I denne artikkelen vil vi diskutere hvordan du fordeler ANNERLEDES minne via ' pytorch_cuda_alloc_conf 'metoden.
Hva er 'pytorch_cuda_alloc_conf'-metoden i PyTorch?
I bunn og grunn er ' pytorch_cuda_alloc_conf ” er en miljøvariabel innenfor PyTorch-rammeverket. Denne variabelen muliggjør effektiv styring av de tilgjengelige behandlingsressursene, noe som betyr at modellene kjører og produserer resultater på minst mulig tid. Hvis det ikke gjøres riktig, vil ' ANNERLEDES ' beregningsplattformen vil vise ' tomt for minne ” feil og påvirke kjøretiden. Modeller som skal trenes over store datamengder eller har store ' batchstørrelser ” kan produsere kjøretidsfeil fordi standardinnstillingene kanskje ikke er nok for dem.
« pytorch_cuda_alloc_conf ' variabel bruker følgende ' alternativer ' for å håndtere ressursallokering:
- innfødt : Dette alternativet bruker de allerede tilgjengelige innstillingene i PyTorch for å allokere minne til den pågående modellen.
- max_split_size_mb : Den sikrer at enhver kodeblokk som er større enn den angitte størrelsen ikke deles opp. Dette er et kraftig verktøy for å forhindre ' fragmentering '. Vi vil bruke dette alternativet for demonstrasjonen i denne artikkelen.
- roundup_power2_divisjoner : Dette alternativet runder opp størrelsen på tildelingen til nærmeste ' kraften til 2 ” inndeling i megabyte (MB).
- roundup_bypass_threshold_mb: Den kan runde opp tildelingsstørrelsen for enhver forespørsel som viser mer enn den angitte terskelen.
- søppelinnsamlingsgrense : Den forhindrer latens ved å bruke tilgjengelig minne fra GPU i sanntid for å sikre at gjenvinnings-all-protokollen ikke startes.
Hvordan tildele minne ved å bruke metoden 'pytorch_cuda_alloc_conf'?
Enhver modell med et betydelig datasett krever ekstra minneallokering som er større enn det som er angitt som standard. Den tilpassede tildelingen må spesifiseres med tanke på modellkravene og tilgjengelige maskinvareressurser.
Følg trinnene nedenfor for å bruke ' pytorch_cuda_alloc_conf ”-metoden i Google Colab IDE for å allokere mer minne til en kompleks maskinlæringsmodell:
Trinn 1: Åpne Google Colab
Søk på Google Samarbeidende i nettleseren og lag en ' Ny notatbok ' for å begynne å jobbe:
Trinn 2: Sett opp en tilpasset PyTorch-modell
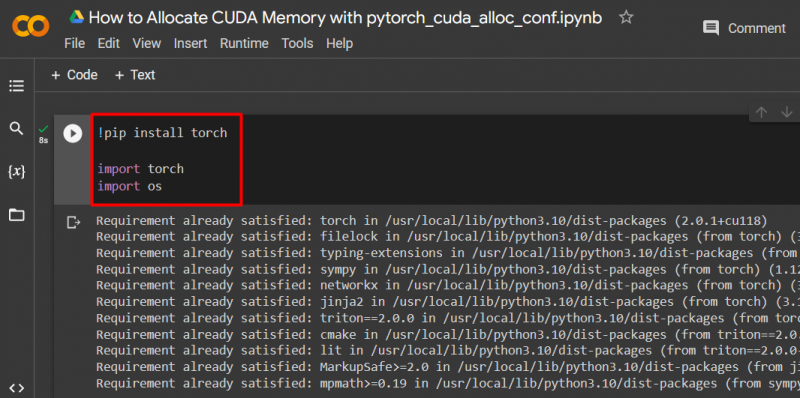
Sett opp en PyTorch-modell ved å bruke ' !pip ' installasjonspakken for å installere ' lommelykt ' biblioteket og ' import ' kommando for å importere ' lommelykt ' og ' du ” biblioteker inn i prosjektet:
importere lommelykt
importere oss
Følgende bibliotek er nødvendig for dette prosjektet:
- Lommelykt – Dette er det grunnleggende biblioteket som PyTorch er basert på.
- DU – Den ' operativsystem ' bibliotek brukes til å håndtere oppgaver relatert til miljøvariabler som ' pytorch_cuda_alloc_conf ' samt systemkatalogen og filtillatelsene:
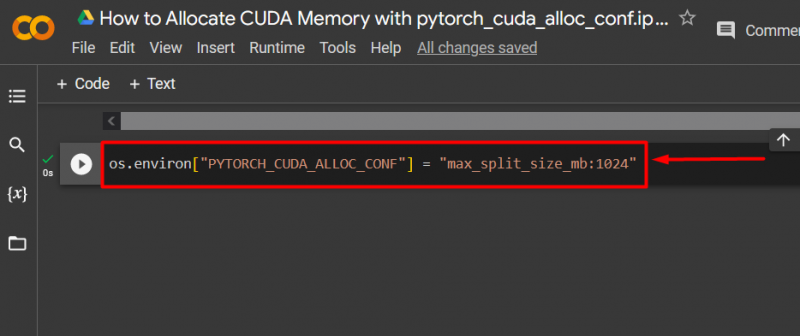
Trinn 3: Tildel CUDA-minne
Bruke ' pytorch_cuda_alloc_conf '-metoden for å spesifisere maksimal delt størrelse ved å bruke ' max_split_size_mb ':
Trinn 4: Fortsett med PyTorch-prosjektet
Etter å ha spesifisert ' ANNERLEDES ' plasstildeling med ' max_split_size_mb '-alternativet, fortsett å jobbe med PyTorch-prosjektet som normalt uten frykt for ' tomt for minne ' feil.
Merk : Du kan få tilgang til Google Colab-notatboken vår her link .
Pro-Tips
Som nevnt tidligere, ' pytorch_cuda_alloc_conf ”-metoden kan ta hvilket som helst av alternativene ovenfor. Bruk dem i henhold til de spesifikke kravene til dyplæringsprosjektene dine.
Suksess! Vi har nettopp vist hvordan du bruker ' pytorch_cuda_alloc_conf ' metode for å spesifisere en ' max_split_size_mb ” for et PyTorch-prosjekt.
Konklusjon
Bruke ' pytorch_cuda_alloc_conf ”-metoden for å tildele CUDA-minne ved å bruke et av de tilgjengelige alternativene i henhold til kravene til modellen. Disse alternativene er ment å lindre et bestemt behandlingsproblem i PyTorch-prosjekter for bedre kjøretid og jevnere drift. I denne artikkelen har vi vist frem syntaksen for å bruke ' max_split_size_mb ' alternativet for å definere maksimal størrelse på delingen.