Pandaer er blant de mest populære verktøyene som brukes i dag av dataforskere for å analysere tabelldata. For å håndtere tabellinnhold tilbyr den en raskere og mer effektiv API. Hver gang vi ser på datarammer under analyse, setter Pandas automatisk ulike visningsatferder til standardverdier. Disse visningsatferdene inkluderer hvor mange rader og kolonner som skal vises, nøyaktigheten til flytende data i hver dataramme, kolonnestørrelser osv. Avhengig av kravene kan det hende at vi må endre disse standardinnstillingene. Pandaer har en rekke tilnærminger for å endre standard oppførsel. Ved å utnytte «alternativer»-attributtet til pandaer kunne vi endre denne oppførselen.
Pandaer viser maksimalt antall rader
Hver gang du prøver å skrive ut en stor dataramme som inneholder flere rader og kolonner enn den forhåndsdefinerte terskelen, vil utdataene bli trimmet. For å vise alle rader i DataFrame, lærer du hvordan du endrer Pandas visningsalternativer i denne opplæringen. Pandaer pålegger som standard en grense på antall kolonner og rader den viser. Selv om dette kan være nyttig for å lese innhold, forårsaker det ofte frustrasjon hvis informasjonen du trenger å se ikke vises. Her vil vi bruke metodene gitt nedenfor med deres syntaks for å vise alle kolonnene i datarammen.
to_string()

set_option()

option_context()

Vi vil lære bruken av alle disse metodene med praktisk implementering for å vise maksimale rader i den medfølgende datarammen.
Eksempel # 1: Bruke Pandas to_string()-metoden
Denne demonstrasjonen vil lære oss å vise maksimale rader i en dataramme på terminalen ved å bruke pandas 'to_string()'-metoden.
For kompilering og kjøring av eksempelprogrammene har vi valgt 'Spyder'-verktøyet. I denne veiledningen vil vi bruke dette verktøyet til å utføre alle eksemplene våre. Vi har lansert 'Spyder'-verktøyet for å begynne å skrive python-skriptet. Fra og med koden må vi først laste de nødvendige bibliotekene inn i python-filen vår, slik at vi får lov til å bruke funksjonene. Modulbiblioteket vi trenger her er 'Pandaene'. Så vi importerte den til python-filen vår og aliaserte den til 'pd'.
Siden hovedoperasjonen i denne artikkelen er å vise de maksimale radene i en dataramme, trenger vi først en dataramme. Det er nå opp til deg om du foretrekker å generere en dataramme eller importere en CSV-fil. Vi har importert en eksempel-CSV-fil. For å lese en CSV-fil inn i python-programmet har vi brukt pandas 'pd.read_csv()'-funksjonen. Mellom parentesene til denne funksjonen har vi gitt CSV-filen vi ønsker skal lese skjermen, som er 'industry.csv'. Vi har konstruert en variabel 'df' for å lagre utdataene generert fra lesing av den oppgitte CSV-filen. Deretter påkalte vi 'print()'-metoden for å vise datarammen.
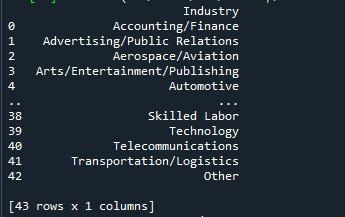
Når vi kjører dette pythonprogrammet ved å trykke på 'Kjør fil', vises en dataramme på konsollen. Du kan se at det er 43 rader i resultatet nedenfor, men bare ti vises. Dette er fordi Pandas-bibliotekets standardverdi bare er 10 rader.
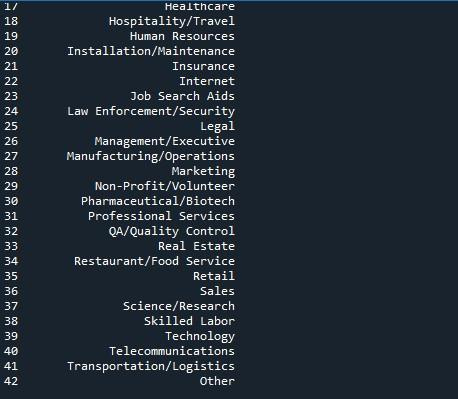
Vi vil bruke pandas-metoden 'to_string' for å vise alle rader her. Den enkleste måten å vise maksimale rader fra en dataramme på er med denne teknikken. Men siden den gjør hele datarammen til en enkelt streng, anbefales det ikke for veldig store datasett (i millioner). Likevel fungerer dette effektivt for datasett som er i lengden på tusenvis.
Vi har fulgt syntaksen ovenfor for 'to_string()'-funksjonen. Vi påkalte ganske enkelt 'to_string()'-metoden med navnet på datarammen vår. Deretter plasserte vi denne metoden i 'print()'-funksjonen for å vise den når den ble kalt.

Utgangsbildet viser oss en dataramme med alle radene som vises på terminalen.
Eksempel # 2: Bruke Pandas set_option-metode
Den andre metoden vi vil øve på i denne veiledningen er pandaene 'set_option()' for å vise de maksimale radene i den angitte datarammen.
I python-filen har vi importert pandas-biblioteket for å få tilgang til ovennevnte funksjon. Vi har brukt pandaene 'pd.read_csv()' for å lese den medfølgende CSV-filen. Vi påkalte «pd.read_CSV()»-funksjonen med navnet på CSV-filen vi ønsker å bruke mellom parentesen, som er «Sampledata.csv». Når du importerer CSV-filen, må du huske på den gjeldende arbeidskatalogen til Python-programmet. CSV-filen din må plasseres i samme katalog; ellers vil du få en feilmelding 'filen ikke funnet'. Vi har laget en variabel 'sample' for å lagre datarammen fra CSV-filen. Vi kalte 'print()'-metoden for å vise denne datarammen.
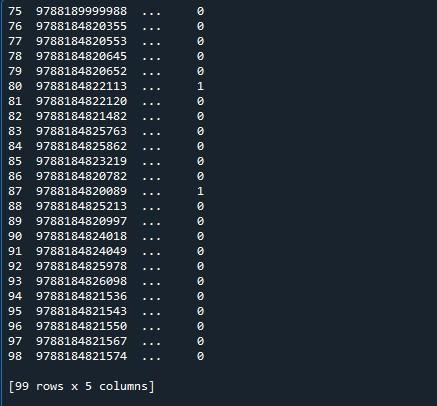
Her har vi vår utgang der bare ti rader vises. Maksimalt antall rader som er angitt er 99. Alle de andre radene mellom de første 5 og de siste fem radene er avkortet.

For å vise de maksimale radene som er 99 for denne datarammen, bruker vi 'set_option()'-funksjonen til panda-modulen. Pandaer kommer med et operativsystem som lar deg endre oppførsel og visning. Denne metoden gjør det mulig for oss å sette skjermen til å vise en full dataramme i stedet for en avkortet. Pandaer har funksjonen 'set_ option()' for å vise alle rader i datarammen.
Vi har påkalt 'pd.set_option()'. Denne funksjonen har parametere 'display.max_rows'. 'display.max_rows' spesifiserer det maksimale antallet rader som vil bli vist når en dataramme vises. Verdien for 'max_rows' er satt til 10 som standard. Hvis 'Ingen' er valgt, betyr det alle rader i datarammen. Ettersom vi ønsker å vise alle radene, så setter vi den til 'Ingen'. Til slutt brukte vi 'print()'-funksjonen for å vise datarammen med maks. rader.

Dette gir resultatet gitt i øyeblikksbildet nedenfor.
Eksempel # 3: Bruke Pandas option_context() metode
Den siste metoden vi diskuterer her er 'option_context()' for å vise alle datarammens rader. For dette importerte vi pandas-pakken til python-filen og begynte å skrive koden. Vi har brukt funksjonen 'pd.read_csv()' for å lese CSV-filen vi har spesifisert. Vi opprettet en variabel 'dalta' for å lagre datarammen fra den angitte CSV-filen. Deretter skrev vi ganske enkelt ut datarammen med 'print()'-metoden.
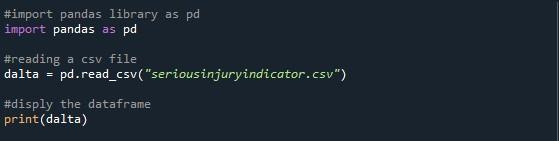
Resultatet vi fikk fra å utføre koden ovenfor viser oss en dataramme med avkortede rader.
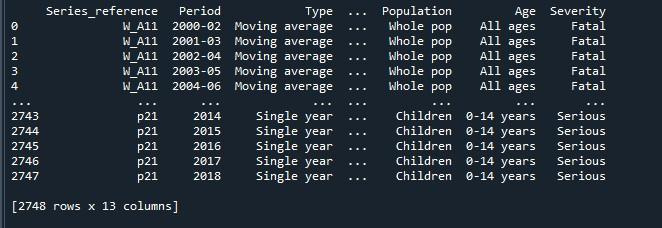
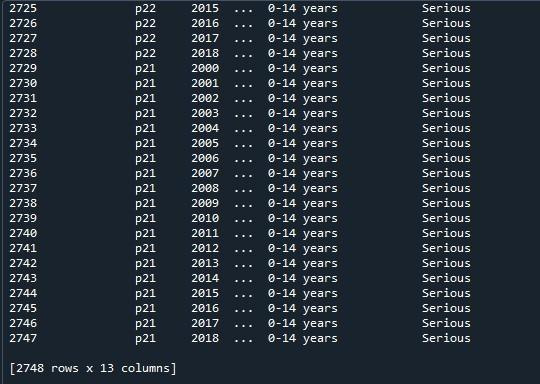
Vi vil nå bruke pandaene 'pd.option_context()' på denne datarammen. Denne funksjonen er identisk med 'set_option()'. Den eneste forskjellen mellom de to tilnærmingene er at 'set_option()' endrer innstillingene permanent, mens 'option _context()' bare endret dem innenfor sitt omfang. Denne metoden tar også display.max rader som en parameter, som vi setter til 'Ingen' for å gjengi alle rader i datarammen. Etter å ha påkalt denne funksjonen, viste vi den gjennom 'print()'-metoden.

Her kan vi se hele datarammen med dens maksimale rader som er 2747.
Konklusjon
Denne artikkelen fokuserer på visningsalternativene til pandaene. Noen ganger må vi kanskje se hele datarammen på terminalen. Pandaer gir oss en rekke alternativer for det formålet. I denne veiledningen har vi brukt tre av disse strategiene. Det første eksemplet var basert på bruk av 'to_string()'-metoden. Vår andre instans lærer oss å implementere 'set_option()' mens den siste illustrasjonen utfører 'option_context()'-metoden. Alle disse teknikkene er demonstrert for å gjøre deg kjent med de alternative måtene pandaene gir oss for å oppnå det nødvendige resultatet.