Dupliserte data kan ofte føre til forvirring, feil og skjev innsikt. Heldigvis gir Google Sheets oss mange verktøy og teknikker for å forenkle oppgaven med å identifisere og fjerne disse overflødige oppføringene. Fra grunnleggende cellesammenligninger til avanserte formelbaserte tilnærminger, vil du være utstyrt til å forvandle rotete ark til organiserte, verdifulle ressurser.
Enten du håndterer kundelister, undersøkelsesresultater eller andre datasett, er eliminering av dupliserte oppføringer et grunnleggende skritt mot pålitelig analyse og beslutningstaking.
I denne veiledningen skal vi fordype oss i to metoder for å la deg identifisere og fjerne dupliserte verdier.
Oppretting av bord
Vi opprettet først en tabell i Google Sheets, som vil bli brukt i eksemplene senere i denne artikkelen. Denne tabellen har 3 kolonner: Kolonne A, med overskriften 'Navn', lagrer navn; Kolonne B har overskriften 'Alder', som inneholder folks alder; og til slutt, kolonne C, overskriften 'By', inneholder byer. Hvis vi observerer, er noen oppføringer i denne tabellen duplisert, for eksempel oppføringene for 'John' og 'Sara.'
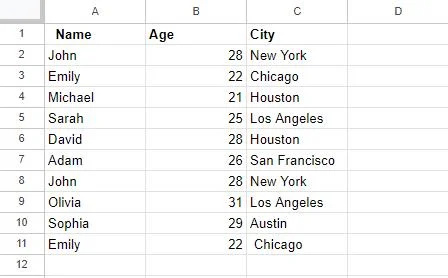
Vi vil jobbe med denne tabellen for å fjerne disse dupliserte verdiene med forskjellige metoder.
Metode 1: Bruk av funksjonen 'Fjern duplikater' i Google Sheets
Den første metoden vi diskuterer her er å fjerne dupliserte verdier ved å bruke Google Sheets 'Fjern duplikater'-funksjonen. Denne metoden vil permanent eliminere dupliserte oppføringer fra det valgte celleområdet.
For å demonstrere denne metoden vil vi igjen vurdere den ovenfor genererte tabellen.
For å begynne å jobbe med denne metoden, må vi først velge hele området som inneholder dataene våre, inkludert overskrifter. I dette scenariet har vi valgt celler A1:C11 .
Øverst i Google Regneark-vinduet ser du en navigasjonslinje med ulike menyer. Finn og klikk på 'Data'-alternativet i navigasjonslinjen.
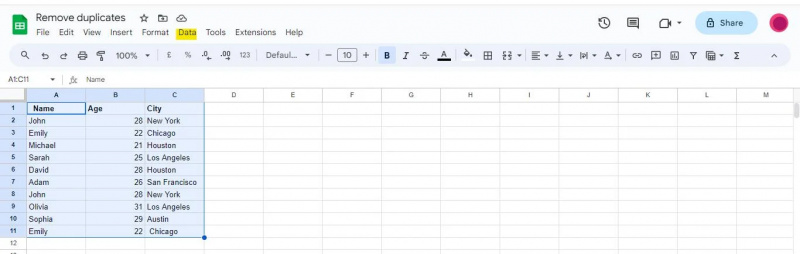
En rullegardinmeny vil vises når du klikker på 'Data'-alternativet, og presenterer deg med ulike datarelaterte verktøy og funksjoner som kan brukes til å analysere, rense og manipulere dataene dine.
For dette eksemplet må vi få tilgang til 'Data'-menyen for å navigere til alternativet 'Data opprydding', som inkluderer funksjonen 'Fjern duplikater'.
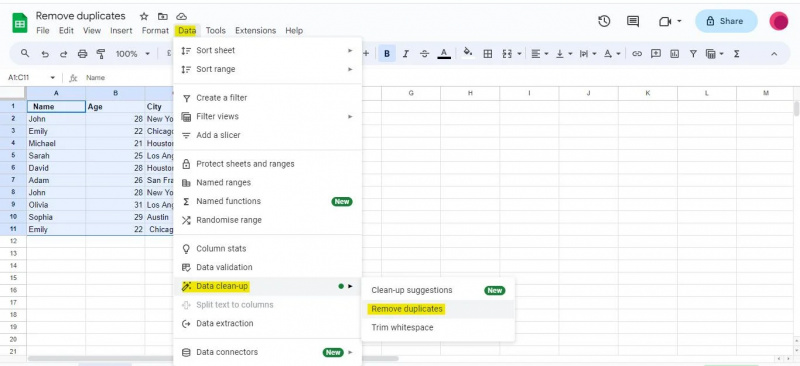
Etter at vi har åpnet dialogboksen 'Fjern duplikater', vil vi bli presentert med en liste over kolonner i datasettet vårt. Basert på disse kolonnene vil duplikater bli funnet og fjernet. Vi markerer de tilsvarende avmerkingsboksene i dialogboksen avhengig av hvilke kolonner vi ønsker å bruke for å identifisere duplikater.
I vårt eksempel har vi tre kolonner: «Navn», «Alder» og «By». Siden vi ønsker å identifisere duplikater basert på alle tre kolonnene, har vi merket av for alle tre avmerkingsboksene. Bortsett fra det, må du merke av for 'Data har overskriftsrad' hvis tabellen din har overskrifter. Siden vi har overskrifter i tabellen ovenfor, har vi merket av for 'Data har overskriftsrad'.
Når vi har valgt kolonnene for å identifisere duplikater, kan vi fortsette å fjerne disse duplikatene fra datasettet vårt.
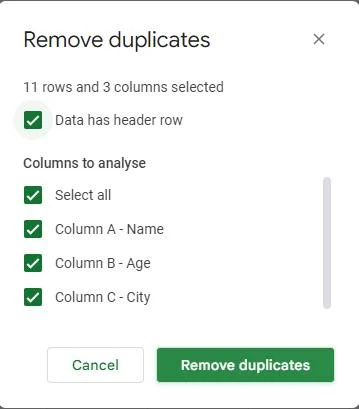
Du finner en knapp nederst i dialogboksen 'Fjern duplikater' merket 'Fjern duplikater.' Klikk på denne knappen.
Etter å ha klikket på «Fjern duplikater», behandler Google Sheets forespørselen din. Kolonnene vil bli skannet, og eventuelle rader med dupliserte verdier i disse kolonnene vil bli fjernet, og duplikater elimineres.
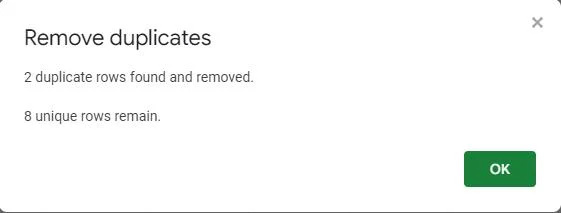
En popup-skjerm bekrefter at de dupliserte verdiene er fjernet fra tabellen. Den viser at to dupliserte rader ble funnet og fjernet, og etterlater tabellen med åtte unike oppføringer.
Etter å ha brukt «Fjern duplikater»-funksjonen, er tabellen vår oppdatert som følger:
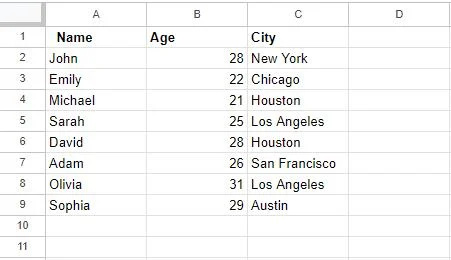
En viktig merknad å vurdere her er at fjerning av duplikater ved hjelp av denne funksjonen er en permanent handling. Dupliserte rader vil bli slettet fra datasettet ditt, og du vil ikke kunne angre denne handlingen med mindre du har en sikkerhetskopi av data. Så sørg for at du har valgt de riktige kolonnene for å finne duplikater ved å dobbeltsjekke valget ditt.
Metode 2: Bruk av UNIQUE-funksjonen for å fjerne duplikater
Den andre metoden vi vil diskutere her er å bruke UNIK funksjon i Google Sheets. De UNIK funksjonen henter distinkte verdier fra et spesifisert område eller kolonne med data. Selv om den ikke fjerner duplikater direkte fra de originale dataene, oppretter den en liste over unike verdier som du kan bruke for datatransformasjon eller -analyse uten duplikater.
La oss lage et eksempel for å forstå denne metoden.
Vi vil bruke tabellen som ble generert i den første delen av denne opplæringen. Som vi allerede vet, inneholder tabellen visse data som er duplisert. Så vi har valgt en celle, 'E2,' for å skrive UNIK formel inn. Formelen vi har skrevet er som følger:
=UNIKK(A2:A11)
Når den brukes i Google Sheets, henter UNIQUE-formelen unike verdier i en egen kolonne. Så vi har gitt denne formelen et område fra celle A2 til A11 , som vil bli brukt i kolonne A. Dermed trekker denne formelen ut de unike verdiene fra kolonnen EN og viser dem i kolonnen der formelen er skrevet.
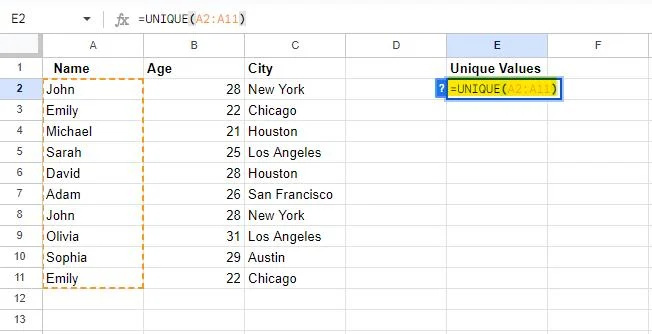
Formelen vil bli brukt på det angitte området når du trykker på Enter-tasten.
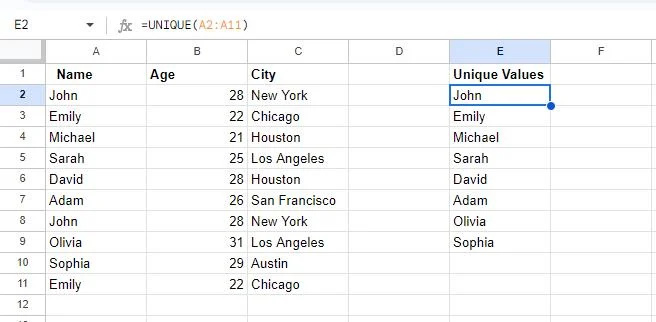
I dette øyeblikksbildet kan vi se at to celler er tomme. Dette er fordi to verdier har blitt duplisert i tabellen, nemlig John og Emily. De UNIK funksjonen viser bare en enkelt forekomst av hver verdi.
Denne metoden fjernet ikke de dupliserte verdiene direkte fra den angitte kolonnen, men opprettet en annen kolonne for å gi oss de unike oppføringene i den kolonnen, og eliminerte duplikatene.
Konklusjon
Å fjerne duplikater i Google Sheets er en fordelaktig metode for å analysere data. Denne veiledningen demonstrerte to metoder som lar deg enkelt fjerne dupliserte oppføringer fra dataene dine. Den første metoden forklarte bruken av Google Sheets for å fjerne duplikatfunksjonen. Denne metoden skanner det angitte celleområdet og eliminerer duplikater. Den andre metoden vi har diskutert er å bruke formelen for å hente dupliserte verdier. Selv om den ikke fjerner duplikater direkte fra området, viser den i stedet de unike verdiene i en ny kolonne.