Kunstig intelligens er en av de raskest voksende teknologiene som bruker maskinlæringsalgoritmer for å trene og teste modeller ved hjelp av enorme data. Dataene kan lagres i forskjellige formater, men for å lage store språkmodeller ved bruk av LangChain, er den mest brukte typen JSON. Opplærings- og testdataene må være klare og fullstendige uten uklarheter, slik at modellen kan fungere effektivt.
Denne veiledningen vil demonstrere prosessen med å bruke den pydantiske JSON-parseren i LangChain.
Hvordan bruke Pydantic (JSON) Parser i LangChain?
JSON-dataene inneholder tekstformatet til data som kan samles inn gjennom nettskraping og mange andre kilder som logger osv. For å validere nøyaktigheten til dataene bruker LangChain det pydantiske biblioteket fra Python for å forenkle prosessen. For å bruke den pydantiske JSON-parseren i LangChain, gå ganske enkelt gjennom denne veiledningen:
Trinn 1: Installer moduler
For å komme i gang med prosessen, installer ganske enkelt LangChain-modulen for å bruke bibliotekene for bruk av parseren i LangChain:
pip installere langkjede
Bruk nå ' pip installasjon ” kommando for å få OpenAI-rammeverket og bruke ressursene:
pip installere openai
Etter å ha installert modulene, koble til OpenAI-miljøet ved å oppgi API-nøkkelen ved å bruke ' du ' og ' få pass ' biblioteker:
importere ossimportere getpass
os.miljø [ 'OPENAI_API_KEY' ] = getpass.getpass ( 'OpenAI API Key:' )

Trinn 2: Importer biblioteker
Bruk LangChain-modulen til å importere de nødvendige bibliotekene som kan brukes til å lage en mal for ledeteksten. Malen for forespørselen beskriver metoden for å stille spørsmål på naturlig språk slik at modellen kan forstå forespørselen effektivt. Importer også biblioteker som OpenAI og ChatOpenAI for å lage kjeder ved å bruke LLM-er for å bygge en chatbot:
fra langchain.prompts import (PromptTemplate,
ChatPromptTemplate,
HumanMessagePromptTemplate,
)
fra langchain.llms importerer OpenAI
fra langchain.chat_models importer ChatOpenAI
Etter det, importer pydantiske biblioteker som BaseModel, Field og validator for å bruke JSON-parser i LangChain:
fra langchain.output_parsers importer PydanticOutputParserfra pydantic import BaseModel, Field, validator
fra å skrive importliste
Trinn 3: Bygg en modell
Etter å ha fått alle bibliotekene for bruk av pydantisk JSON-parser, kan du ganske enkelt få den forhåndsdesignede testede modellen med OpenAI()-metoden:
modellnavn = 'text-davinci-003'temperatur = 0,0
modell = OpenAI ( modell navn =modellnavn, temperatur = temperatur )
Trinn 4: Konfigurer Actor BaseModel
Bygg en annen modell for å få svar relatert til skuespillere som navn og filmer ved å be om filmografien til skuespilleren:
klasseskuespiller ( BaseModel ) :navn: str = Felt ( beskrivelse = 'Navn til hovedrolleinnehaver' )
filmnavn: Liste [ str ] = Felt ( beskrivelse = 'Filmer der skuespilleren var hovedrollen' )
actor_query = 'Jeg vil se filmografien til enhver skuespiller'
parser = PydanticOutputParser ( pydantisk_objekt =skuespiller )
prompt = PromptTemplate (
mal = 'Svar på spørsmålet fra brukeren. \n {format_instructions} \n {spørsmål} \n ' ,
input_variables = [ 'spørsmål' ] ,
partielle_variabler = { 'format_instructions' : parser.get_format_instructions ( ) } ,
)
Trinn 5: Testing av basismodellen
Få utdataene ved å bruke funksjonen parse() med utdatavariabelen som inneholder resultatene generert for ledeteksten:
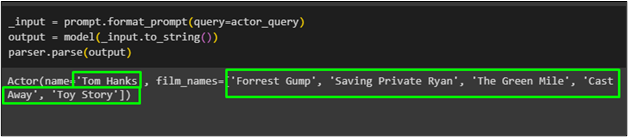
_input = prompt.format_prompt ( spørsmål =actor_query )utgang = modell ( _input.to_string ( ) )
parser.parse ( produksjon )
Skuespilleren som heter ' Tom Hanks ” med listen over filmene hans har blitt hentet ved hjelp av den pydantiske funksjonen fra modellen:
Det handler om å bruke den pydantiske JSON-parseren i LangChain.
Konklusjon
For å bruke den pydantiske JSON-parseren i LangChain, installer ganske enkelt LangChain- og OpenAI-moduler for å koble til ressursene og bibliotekene deres. Etter det, importer biblioteker som OpenAI og pydantic for å bygge en basismodell og verifisere dataene i form av JSON. Etter å ha bygget grunnmodellen, utfør funksjonen parse(), og den returnerer svarene for ledeteksten. Dette innlegget demonstrerte prosessen med å bruke pydantisk JSON-parser i LangChain.