La oss se på iconv-verktøyet til Linux i terminalkonsollen nå. Så vi har utført instruksjonen 'iconv' med '-l'-flagget for å vise alle de kjente og mest brukte kodede tegnsettene på terminalskjermen vår. Den vil vise de kodede tegnsettene sammen med deres aliaser. Du kan se en lang liste med kodede tegnsett etter å ha skrollet litt ned.
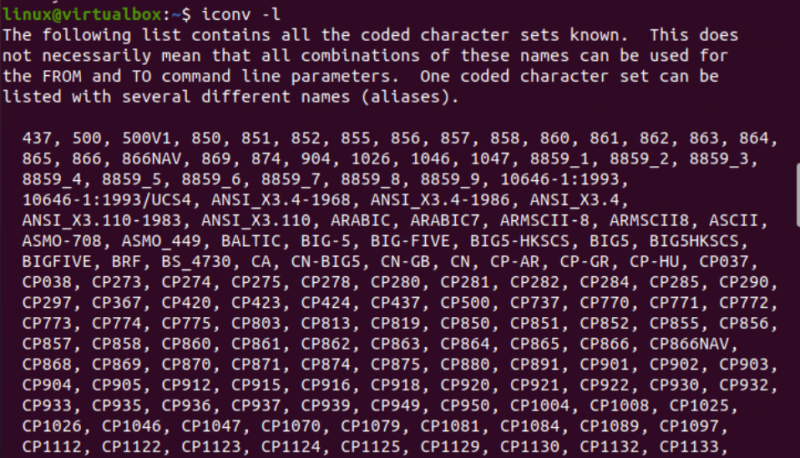
Nå er det på tide å komme i gang med implementeringen av iconv-kommandoen i Linux. For det første trenger vi forskjellige typer filer i systemet vårt for å konvertere en filtype til en annen type. Derfor bruker vi 'touch'-spørringen på konsollterminalen for å lage tre forskjellige filer, dvs. Java-type, C-type og teksttype. Når du viser gjeldende kataloginnhold, vil du finne de nylig genererte filene i den.
Etter dette vil vi se på typen til hver fil separat ved å bruke 'fil'-spørringen sammen med navnet på hver fil. Denne spørringen trenger alternativet '-I' for å vise typen kodetegnsett for hver fil separat. Hvis du har glemt å bruke '-I'-alternativet, bruk '—mime'-flagget i stedet. Både '-I' og '—mime'-flagg fungerer på samme måte.
Nå, etter å ha utført 'fil'-instruksjonen for 'txt'-filen, fikk vi 'US-ASCII' tegntypekoding. Mens du bruker den samme instruksjonen for Java- og C-filene, viser den at begge filene inneholder 'BINÆR' tegntypekoding. Sammen med det viser denne instruksjonen at alle disse tre filene er tomme.
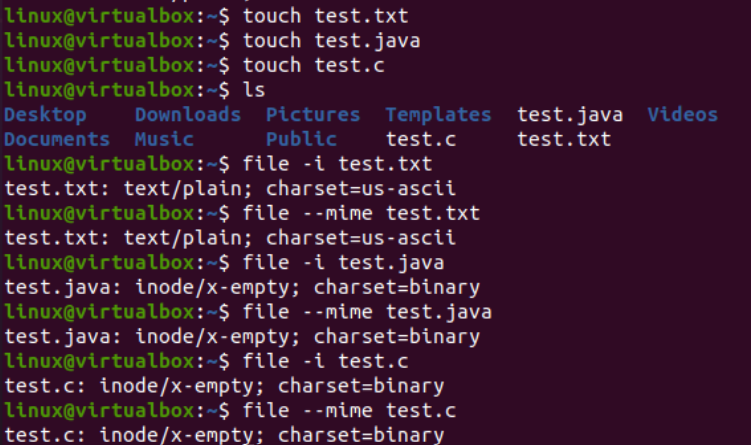
Nå skal vi illustrere bruken av iconv-instruksjoner på konsollen for å konvertere en spesifikk tegnsettkodingsfil til en annen tegnsettkoding. Før det må vi legge til noe kode eller data til filene våre. Derfor har vi lagt til Java-koden i «text.java»-filen, C-koden i «text.c»-filen, og lagt til tekstdata i «test.txt»-filen. Cat-spørringen ble brukt her for å vise innholdet i alle tre filene, som presentert nedenfor:
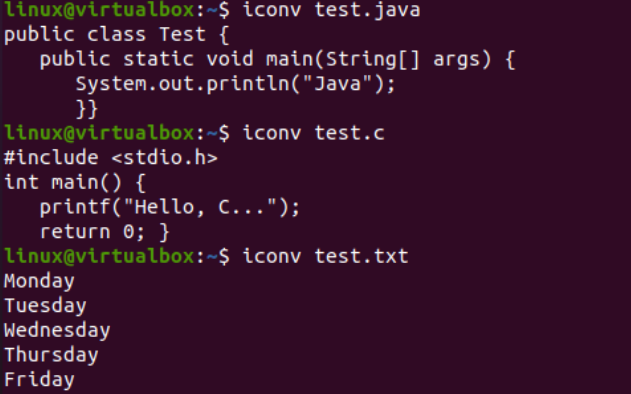
Nå som vi har lagt til dataene, vil vi se tegnsettets koding av disse filene igjen. Så vi har prøvd den samme filinstruksjonen i skallet med '-I'-flagget og filnavnene, dvs. test.txt, test.java og test.c. Å kjøre disse tre instruksjonene separat for alle tre filene viser at tegnsettkodingen har blitt oppdatert for Java- og C-filene, mens den forblir den samme for tekstfilen, dvs. US-ASCII. Kodingen av Java- og C-filer var tidligere 'binær'; nå er det 'US-ASCII'. Det viser også at tekstfilen inneholder ren tekstdata mens de to andre kodefilene inneholder skriptene som innhold.

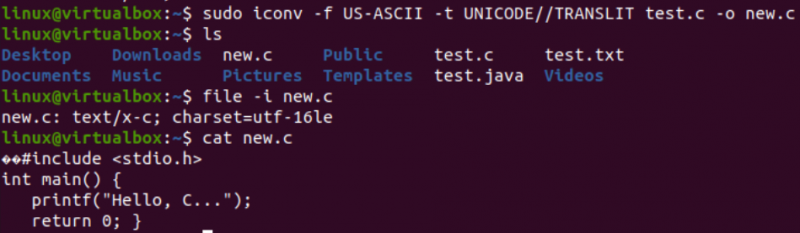
Det er på tide å utføre den faktiske oppgaven som trengs for denne artikkelen, dvs. konvertere en koding til en annen ved å bruke iconv-kommandoen i skallet. Dermed har vi brukt 'iconv'-instruksjonen i skallterminalen med 'sudo'-privilegiene. Denne kommandoen tar '-f'-alternativet står for 'fra', og '-t'-alternativet står for 'til', dvs. fra en koding til en annen.
Etter '-f'-alternativet, må du spesifisere kodingen filen din allerede har, det vil si US-ASCII. Mens etter '-t'-alternativet, må du spesifisere kodingen du vil erstatte med den gamle kodingen, dvs. UNICODE. Du må spesifisere navnet på en fil som brukes som kilde med alternativet –o for å lage objektbildet. Objektbildet vil være en annen fil, dvs. 'new.c', av samme type, men med den nye kodingen og de samme dataene.
Etter å ha utført følgende instruksjon, vil du få en ny fil i samme katalog, dvs. i henhold til 'ls'-spørringen. Nå vil vi se etter tegnsettkodingen til en ny fil generert ved hjelp av iconv-instruksjonen. Vi vil igjen bruke 'fil'-instruksjonen med '-I'-alternativet og det nye filnavnet, dvs. new.c.
Du vil se at tegnsettet for denne nye filen har vært forskjellig fra tegnsettet til en gammel fil, det vil si UTF-16LE-tegnsettet. Dette er fordi vi har oversatt US-ASCII-kodingen til UNICODE-kodingen ved å bruke iconv-instruksjonen for vår new.c-fil. 'cat'-spørringen viste den samme C-koden i filen, men startet med noen Unicode-tegn, som allerede presentert.
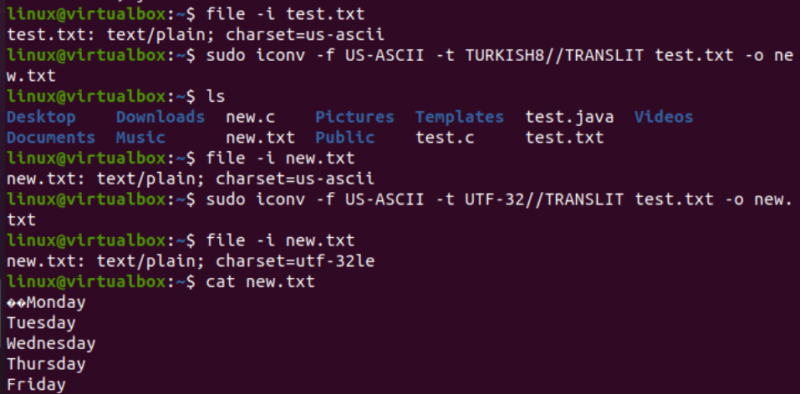
På en veldig lik måte vil vi endre kodingen av tekstfilen test.txt. Filinstruksjonen viser at den har en US-ASCII tegnsettkoding. iconv-kommandoen har blitt brukt med samme format for å konvertere kodingen av test.txt-filen fra US-ASCII til TURKISH8. Du vil se at det ikke endrer US-ASCII til tyrkisk.
Etter dette brukte vi den samme kommandoen for å dekke US-ASCII til UTF-32 tegnsettkoding for den samme filen. Denne gangen fungerer det. Dette er fordi noen ganger kan det være et problem med å konvertere ett kodingssett til et annet, eller at den andre kodingen ikke støtter det.
Konklusjon
Denne artikkelen diskuterte hvordan du bruker iconv Linux-instruksjonene for å konvertere ett tegnsett for koding til et annet ved å bruke deres aliaser. På denne måten måtte vi lage noen filer av forskjellige typer.