Navnekonvensjoner representerer en viktig del av koding. Det er prosessen med å velge passende navn for funksjoner, variabler, klasser og andre programenheter. Navnekonvensjoner forbedrer kodelesbarheten og -forståelsen, slik at den blir enklere å vedlikeholde og tilpasse i fremtiden. Den neste delen vil gå gjennom C++ navnekonvensjoner.
Hva er navnekonvensjon i C++?
Navnestandarder i C++ involverer ofte bruk av visse prefikser eller suffikser, kamelbokstaver, store bokstaver for variabler og begynnelsesnavn på klasser med store bokstaver. Målet med disse konvensjonene har som mål å holde koden mer konsistent og lettere å lese, slik at andre programmerere raskt og enkelt kan forstå den.
Ulik navnekonvensjon for variabler
I C++ er noen typiske praksiser for variabelnavn:
1: Variablenavn bør være beskrivende og signifikant, som beskriver nøyaktig hva variabelen representerer.
2: Kamelkasse: Det er en stil der den første bokstaven i et ord er liten, og den første bokstaven i hvert påfølgende ord er stor, uten tomme mellomrom mellom ordene. I C++ brukes denne konvensjonen ofte for variabelnavn.
3: Bruk av 'er' for å prefikse boolske variabler: Det er vanlig å prefiksere en variabels navn med 'er' eller 'har' for å indikere at den representerer en boolsk verdi.
4: Konstantene må navngis med alle store bokstaver og understrek blant ord for å indikere at de ikke er ment å bli oppdatert.
5: Pascal Case: Denne saken ligner på kamelsaken. Den eneste forskjellen mellom begge er at startbokstaven til det innledende ordet på samme måte må være stor i Pascals tilfelle. I motsetning til kamelbokstaven, der det innledende ordet er med små bokstaver, hvis du bruker Pascal-bokstaver, begynner hvert ord med en stor bokstav.
Nedenfor er et eksempel på navnekonvensjoner i C++, slik at du enkelt kan forstå konseptet med navnekonvensjon.
Eksempel: C++-program for å vise variabler med forskjellige navnekonvensjoner
Følgende er en enkel C++-programimplementering som viser de ovennevnte variabelnavnekonvensjonene:
#includebruker navneområde std;
int main ( ) {
// med beskrivende navn på variabler
int totalNumber = 100 ;
// med kamelbok med variabelnavn
string nameOfStudent = 'Han selv' ;
// Prefikser booleske variabler 'er'
bool isEmployed = falsk ;
bool er avkrysset = ekte ;
// Bruke alle store bokstaver til konstante variabler
const int HIGHEST_ASSIGNMENT = 100 ;
const dobbel PI_VALUE = 3.14 ;
// navnekonvensjon for variabelen gjennom pascal sak
string FinalResultOfStudent = 'Sende' ;
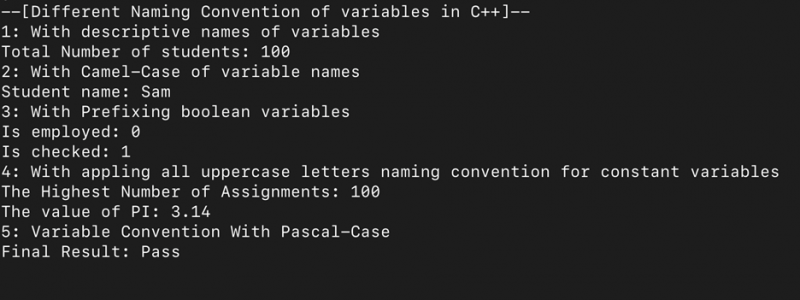
cout << '--[Ulik navnekonvensjon for variabler i C++]--' << endl;
cout << '1: Med beskrivende navn på variabler' << endl;
cout << 'Totalt antall studenter: ' << totaltAntall << endl;
cout << '2: Med Camel-Case av variabelnavn' << endl;
cout << 'Student navn: ' << navn på student << endl;
cout << '3: Med prefiks for boolske variabler' << endl;
cout << 'Er ansatt:' << er ansatt << endl;
cout << 'Er sjekket:' << er avkrysset << endl;
cout << '4: Med bruk av alle store bokstaver navnekonvensjon for konstante variabler' << endl;
cout << 'Det høyeste antallet oppdrag: ' << HIGHEST_ASSIGNMENT << endl;
cout << 'Verdien av PI: ' << PI_VALUE << endl;
cout << '5: Variabel konvensjon med Pascal-Case' << endl;
cout << 'Endelig resultat: ' << Sluttresultat av student << endl;
komme tilbake 0 ;
}
Dette programmet erklærte ganske enkelt variabel syntaks i henhold til de ovennevnte fem navnekonvensjonene. I hovedfunksjonen er den første variabelen totalNumber som er i henhold til beskrivende navnekonvensjon som skriver ut 100 verdier som utdata. Next nameOfStudent-variabelen initialiseres med Mickle Steve som viser Navnekonvensjon for Camel Case.
Variablene isEmployed og isChecked viste det boolske resultatet som utdata som representerer Navnekonvensjon for prefiks. Etter dette initialiseres variablene HIGHEST_ASSIGNMENT og PI_VALUE med respekterte verdier som 100 og 3.14 som definerer stor bokstav i navnekonvensjonen .
Til slutt representerer FinalResultOfStudent-variabelen Pasal kasuskonvensjon for navngivingsvariabler. Dette enkle programmet brukte navnekonvensjonen en etter en som er nevnt ovenfor og skriv dem ut på konsollen ved å bruke cout som vist i følgende utgang:
Merk: Disse navnekonvensjonene hjelper andre programmerere til å forstå kildekoden raskere og lettere ved å gjøre den standardisert og mindre vanskelig å lese.
Konklusjon
Navnekonvensjoner er kritiske i programmering siden de hjelper til med kodeforståelse og vedlikehold. For å garantere enhetlighet og klarhet, bør C++-utviklere følge spesifiserte navnemønstre. Å følge disse reglene kan gjøre koden lettere å lese og endre, og redusere sjansene for feil og defekter. Ved å følge visse navnekonvensjoner kan programmerere produsere mer effektiv og vedlikeholdbar kode.