Dette innlegget dekker PostgreSQL-partisjoneringen. Vi vil diskutere de forskjellige partisjoneringsalternativene du kan bruke og gi eksempler på hvordan du bruker dem for bedre forståelse.
Hvordan lage PostgreSQL-partisjoner
Enhver database kan inneholde mange tabeller med flere oppføringer. For enkel administrasjon bør du partisjonere tabellene som er en flott og anbefalt datavarehusrutine for databaseoptimalisering og for å hjelpe til med pålitelighet. Du kan lage forskjellige partisjoner, inkludert listen, området og hashen. La oss diskutere hver enkelt i detalj.
1. Listepartisjonering
Før vi vurderer noen partisjonering, må vi lage tabellen som vi skal bruke for partisjonene. Når du oppretter tabellen, følg den gitte syntaksen for alle partisjoner:
LAG TABELL tabellnavn(kolonne1 datatype, kolonne2 datatype) PARTISJON AV
'Tabell_name' er navnet på tabellen sammen med de forskjellige kolonnene som tabellen vil ha og deres datatyper. For 'partisjonsnøkkelen' er det kolonnen som partisjoneringen vil finne sted. For eksempel viser følgende bilde at vi opprettet 'kurs'-tabellen med tre kolonner. Dessuten er vår partisjoneringstype LIST, og vi velger fakultetskolonnen som vår partisjoneringsnøkkel:

Når tabellen er opprettet, må vi lage de forskjellige partisjonene vi trenger. For det, fortsett med følgende syntaks:
LAG TABELL partisjonstabell PARTISJON AV hovedtabell FOR VERDIER I (VERDI);For eksempel viser det første eksemplet i det følgende bildet at vi opprettet en partisjonstabell kalt 'Fset' som inneholder alle verdiene i 'fakultet'-kolonnen som vi valgte som vår partisjonsnøkkel hvis verdi er 'FSET'. Vi brukte en lignende logikk for de to andre partisjonene vi laget.
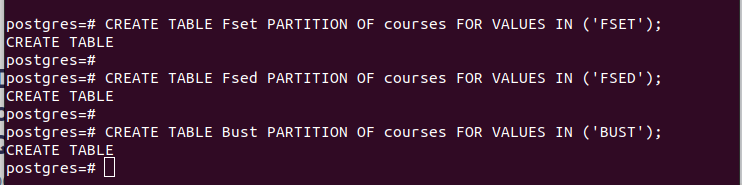
Når du har partisjonene, kan du sette inn verdiene i hovedtabellen vi opprettet. Hver verdi du setter inn samsvarer med den respektive partisjoneringen basert på verdiene i partisjonsnøkkelen du valgte.
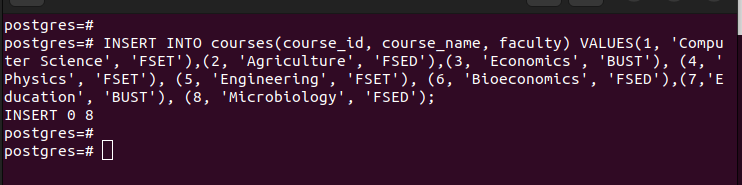
Hvis vi viser alle oppføringene i hovedtabellen, kan vi se at den har alle oppføringene vi har satt inn.
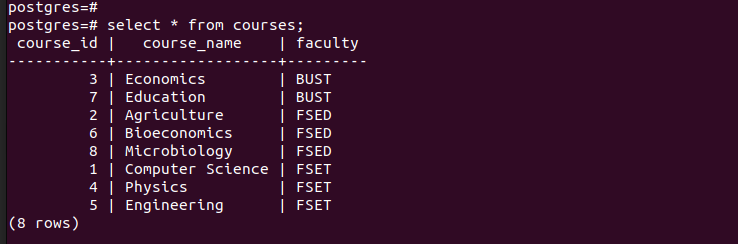
For å bekrefte at vi har opprettet partisjonene, la oss sjekke postene i hver av de opprettede partisjonene.
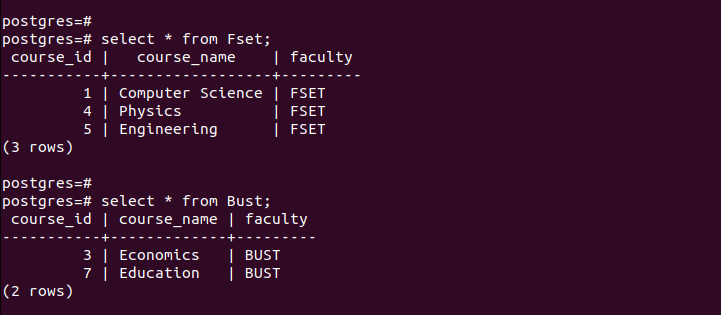
Legg merke til hvordan hver partisjonert tabell bare inneholder oppføringene som samsvarer med kriteriene som er definert ved partisjonering. Det er slik partisjonering etter liste fungerer.
2. Områdepartisjonering
Et annet kriterium for å lage partisjoner er å bruke RANGE-alternativet. For dette må vi spesifisere start- og sluttverdiene som skal brukes for området. Å bruke denne metoden er ideell når du arbeider med datoer.
Syntaksen for å lage hovedtabellen er som følger:
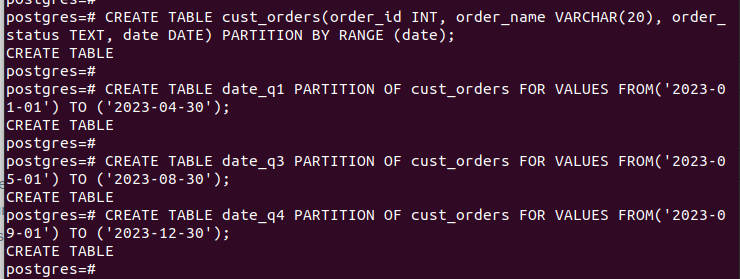
LAG TABELL tabellnavn (kolonne1 datatype, kolonne2 datatype) PARTISJON ETTER RANGE (partisjonsnøkkel);Vi opprettet 'cust_orders'-tabellen og spesifiserte den for å bruke datoen som vår 'partisjonsnøkkel'.

For å lage partisjonene, bruk følgende syntaks:
LAG TABELL partisjonstabell PARTISJON AV hovedtabell FOR VERDIER FRA (startverdi) TIL (sluttverdi);Vi definerte partisjonene våre til å fungere kvartalsvis ved å bruke 'dato'-kolonnen.
Etter å ha opprettet alle partisjonene og satt inn dataene, ser tabellen vår ut slik:
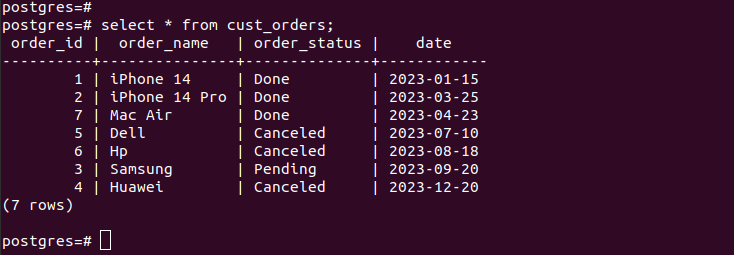
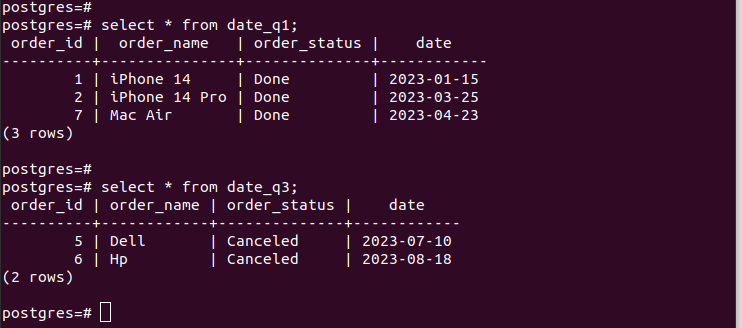
Hvis vi sjekker oppføringene i de opprettede partisjonene, verifiserer vi at partisjoneringen vår fungerer, og vi har bare de riktige postene i henhold til partisjoneringskriteriene vi spesifiserte. For alle de nye oppføringene du legger til i tabellen, blir de automatisk lagt til den respektive partisjonen.
3. Hash-partisjonering
Det siste partisjoneringskriteriet som vi vil diskutere er å bruke hash. La oss raskt lage hovedtabellen ved å bruke følgende syntaks:
LAG TABELL tabellnavn(kolonne1 datatype, kolonne2 datatype) PARTISJON VED HASH (partisjonsnøkkel); 
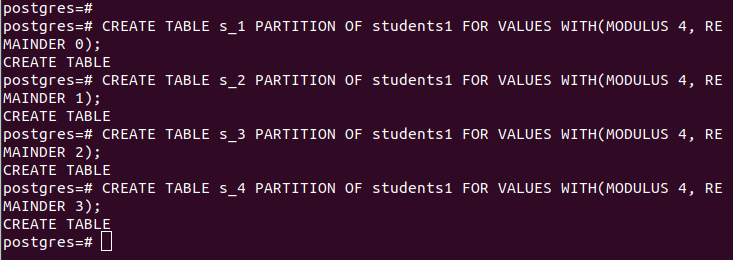
Når du partisjonerer med hash, må du oppgi modulen og resten, radene som skal deles på hash-verdien til din spesifiserte 'partisjonsnøkkel'. For vårt tilfelle bruker vi en modul på 4.
Syntaksen vår er som følger:
LAG TABELL partisjonstabell PARTISJON AV hovedtabell FOR VERDIER MED (MODUL num1, REMAINDER num2);Våre partisjoner er som følger:
For 'main_table' inneholder den oppføringene som vises i følgende:
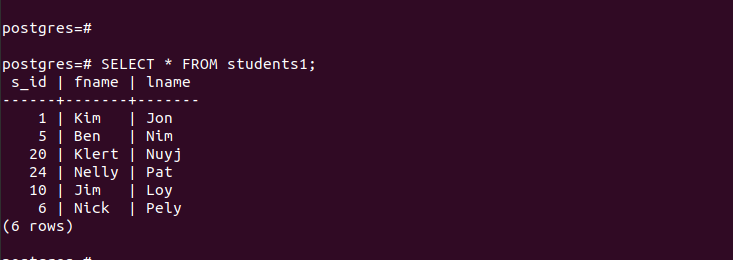
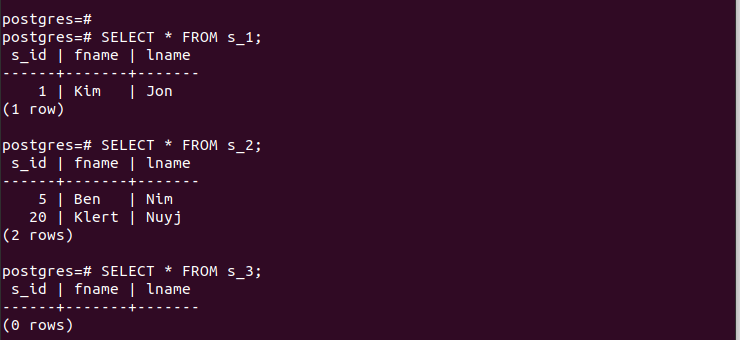
For de opprettede partisjonene kan vi raskt få tilgang til oppføringene deres og bekrefte at partisjoneringen vår fungerer.
Konklusjon
PostgreSQL-partisjoner er en praktisk måte å optimalisere databasen for å spare tid og øke påliteligheten. Vi diskuterte partisjoneringen i detalj, inkludert de forskjellige tilgjengelige alternativene. I tillegg ga vi eksempler på hvordan du implementerer partisjonene. Prøv dem!