Syntaks:
Det finnes en rekke tjenester som Hugging Face tilbyr, men en av de mye brukte tjenestene er 'API'. API tillater interaksjon av forhåndstrente AI og store språkmodeller til forskjellige applikasjoner. Hugging Face gir API-ene for forskjellige modeller som er oppført i følgende:
- Tekstgenereringsmodeller
- Oversettelsesmodeller
- Modeller for analyse av sentimentene
- Modeller for utvikling av virtuelle agenter (intelligente chatbots)
- Klassifisering og regresjonsmodellene
La oss nå oppdage metoden for å få vår personlige inferens-API fra Hugging Face. For å gjøre det, må vi først starte med å registrere oss på den offisielle nettsiden til Hugging Face. Bli med i dette fellesskapet til Hugging Face ved å registrere deg på denne nettsiden med legitimasjonen din.
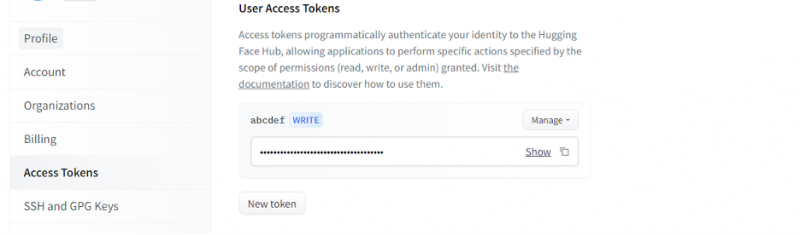
Når vi får en konto på Hugging Face, må vi nå be om inferens-API. For å be om API, gå til kontoinnstillingene og velg 'Access Token'. Et nytt vindu åpnes. Velg alternativet 'New Token' og generer deretter tokenet ved først å oppgi navnet på tokenet og dets rolle som 'WRITE'. Et nytt token genereres. Nå må vi lagre dette symbolet. Inntil dette punktet har vi vårt token fra Hugging Face. I det neste eksemplet vil vi se hvordan vi kan bruke dette tokenet til å få et inferens-API.
Eksempel 1: Hvordan prototyper med Hugging Face Inference API
Så langt har vi diskutert metoden for hvordan komme i gang med Hugging Face, og vi initialiserte et token fra Hugging Face. Dette eksemplet viser hvordan vi kan bruke dette nygenererte tokenet til å få en slutnings-API for en spesifikk modell (maskinlæring) og lage spådommer gjennom den. Fra hjemmesiden til Hugging Face velg hvilken som helst modell du vil jobbe med som er relevant for problemet ditt. La oss si at vi ønsker å jobbe med tekstklassifiseringen eller sentimentanalysemodellen som vist i følgende utdrag av listen over disse modellene:
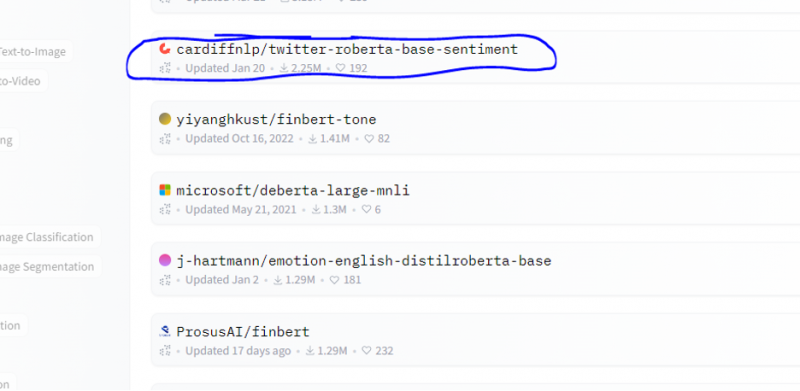
Vi velger sentimentanalysemodellen fra denne modellen.
Etter å ha valgt modell, vises modellkortet. Dette modellkortet inneholder informasjon om treningsdetaljene til modellen og hvilke egenskaper modellen har. Modellen vår er roBERTa-basert som er trent på 58M tweets for sentimentanalyse. Denne modellen har tre hovedklasseetiketter, og den kategoriserer hver inngang i sine relevante klasseetiketter.
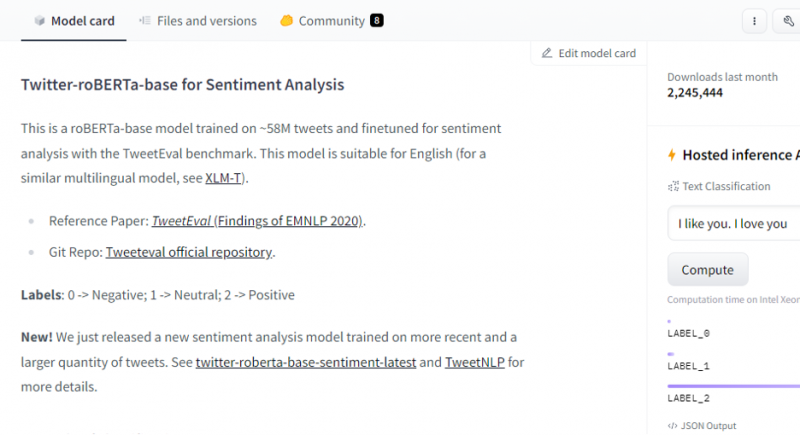
Etter valg av modell, hvis vi velger distribusjonsknappen som er til stede i øverste høyre hjørne av vinduet, åpner den en rullegardinmeny. Fra denne menyen må vi velge alternativet 'Inference API'.
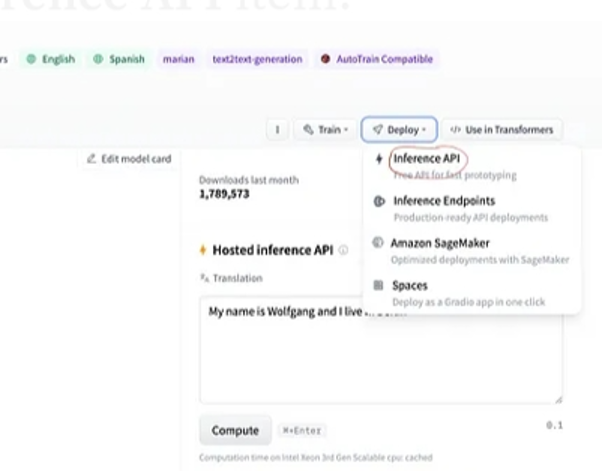
Inferens-APIet gir deretter en hel forklaring på hvordan du bruker denne spesifikke modellen med denne slutningen, og lar oss raskt lage prototypen for AI-modellen. Inferens API-vinduet viser koden som er skrevet i Pythons skript.
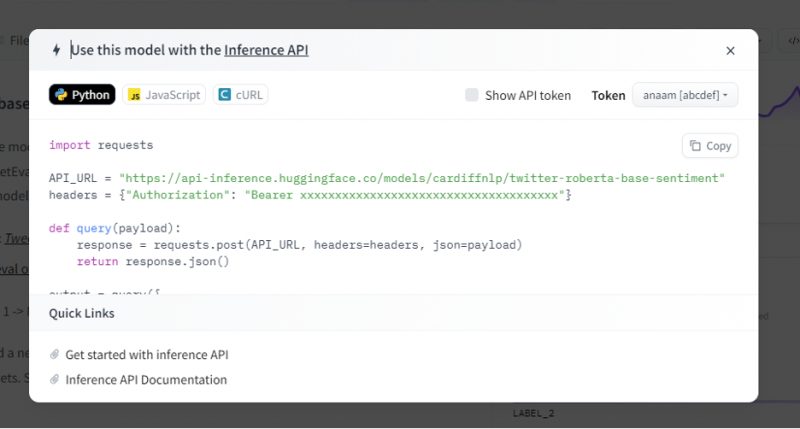
Vi kopierer denne koden og kjører denne koden i hvilken som helst av Python IDE. Vi bruker Google Colab til dette. Etter å ha utført denne koden i Python-skallet, returnerer den en utgang som følger med poengsummen og etikettprediksjonen. Denne merkelappen og poengsummen er gitt i henhold til våre innspill siden vi valgte 'tekst-sentimentanalyse'-modellen. Deretter er inndataene vi gir til modellen en positiv setning, og modellen ble forhåndsopplært på tre etikettklasser: etikett 0 antyder negativ, etikett1 antyder nøytral, og etikett 2 er satt til positiv. Siden innspillet vårt er en positiv setning, er poengprediksjonen fra modellen mer enn de to andre etikettene, noe som betyr at modellen predikerte setningen som en 'positiv'.
import forespørslerAPI_URL = 'https://api-inference.huggingface.co/models/cardiffnlp/twitter-roberta-base-sentiment'
overskrifter = { 'Autorisasjon' : 'Bærer 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' }
def spørsmål ( nyttelast ) :
respons = forespørsler. post ( API_URL , overskrifter = overskrifter , json = nyttelast )
komme tilbake respons. json ( )
produksjon = spørsmål ( {
'innganger' : 'Jeg føler meg bra når du er med meg' ,
} )
Produksjon:

Eksempel 2: Oppsummeringsmodell gjennom slutning
Vi følger de samme trinnene som er vist i forrige eksempel og prototyper oppsummeringsmodellbussen ved å bruke dens slutnings-API fra Hugging Face. Oppsummeringsmodellen er en forhåndstrent modell som oppsummerer hele teksten som vi gir den som input. Gå til Hugging Face-kontoen, klikk på modellen fra den øverste menylinjen, og velg deretter modellen som er relevant for oppsummeringen, velg den og les modellkortet nøye.
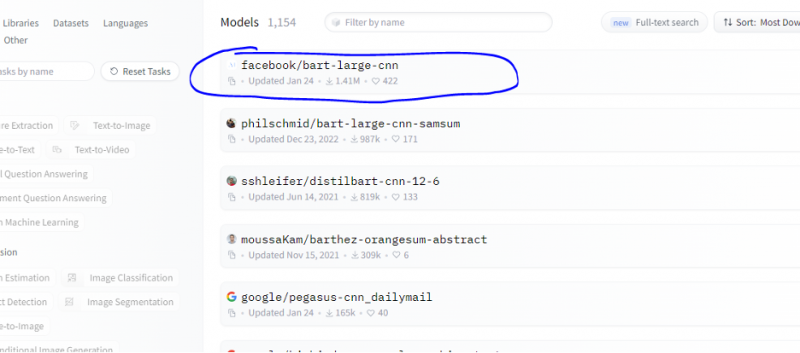
Modellen vi valgte er en forhåndsopplært BART-modell, og den er finjustert til datasettet CNN dail mail. BART er en modell som ligner mest på BERT-modellen som har enkoder og dekoder. Denne modellen er effektiv når den er finjustert for forståelse, oppsummering, oversettelse og tekstgenereringsoppgaver.
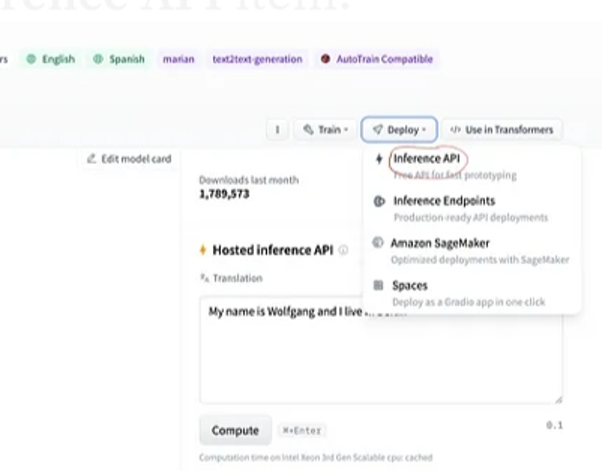
Velg deretter 'distribusjon'-knappen øverst til høyre og velg inferens-API fra rullegardinmenyen. Inference API åpner et annet vindu som inneholder koden og instruksjonene for å bruke denne modellen med denne slutningen.
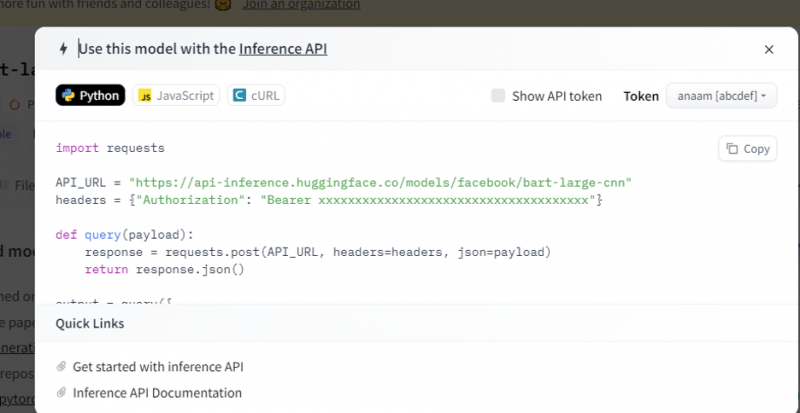
Kopier denne koden og kjør den i et Python-skall.
Modellen returnerer output som er oppsummeringen av input som vi matet til den.

Konklusjon
Vi jobbet med Hugging Face Inference API og lærte hvordan vi kan bruke denne applikasjonens programmerbare grensesnitt til å jobbe med de forhåndstrente språkmodellene. De to eksemplene vi gjorde i artikkelen var hovedsakelig basert på NLP-modellene. Hugging Face API kan gjøre underverker hvis vi ønsker å utvikle en rask prototype ved å tilby rask integrasjon av AI-modeller i applikasjonene våre. Kort sagt, Hugging Face har løsninger på alle dine problemer fra forsterkende læring til datasyn.