'I 'pandas' kan vi enkelt lese tekstfilen ved hjelp av 'pandas'-metoden. 'Pandas' gir oss muligheten til å lese tekstfilen. 'Pandas' gir forskjellige innebygde metoder for å lese tekstfilen. Vi vil diskutere alle metodene i denne opplæringen sammen med alle parametere her og vil forklare dem i detalj. Vi vil også lese tekstfilen i 'pandas' ved å bruke metodene til 'pandas' i kodene våre her.'
Metoder for å lese tekstfilen i 'pandaer'
I 'pandaer' har vi tre metoder som hjelper oss med å lese tekstfilen. Vi har også gjort noen eksempler her hvor vi leser tekstfilen. Metodene som 'pandaene' gir er diskutert nedenfor:
-
- Ved å bruke pd.read_csv()-metoden.
- Ved å bruke pd.read_table()-metoden.
- Ved å bruke pd.read_fwf()-metoden.
Nå forklarer vi syntaksen til alle disse metodene og diskuterer også parametrene til alle metodene i detalj i denne opplæringen.
Syntaks for read_csv()
pd.read_csv ( 'filnavn.txt', sep =' ', Overskrift = Ingen, navn = [ «Col_name1», «Col_name2», «Col_name2», ………….. ] )
I denne metoden legger vi først til navnet på tekstfilen hvis data vi vil lese, og det er den første parameteren i denne metoden. Deretter plasserer vi 'sep', som er en separator i denne metoden, og vi plasserer plass her som tegnet slik at det vil betrakte rommet som skillet. Etter dette har vi overskriftsparameteren, og 'Ingen' -verdien til denne parameteren brukes, så den vil opprette standardoverskriften, og hvis vi ikke legger til denne parameteren, vil den vurdere den første linjen i tekstfilen som overskrift. I 'navn'-parameteren kan vi legge til kolonnenavnene som vi må legge til som overskrift.
Syntaks for read_table()
pd.lesetabell ( 'filnavn.txt' , skilletegn = ' ' )
I denne metoden setter vi filnavnet til tekstfilen som den første parameteren. I skilletegnet, når vi plasserer ' ', vil det ta mellomromstegnet som skilletegn.
Syntaks for read_fwf()
pd.read_fwf ( 'filnavn.txt' )
Denne metoden tar bare én parameter, som er navnet på tekstfilen.
Nå vil vi bruke disse metodene for å lese tekstfilene i 'pandas'-koder og vise tekstfilens data på terminalen.
Eksempel # 01
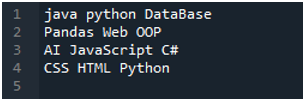
'Spyder'-appen er her der vi har gjort alle disse kodene som presenteres i denne opplæringen. Tekstfilen hvis data vi ønsker å lese, vises nedenfor. Vi vil bruke 'read_csv()'-metoden for å lese denne tekstfilen i 'pandas'.
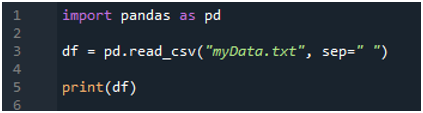
Vi importerer først «pandas»-biblioteket fordi vi ønsker å bruke «read_csv()»-metoden, og det er metoden til «pandas». Vi har kun tilgang til denne metoden når vi har importert biblioteket med 'pandaer'. Her nevner vi 'pandaer som pd', så denne 'pd' er plassert med navnet på metoden for å bruke den. Etter dette lager vi en variabel 'df' her, som brukes til å lagre dataene til tekstfilen etter lesing. Vi plasserer 'pd.read_csv()'-metoden her, som hjelper til med å lese tekstfilen og konvertere tekstfildataene til DataFrame og lagre dem i 'df'-variabelen.
Vi har sendt filnavnet, som er 'myData.txt,' her, og så bruker vi 'sep' og tildeler det tomme tegnet til denne 'sep'. Så dette tomme tegnet fungerer som skilletegn i tekstfilen. Deretter brukte vi 'print()' nedenfor, som brukes til å skrive ut dataene til tekstfilen. Den vil vise dataene til tekstfilen i DataFrame-skjemaet.
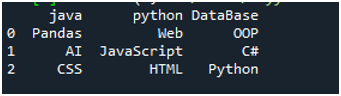
For å utføre denne koden, må vi trykke 'Shift+Enter', og utgangen vil bli gjengitt på 'Spyders' terminal. Resultatet av koden ovenfor vises i det gitte skjermbildet, og du kan se at dataene til tekstfilen vises som DataFrame, og den første linjen i tekstfilen vår presenteres her som kolonnenavnene til den DataFrame. Den skiller også dataene der mellomromstegnet er til stede i tekstfilen.
Eksempel # 02
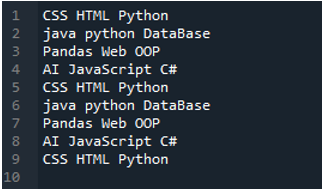
Tekstfilen som vi skal lese i dette eksemplet vises her, og vi vil igjen bruke 'read_csv()'-metoden, men med andre parametere.
'pandas'-metoden 'pd.read_csv()' brukes, og vi sender tre parametere her. Først plasserer vi filnavnet, som er 'Record.txt'. Den andre parameteren er 'sep' -parameteren og tilordner det tomme tegnet til det, og så har vi den tredje parameteren der vi setter 'header' og justerer den til 'None', så den vil opprette standardoverskriften til DataFrame når vi kjører denne koden. Vi har lagret alt dette i 'My_Record'-variabelen og også lagt til 'My_Record' i 'print()'-funksjonen for utskrift.

Alle data lagres i DataFrame, og den skiller dataene der mellomromstegnet er til stede i tekstfildataene. Det opprettet også standardoverskriften til DataFrame her fordi vi justerte 'header'-parameteren til 'Ingen'.
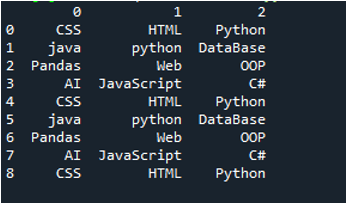
Eksempel # 03
Dette eksemplets tekstfil vises, og vi vil igjen bruke 'read_csv()'-metoden med modifiserte parametere.
I denne koden sendes fire parametere her til 'pandas'-metoden 'pd.read_csv()'. Tekstfilens navn er den første parameteren. 'sep'-parameteren får det tomme tegnet i den andre parameteren. Parameteren 'header' er satt til 'Ingen' i det tredje argumentet, og som den fjerde parameteren har vi satt 'navnene' som vil vises som kolonnenavnene til DataFrame etter å ha lest tekstfilen, og disse kolonnenavnene er «COL_1, COL_2, COL_3, COL_4 og COL_5». All denne informasjonen er lagret i 'My_Record'-variabelen, og 'My_Record' er også lagt til i 'print()'-metoden slik at den vil skrives ut på terminalen.

All informasjon om tekstfilen gjengis her som DataFrame, og den skiller også dataene der mellomrommene er lagt til i tekstfilen. Den legger også til kolonnenavnene tilsvarende, som vi har lagt til ovenfor i koden.
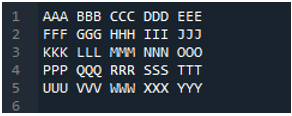
Eksempel # 04
Dette er tekstfilen vi skal lese i dette eksemplet ved å bruke en annen metode, 'pd.read_table()'-metoden.
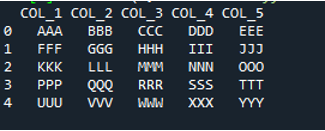
Metoden 'pd.read_table()' legges til her for å lese tekstfilen, og vi legger til 'ABC.txt', som er tekstfilens navn. Denne metoden hjelper til med å lese tekstfilen, og vi har også justert parameteren 'skilletegn' til mellomromstegnet, så det vil også fungere som skilletegn som vi har forklart ovenfor. Deretter lagres all tekstfildata i 'My_Data'-variabelen og skrives også ut her.

Den første linjen i tekstfilen vår vises her som kolonnenavnene til DataFrame, og dataene til tekstfilen skrives ut som DataFrame. I tillegg skiller den dataene til tekstfilen der mellomromstegnet er til stede i den.
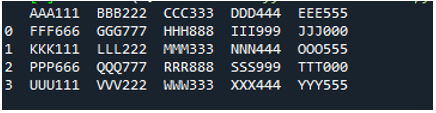
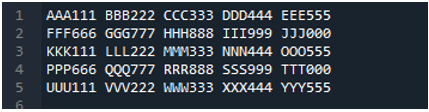
Eksempel # 05
Nå inneholder tekstfilen dataene, som vises nedenfor. Vi vil bruke 'read_fwf()' denne gangen og vil vise hvordan den gjengir data etter å ha lest tekstfilen.
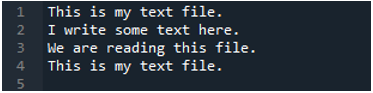
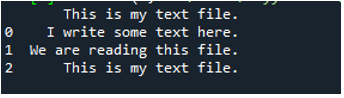
Som vi vet at denne 'read_fwf()'-metoden bare tar én parameter, som er filnavnet vi ønsker å lese. Vi legger til 'textfile.txt' her, som er navnet på tekstfilen vår, og tilordner denne pandas-metoden til 'File_Data'-variabelen, som vil lagre dataene til denne tekstfilen. Deretter legger vi 'print(File_Data)' slik at den også skriver ut disse dataene.

Her vises alle data i tekstfilen. Den skilte ikke dataene der mellomromstegn er til stede fordi det ikke er noen parameter som 'Sep' eller 'skilletegn' i denne funksjonen.
Konklusjon
Denne opplæringen forklarer hvordan du leser tekstfilen i 'pandas' og hvilke metoder som brukes for å lese tekstfilen i 'pandas'. Vi har diskutert alle metoder som hjelper oss med å lese tekstfilen i 'pandas'. Vi har utforsket tre forskjellige metoder for 'pandas' for å lese tekstfilene våre i 'pandas' i denne opplæringen. Vi har også forklart syntaksen til alle metodene samt parameterne til alle metodene i detalj her og har lest mange tekstfiler ved å bruke forskjellige metoder med alle mulige parametere i denne opplæringen.