I Klarert enhetstype seksjonen, klikk på “AWS-tjeneste” mens vi oppretter denne IAM-rollen for Redshift:
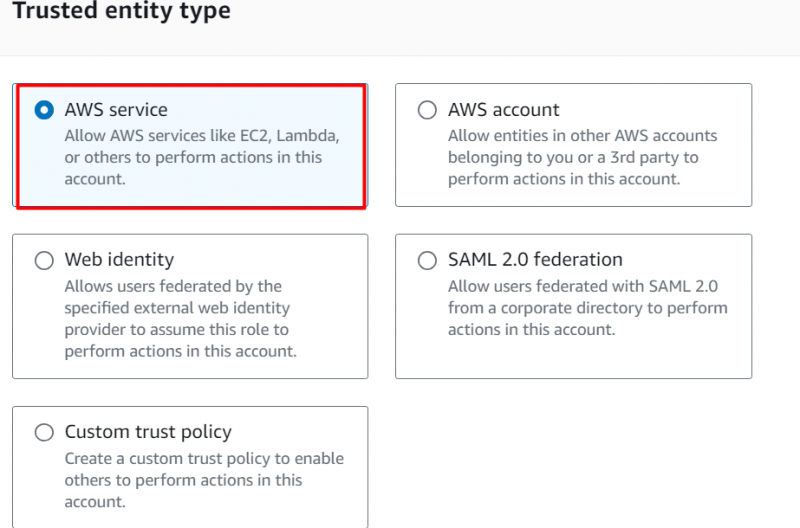
I Bruk case seksjon , plukke ut 'Rødskift' i det uthevede feltet og fortsett for å velge følgende uthevede alternativ. Klikk på 'Neste' knappen etterpå:
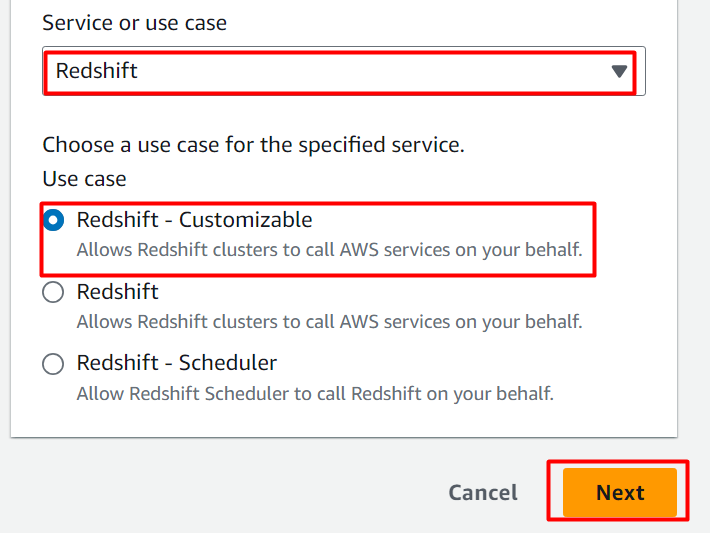
I Tillatelsespolicy seksjon , søk og velg 'AmazonS3ReadOnly Access' alternativ. Og klikk deretter på 'Neste' knappen etterpå:
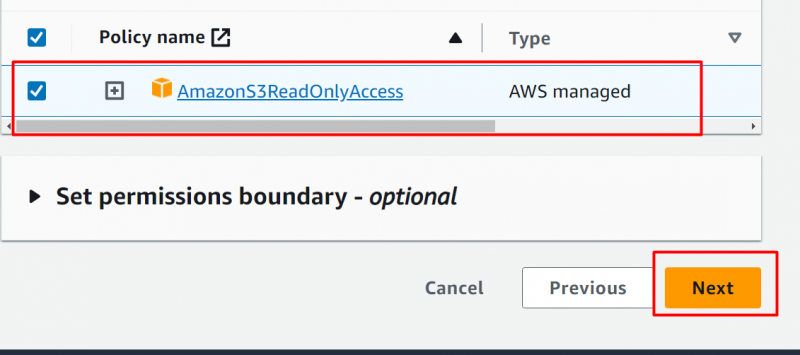
I Rolledetaljer seksjon , oppgi navnet på rollen:
Beholder resten av innstillinger som standard, Klikk på 'Skap rolle' knappen nederst i grensesnittet:
Rollen har vært vellykket opprettet. Klikk på 'Se rolle' knapp:
I Se rolle seksjon, kopiere RNA og lagre den i Notisblokk for fremtidig bruk:
Trinn 2: Opprett Redshift Cluster
På AWS Management Console, søk og velg deretter 'Rødskift' service:
Rull nedover 'Rødskift' hovedkonsollen og klikk på 'Opprett klynge' knapp:
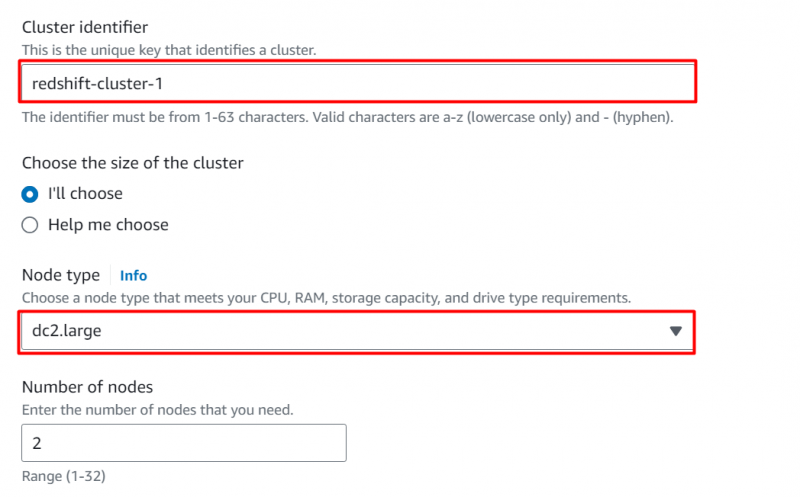
Dette vil navigere brukeren til 'Opprett klynge' grensesnitt. Her på dette grensesnittet, oppgi et navn for klyngen og velg «dc.2 stor» for klyngetypen:
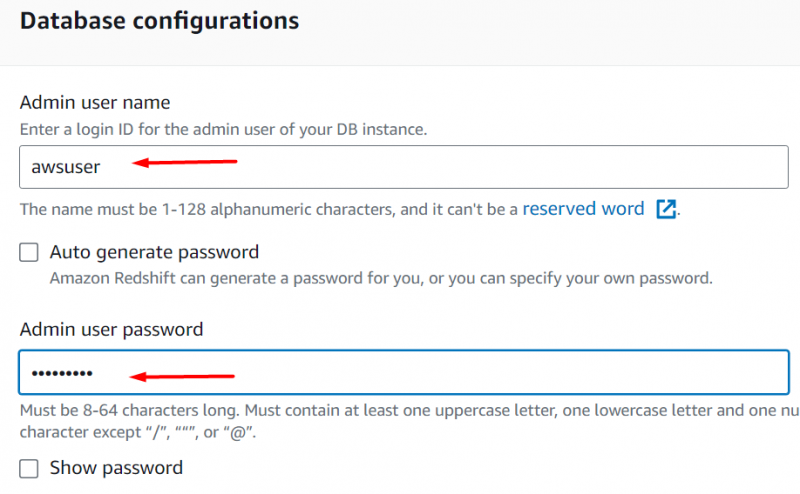
I Databasekonfigurasjoner seksjoner, gi en brukernavn og passord for klyngen:
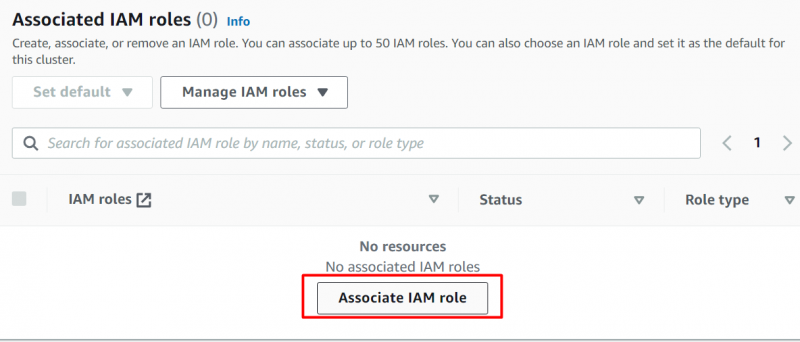
Rull ned til IAM-roller seksjon. Vi vil legge ved IAM-rollen her som vi opprettet tidligere i denne opplæringen. For dette formålet, klikk på 'Associate IAM-rolle' knapp:
I denne delen har vi valgt rollen som er opprettet og klikket på 'Associate IAM-roller' knappen for å legge ved rollen:
Behold standardinnstillingene, klikk på 'Opprett klynge' knappen nederst i grensesnittet:
Dette vil ta litt tid før klyngen er tilgjengelig. Klikk på klyngens navn fra RDS Dashboard etter at statusen vises 'Aktiv':
Trinn 3: Legg til tillatelser
Få tilgang til IAM-tjeneste fra AWS Management Console til konfigurere en ny policy i root-brukerkontoen:
Fra IAM Dashboard, Klikk på 'Brukere' alternativ fra venstre sidefelt:
Klikk på Rollenavn som har administratortilgang til kontoen:
Trykk på 'Legg til tillatelser' knappen plassert på grensesnittet:
Klikk på 'Legg ved retningslinjer direkte' alternativet under Alternativer for tillatelser seksjon:
Legg til følgende tillatelser til kontoen din:
- AmazonRedshiftQueryEditor
- AmazonRedshiftQueryEditorV2FullAccess
- AmazonRedshiftReadOnly Access
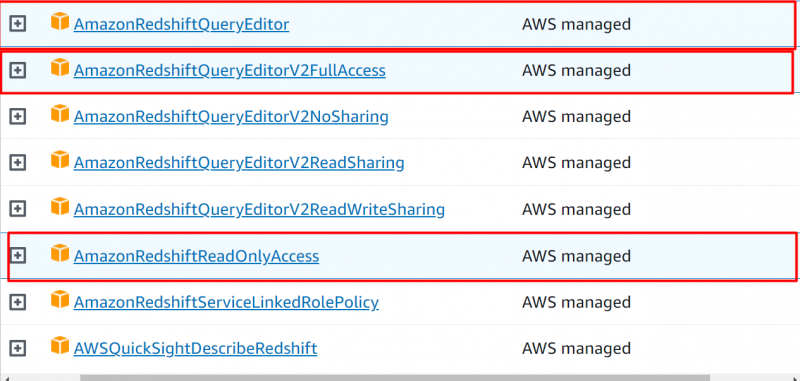
Etter å ha lagt til følgende tillatelser, klikk på 'Neste' knapp:
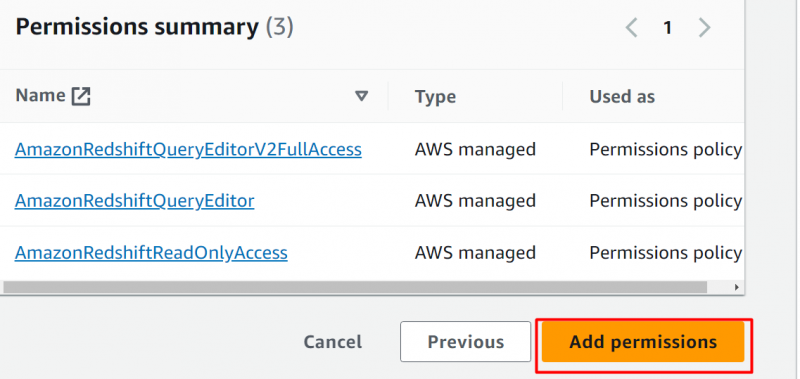
I Oppsummering av tillatelser seksjonen, klikk på 'Legg til tillatelser' knapp:
Her er tillatelsene konfigurert:
Trinn 4: Spørringsredigering
På AWS RDS Dashboard , Klikk på 'Query editor v2' alternativ fra sidefeltet:
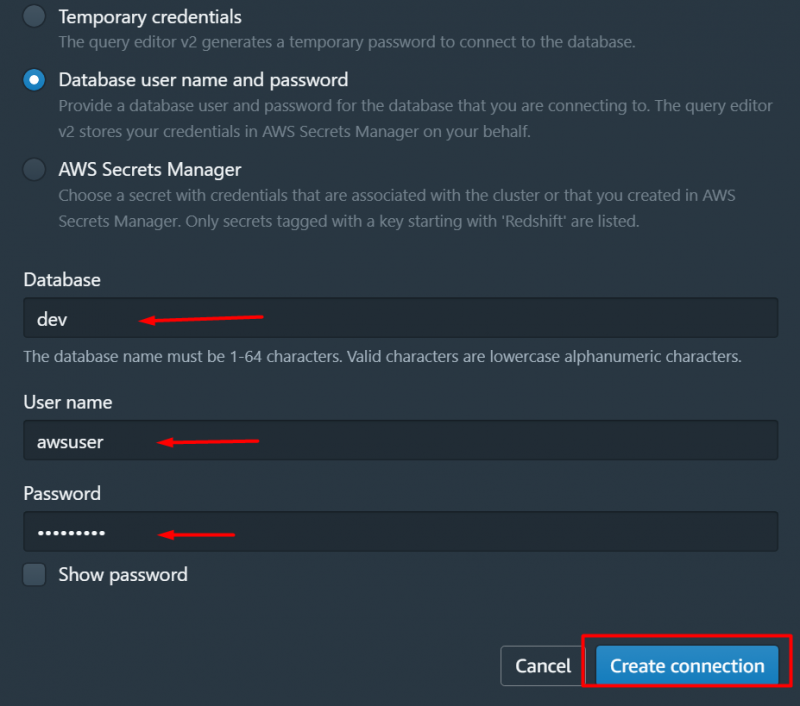
Dette vil vise følgende grensesnitt. På dette grensesnittet velger du navnet på klyngen din og oppgir følgende detaljer for tilkoblingen. Etter å ha oppgitt detaljene, klikk på 'Opprett tilkobling' knapp:
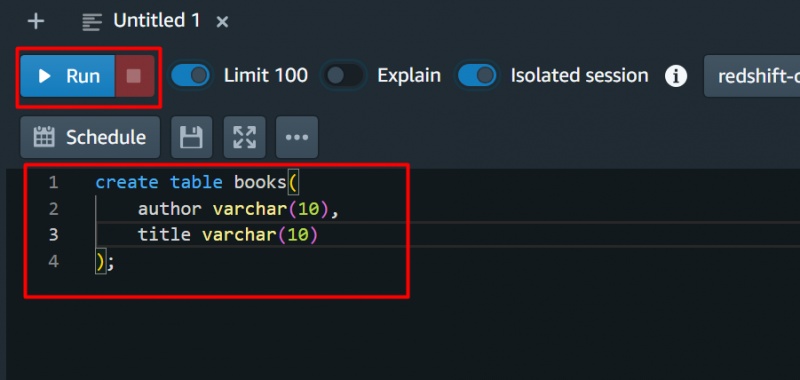
For testformål vil vi gi følgende spørring og trykke på 'Løpe' knapp:
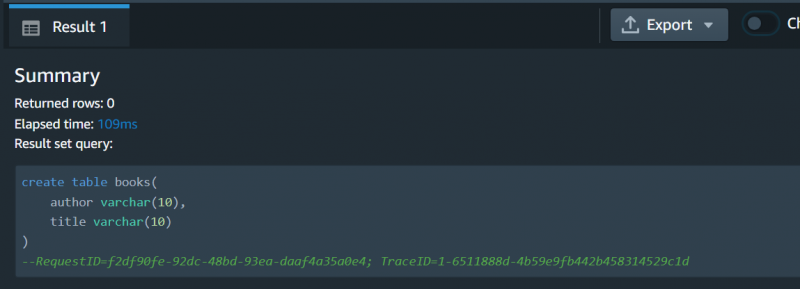
Spørringen er utført vellykket:
Det er alt fra denne guiden. Nå kan brukeren kjøre forskjellige spørringer i denne konsollen, f.eks. Opprett, sett inn, slett, etc.
Konklusjon
For å opprette datavarehus med Redshift, konfigurer en IAM-rolle og tillatelse med RDS-klyngen og klikk på ' Spørringsredaktør alternativet for å utføre spørringer. AWS Redshift er en skybasert database som følger syntaksen til SQL og utfører spørringer på store datasett effektivt for høy ytelse. Denne artikkelen gir instruksjoner for implementering av datavarehus med Amazon Redshift.