Amazon Redshift er en skyløsning som tilbys av AWS som oppfyller formålet med et datavarehus. Et datavarehus er et stort rom i skyen som lagrer enorme mengder data. Forskjellen mellom et datavarehus og en database er at førstnevnte ikke bare lagrer nåværende data, men også den fullstendige historien til dataene.
Denne artikkelen vil lære om Amazon Redshift av AWS og datatypene som denne tjenesten støtter.
Hva er Amazon RedShift?
Det er en skyløsning til datavarehus som er basert på 'PostgreSQL' . Den bruker en teknologi som heter 'Massively Parallell Processing (MPP)' å behandle petabyte med data lynraskt. Dette gir en enkel løsning for sanntidsprediksjon basert på historiske data og strømmeløsninger.
Følgende figur viser arbeidsmekanismen til Amazon Redshift:
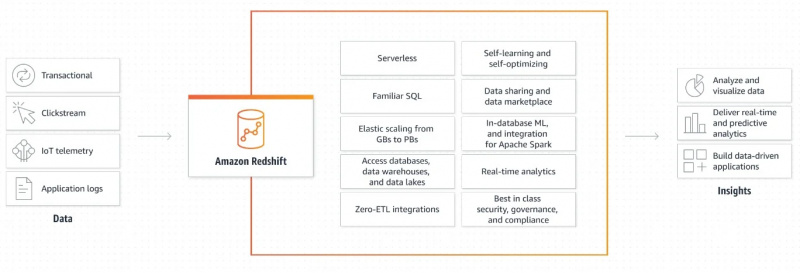
Denne grafiske forklaringen på hvordan Amazon Redshift fungerer er veldig enkel og oversiktlig. Den gir oss informasjon om hvordan data hentes og viderebehandles for å generere utdata og lage datadrevne applikasjoner.
Datavarehusarkitekturen til Amazon Redshift kan også sees i figuren nedenfor:
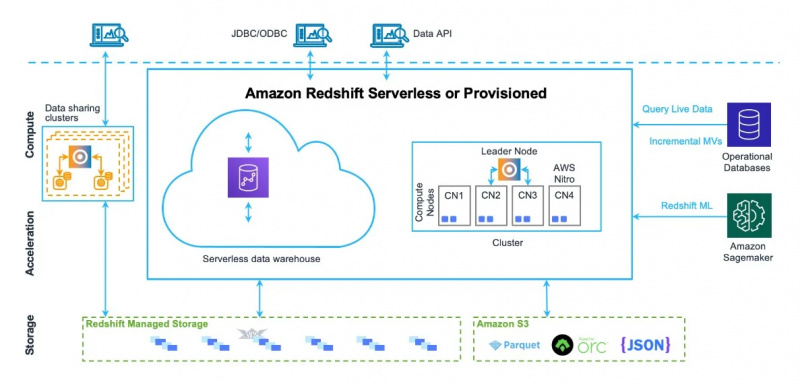
Nå skal vi gå til bruken og funksjonene til denne tjenesten.
Egenskaper
Som allerede nevnt er Amazon Redshift basert på PostgreSQL og bruker en teknologi kalt Massively Parallel Processing som gjør det mulig å behandle petabyte med data på kort tid. Derfor tilbyr Redshift en god del funksjoner og bruksområder. Noen av disse funksjonene er nedenfor:
- Datasikkerhet og kryptering.
- Business Analytics.
- Datadrevet applikasjonsstøtte.
- Prediktiv analyse.
- Automatisert oppgaverepetisjon.
- Samtidig dataskalering.
- Datavarehus.
Noen ekstra funksjoner til denne tjenesten kan sees i figuren nedenfor:
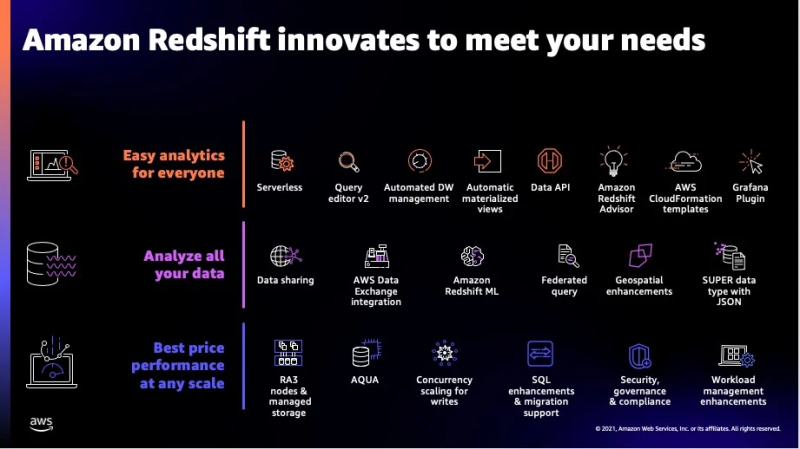
Dette var de fleste funksjonene som Redshift tilbyr, og nå vil vi gå over til datatypene som støttes av denne tjenesten.
Datatyper
Amazon Redshift er en datavarehusløsning med et stort antall funksjoner. Den støtter både strukturerte og ustrukturerte datatyper. Siden den er basert på PostgreSQL, kan dataene manipuleres gjennom enkle SQL-spørringer.
Nå oppstår et annet spørsmål, dvs. hvordan disse dataformatene skiller seg fra hverandre? La oss diskutere disse to dataformatene.
Strukturerte data
En svært formatert datatype som lett kan oversettes av maskinlæringsalgoritmer kalles strukturerte data. En SQL-database fungerer med strukturerte data. Strukturerte data er i tabellform, for eksempel data som brukes av relasjonsdatabaser
Et av de mye brukte SQL-databasestyringssystemene er MYSQL. Arkitekturen kan sees nedenfor i den gitte figuren:
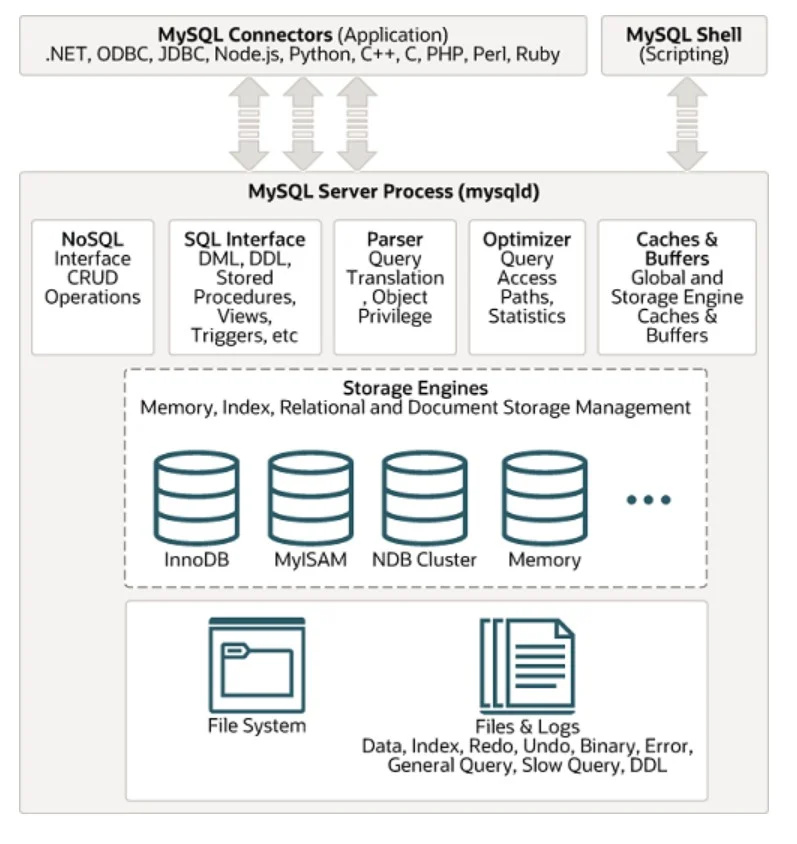
Ustrukturerte data
Ustrukturerte data er mønstermindre og formater mindre data som data brukt i ikke-relasjonelle databaser. MongoDB er en kjent ikke-relasjonell database. SQL-spørringer fungerer ikke på ikke-relasjonelle databaser, så disse databasene kalles også NoSQL-databaser.
Som allerede nevnt, er MongoDB et ikke-strukturert databasestyringssystem, og dets arkitektur kan sees nedenfor i den gitte figuren:
Vi har gått gjennom de to grunnleggende datatypene som brukes i databaser, og vi vil nå gå til de faktiske datatypene som støttes av Amazon Redshift. Disse datatypene er:
- Numeriske data
- Karakterdata
- Dato og klokkeslett
- boolske data
- HLLSKETCH Data
- SUPER data
- ERSTATTNING Data
La oss diskutere disse datatypene:
Numeriske data
Denne datatypen er selvforklarende. Den støtter data som er i form av heltall, desimaler, flytende komma og andre numeriske datatyper.
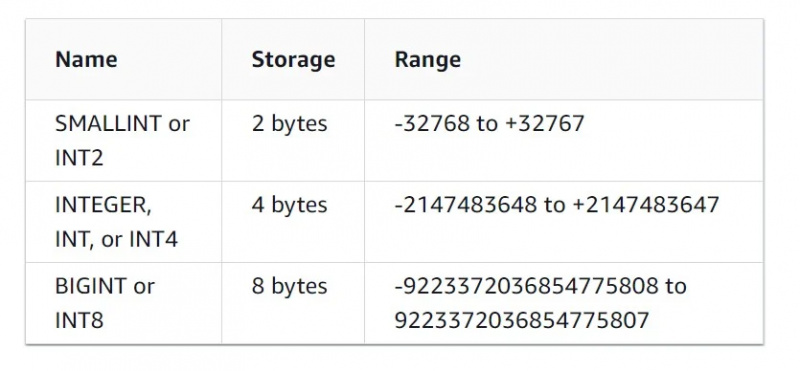
Egenskapene til heltallsdatatypen kan sees i figuren nedenfor:
Desimal datatype lagrer dataene basert på presisjon fra brukeren. Dens egenskaper er som følger:

Karakterdata
CHAR- og VARCHAR-datatyper faller inn under kategorien tegnbaserte datatyper. NCHAR og NVARCHAR er også tegntypedatatyper. I motsetning til CHAR og VARCHAR, lagrer disse to datatypene Unicode-tegn med fast lengde. La oss se på egenskapene til disse datatypene, for eksempel:
- CHAR, CHARACTER, NCHAR har en rekkevidde på 4KB.
- VARCHAR, NVARCHAR har en rekkevidde på 64KB.
- BPCHAR har en rekkevidde på 256 byte.
- TEXT har en rekkevidde på 260 byte.
Dato og klokkeslett
Dato- og klokkeslettdatatyper er DATE, TIME, TIMETZ, TIMESTAMP, TIMESTAMPTZ. De funksjonelle egenskapene til disse datatypene er som følger:
- DATE lagrer ganske enkelt kalenderdatoer.
- TIME lagrer tid uten referanse til noen tidssone. Det er UTC, som standard.
- TIMETZ lagrer tid i forhold til tidssonen. Det er UTC i både brukertabellene og systemtabellene som standard.
- TIMESTAMP inkluderer ikke bare tid, men også datoer. Det er UTC i både brukertabellene og systemtabellene, som standard.
- TIMESTAMPTZ inkluderer ikke bare tid, men også datoer. Det er UTC i bare brukertabeller, som standard.
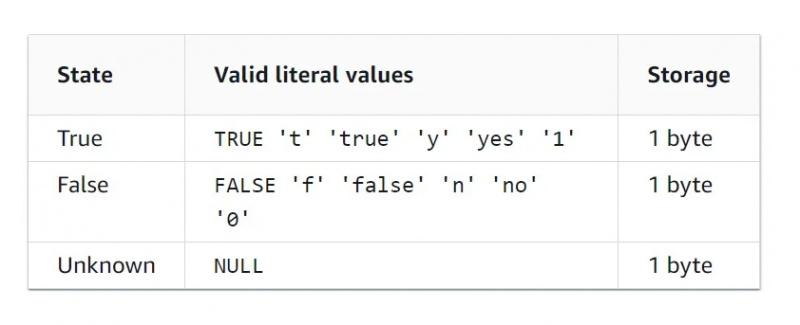
boolske data
Boolsk datatype er en binær datatype, som betyr at det bare er to verdier. Egenskapstabellen for boolsk datatype er gitt nedenfor i figuren:
HLLSKETCH Data
Denne datatypen brukes til å lagre skisser. Rødforskyvning kan representere skissene i enten sparsom eller tett form. Skisser starter som sparsomme og blir gradvis tette når et tett format gir mer effektivitet ved å følge lenken.
SUPER data
Denne datatypen omhandler ustrukturerte data som kan være i form av arrays, nestede strukturer eller JSON. Det er ingen modell eller format for dataene. Brukere kan utforske mer informasjon ved å navigere på lenken.
ERSTATTNING Data
Denne datatypen lagrer også tegn. Lengden er imidlertid begrenset. Amazon Redshift tillater casting av VARBYTE-data til alle heltalls- eller tegntypedata. For å få mer informasjon om denne datatypen, følg lenken nedenfor.
Dette er alt som er til Amazon Redshift og datatypene den støtter.
Konklusjon
Amazon Redshift er en AWS-tjeneste som i sin grunnleggende form tjener formålet med et datavarehus, men er en veldig kraftig og funksjonsrik løsning for analyser og prediksjon. Denne artikkelen har diskutert Redshift og datatypene den støtter. Disse datatypene ble kort forklart sammen med deres egenskaper.