'Pandas' er et høyytelsesverktøy for pythonmiljøet. Det er en 'åpen' kildekode for analyse av data. Panda-sammenføynings- og panda-sammenslåingsmetoden brukes for å slå sammen de to datarammene til en enkelt dataramme. I begge metodene for pandaer er forskjellen at pandaene 'blir med'-funksjonen blir med i datarammen ved hjelp av en indeks. Mens pandaene 'flette'-funksjonen blir med i datarammen ved å bruke indeksen og kolonnemetoden der vi kan velge ønsket kolonne selv. Sammenslåingsmetoden til pandaer brukes mest sammenlignet med sammenføyningsmetoden til pandaer. Programvaren vi skal bruke for implementeringen er 'spyder'-programvaren, som er i python-miljøet som vil gi oss fordeler for kodeimplementeringen av pandas join-metoden() og pandas merge()-metodefunksjonen.
Syntaks for Pandas Join()-metoden
'df1. bli med ( df2 ) ”'df' i syntaksen ovenfor er forkortelsen for 'dataframe'. Det er to datarammer i syntaksen med 'dot join'-funksjonen, som er for å kalle metoden. Det er panda-metoden for å koble sammen to datarammer. Det fungerer ved å bruke indeksen til å kombinere datarammene i en enkelt.
Syntaks for Pandas Merge()-metoden
'df1. slå sammen ( df2 , på = «kolonne_navn» ) ”Syntaksen for pandas-sammenslåingsmetoden har to datarammer som 'df1' og 'df2'. 'Punktsammenslåing'-funksjonen kaller frem metoden for å slå sammen begge datarammene med utseendet til kolonner invertert.
Vi vil dekke følgende måter å kombinere to datarammer for å bruke metodene for panda-sammenslåing og pandaer:
- Pandas Sammenføyningsmetode overlapper.
- Pandaer blir med i metoden ved å bruke en indekstilbakestilling.
- Pandas sammenslåingsmetode (kolonne 'venstre og høyre').
- Pandas fusjonsmetode eksplisitt.
Opprette datarammene for implementering av Pandas Merge og Pandas Join-metoden
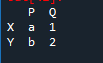
Først må vi lage en dataramme. For det vil vi bruke 'spyder'-verktøyet. Etter å ha åpnet den, begynn å skrive koden. Importer pandaer som 'pd' for pandas bibliotekforening. Vi har datarammevariablene som 'x', 'y', 'p' og 'q tilsvarende og 'a' med verdiene '1' og 'b' med verdien tilordnet som '2'.

Utgangen er en 'df' opprettet med verdiene som er tildelt. Vi kan gjøre det så stort som dataene er.
Opprette en annen dataramme
Vi må lage en annen dataramme, for å forstå metodene for å slå sammen pandaer og slå sammen pandaer. Her har vi 'df' laget det samme som 'df' ovenfor, bare verdiene som er tildelt variabler er forskjellige. Vi har 'h', 'j', 's' og 'd', mens tilordne verdiene 'b' med verdien '8' og 'Y' med verdien '3'.

Utgangen viser en enkel 'df' opprettet.

Eksempel # 01: Panda-sammenføyningsmetode (overlappende)
Nå skal vi se hvordan du kobler sammen to datarammer med pandas join-metoden. For denne metoden kan vi velge kolonnen du ønsker å jobbe med fra datarammen. Vi har tatt eksempelet med den overlappende kolonnen 'venstre' fra 'df', så vi kan fikse dette med 'suffikset' for å overvinne overlappingen av data. Her er variablene som brukes 'x', 'z', 'v', 'd'. 'p', 'o', 'l' og 'y' med verdiene tilordnet som '3', '6', '7' og '9'. '.join' kaller metoden, med align satt til venstre sammenføyning med høyre 'df'-suffiks. '. 'Suffikset' som brukes i koden er fordi det i datarammen er to kolonner som har samme navn som er 'nøkkel', og som ikke vil overlappe dataene.
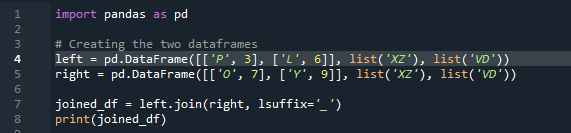
Utdataene viser ingen overlappende data med metoden for å slå sammen to 'df' ved å bruke pandas-sammenføyningsmetoden.
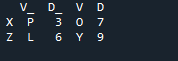
Eksempel # 02: Panda-sammenkoblingsmetode ved hjelp av en indekstilbakestilling
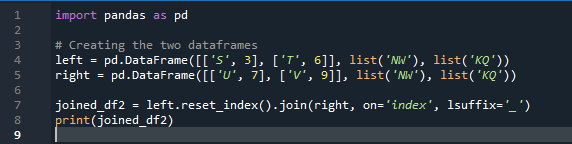
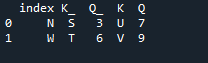
I dette eksemplet spesifiserer vi separat kolonnen med parameteren 'on' som skal brukes som 'nøkkelen' i metodesammenføyningen som hjelper til med å slå sammen de to datarammene. det kombinerte gjøres med denne parameteren. Også indeksen til en av de to 'df' bør være lik for å bli med dem. Lignende typer data eller data som brukes til samme formål kan være sammen for behandling. Dette vil bruke indeksen fortsatt, med fra høyre. Variablene er 's', 't', 'u', 'v', 'n', 'w', 'k' og 'q'. Verdiene som er tilordnet er '3', '6', '7' og '9'. 'Reset dot index' er en metode for pandaer for å tilbakestille indeksen til 'df'. Tilbakestillingsindeksen setter alle heltallene i datarammeoppføringen fra 0 til datarammedataene er forlenget der.
Her er utgangen som vises med indeksen 'nøkkel'-metoden til pandaer.
Eksempel # 03: Pandas flettemetode (kolonne 'venstre og høyre')
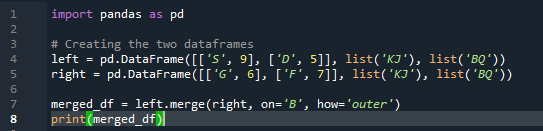
Sammenslåingsmetoden utfører en lignende operasjon som pandas join-metoden. Begge metodene er for å kombinere data på en lignende dataramme. Sammenslåingsmetoden er mer allsidig og krever spesifikasjon av nøkkelen. Vi kan også spesifisere det på venstre og høyre kolonne avhengig av arbeidet med datarammen din. Variablene i koden er 's', 'd', 'g', 'f', 'k', 'j', 'b' og 'q'. verdiene som er tildelt er '9', '5', '6' og '7'. Den ytre 'join'-implementeringen gjøres på begge 'df' ved å bruke parameteren 'how' til funksjonen for pandas merge-metoden.
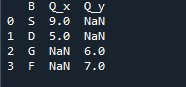
Utdataene vi ser viser de sammenslåtte dataene til de to datarammene. 'NaN' representerer 'ikke et tall', som betyr at der det ikke er noe nummer tildelt i dataene, viser 'NaN' der.
Eksempel # 04: Sammenslåingsmetoden eksplisitt
Her, i dette eksemplet, er sammenslåingsmetoden ødeleggelsen av indeksen og indeksverdien antas ikke på datarammen. Vi vil gjøre denne metoden i henhold til arbeidet som må gjøres, hvor spesifikt spesifikt er å følge opp. Det vil slå sammen dataene basert på en venstre indeks eller høyre indeks med parameteren. Variablene i denne datarammen er 't', 'r', 'I', 'u', 'h', 'o', 'e' og 'e'. De tildelte verdiene er '2', '4', '6' og '4'. Eksempelet ovenfor på metoden for sammenslåing av pandaer med kolonnevalg i henhold til behovet er den mest presentable og verdifulle metoden for å slå sammen de to datarammene. Kontrollerer på slutten av kodelinjen om flettenøkkelen er unik i datasettet.
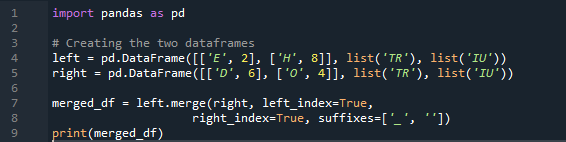
I utgangen nedenfor vises ikke indeksen uten indeksen, men funksjonen utføres basert på høyre og venstre indeks.
Konklusjon
Merge()- og join()-metodene er begge metoder som er veldig praktiske og effektive. Begge disse funksjonene brukes for å koble sammen de to separate datarammene på samme dataramme, men har forskjellig bruk avhengig av tilfellet. I denne artikkelen har vi lært de viktigste forskjellene mellom metoden for sammenføyning og sammenslåing av pandaer. Etter å ha gjort eksemplene og forstått metoden for sammenføyning av pandaer, vil vi konkludere med kunnskapen om at hvis vi ønsker mer fleksibel sammenføyning i databasestil, er det å foretrekke å bruke sammenslåingsmetoden for pandaer. På den annen side, hvis vi ønsker å kombinere datarammen med indeksen omfattende, kan vi gå med pandas join()-metodefunksjonen.