Denne artikkelen vil diskutere hvordan du bruker Elasticsearch multi-get API for å hente flere JSON-dokumenter basert på ID-ene deres. I tillegg lar Elasticsearch deg bruke en enkelt get-spørring for å hente dokumentene fra indekser ved å bruke kun dokument-ID-ene.
La oss utforske.
Be om syntaks
Følgende er syntaksen for Elasticsearch multi-get API:
FÅ /_mget
GET /
Multi-get API støtter flere indekser som lar deg hente dokumentene selv om de ikke er i samme indeks.
Forespørselen støtter følgende baneparametere:
-
– Navnet på indeksen som dokumentene skal hentes fra som spesifisert av deres IDer.
Du kan også spesifisere de andre spørringsparametrene som vist:
- Preferanse – Definerer den foretrukne noden eller shard.
- Sanntid – Hvis satt til sann, utføres operasjonen i sanntid.
- Forfriske – Tvinger operasjonen til å oppdatere målskårene før de spesifiserte dokumentene hentes.
- Ruting – En verdi som brukes til å rute operasjonene til et spesifikt shard.
- Store_felt – Henter dokumentfeltene som er lagret i en indeks i stedet for dokumentet.
- _kilde – En boolsk verdi som definerer om forespørselen skal returnere _source-feltet eller ikke.
Spørringen krever brødteksten, som inkluderer følgende verdier:
- Dokumenter – Spesifiserer dokumentene du ønsker å hente. I tillegg støtter denne delen følgende attributter:
- _id – Unik ID for måldokumentet.
- _indeks – Indeksen som inneholder måldokumentet.
- Ruting – Nøkkelen for den primære shard av dokumentet.
- _kilde – Hvis sant, inkluderer det alle kildefelt; ellers ekskluderer det dem.
- _lagrede_felt – De lagrede_feltene du ønsker å inkludere.
- Ids – IDene til dokumentene du ønsker å hente.
Eksempel 1: Hent flere dokumenter fra samme indeks
Følgende eksempel viser hvordan du bruker Elasticsearch multi-get API for å hente dokumentene med spesifikke IDer fra Netflix-indeksen:
curl -XGET 'http://localhost:9200/netflix/_mget' -H 'kbn-xsrf: rapportering' -H 'Content-Type: application/json' -d'{
'dokumenter': [
{
'_id': 'T3wnVoMBck2AEzXPytlJ'
},
{
'_id': 'W3wnVoMBck2AEzXPytlJ'
}
]
}'
Den gitte forespørselen skal hente dokumentene med de angitte ID-ene fra Netflix-indeksen. Den resulterende utgangen er som vist:
{'dokumenter': [
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ',
'_versjon': 1,
'_seq_no': 0,
'_primary_term': 1,
'funnet': sant,
'_source': {
'duration': '90 min',
'listed_in': 'Dokumentarer',
'country': 'USA',
'date_added': '25. september 2021',
'show_id': 's1',
'director': 'Kirsten Johnson',
'release_year': 2020,
'rating': 'PG-13',
'description': 'Når faren hennes nærmer seg slutten av livet, iscenesetter filmskaper Kirsten Johnson hans død på oppfinnsomme og komiske måter for å hjelpe dem begge å møte det uunngåelige.',
'type': 'Film',
'title': 'Dick Johnson er død'
}
},
{
'_index': 'netflix',
'_id': 'W3wnVoMBck2AEzXPytlJ',
'_versjon': 1,
'_seq_no': 12,
'_primary_term': 1,
'funnet': sant,
'_source': {
'country': 'Tyskland, Tsjekkia',
'show_id': 's13',
'director': 'Christian Schwochow',
'release_year': 2021,
'rating': 'TV-MA',
'description': 'Etter at mesteparten av familien hennes er myrdet i en terrorbombing, blir en ung kvinne ubevisst lokket til å slutte seg til gruppen som drepte dem.',
'type': 'Film',
'title': 'Jeg er Karl',
'duration': '127 min',
'listed_in': 'Dramaer, internasjonale filmer',
'cast': 'Luna Wedler, Jannis Niewöhner, Milan Peschel, Edin Hasanović, Anna Fialová, Marlon Boess, Victor Boccard, Fleur Geffrier, Aziz Dyab, Mélanie Fouché, Elizaveta Maximová',
'date_added': '23. september 2021'
}
}
]
}
Vi kan også forenkle forespørselen ved å sette dokument-ID-ene i en enkel matrise som vist i følgende:
curl -XGET 'http://localhost:9200/netflix/_mget' -H 'kbn-xsrf: rapportering' -H 'Content-Type: application/json' -d'{
'ids': ['T3wnVoMBck2AEzXPytlJ', 'W3wnVoMBck2AEzXPytlJ']
}'
Den forrige forespørselen bør utføre en lignende handling.
Eksempel 2: Hent dokumentene fra flere indekser
I følgende eksempel henter forespørselen flere dokumenter fra forskjellige indekser som vist:
curl -XGET 'http://localhost:9200/_mget' -H 'kbn-xsrf: rapportering' -H 'Content-Type: application/json' -d'{
'dokumenter': [
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ'
},
{
'_index': 'disney',
'_id': '8j4wWoMB1yF5VqfaKCE4'
}
]
}'
Den resulterende utgangen er som vist:

Eksempel 3: Ekskluder spesifikke felt
Vi kan ekskludere spesifikke felt fra en gitt forespørsel ved å bruke parameterne source_include og source_exclude.
Et eksempel er som vist:
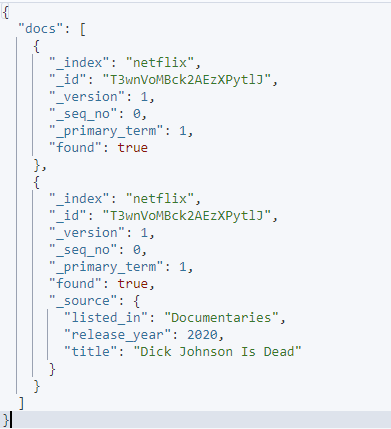
curl -XGET 'http://localhost:9200/_mget' -H 'kbn-xsrf: rapportering' -H 'Content-Type: application/json' -d'{
'dokumenter': [
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ',
'_source': falsk
},
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ',
'_source': {
'include': [ 'listed_in', 'release_year', 'title' ],
'exclude': [ 'beskrivelse', 'type', 'date_added' ]
}
}
]
}'
Den gitte forespørselen bruker kildeinkludering og ekskludering for å spesifisere hvilke felt du ønsker å hente i et gitt dokument.
Den resulterende utgangen er som vist:
Konklusjon
I dette innlegget diskuterte vi det grunnleggende ved å jobbe med Elasticsearch multi-get API som lar deg hente flere dokumenter fra forskjellige kilder basert på ID-ene deres. Utforsk gjerne de andre dokumentene for mer informasjon.
Lykke til med koding!