Elasticsearch er en robust, godt likt løsning for å lagre store, ustrukturerte og semi-strukturelle data. Det er en ren NoSQL-database og bruker en helt annen tilnærming for å lagre, administrere og hente data. Den lagrer data i et dokument i JSON-format og bruker hvile-APIer for å utføre forskjellige operasjoner på lagrede data.
I denne bloggen vil vi demonstrere:
- Hvordan fungerer Elasticsearch for å lagre og søke etter data?
- Hva er Elasticsearch-dokumenter?
- Hvordan lagre data i et Elasticsearch-dokument?
Hvordan fungerer Elasticsearch for å lagre og søke etter data?
Elasticsearch-hovedkomponentene eller -hierarkiet som brukes til å lagre data er oppført nedenfor:
- Dokument: Dokumentet er hoveddelen av Elasticsearch som lagrer data i JSON-format. Som
- Indekser: Indekser omtales som indekser. Det er en samling av dokumenter. Som i SQL, blir det referert til som en database.
- Inverterte indekser: Den støtter svært raskt fulltekstsøk. Den lagrer ordet som en indeks og navnet på dokumentet som referanse.
Hva er Elasticsearch-dokumenter?
Elasticsearch-dokumentet er en lagringsenhet av data i JSON-format. Som i relasjonsdatabaser kan dokumentet refereres til som en tabell eller en rad i en database som er lagret i en eller annen indeks. Indeksen kan ha flere dokumenter og omtales som en database som har flere tabeller. Den lagrer vanligvis en kompleks datastruktur og steriliserer dataene i JSON-format.
I tillegg kan hvert dokument inneholde flere felt som er ' nøkkel:verdi ” parer for å lagre dataene akkurat som en tabell har flere kolonner eller felt i en relasjonsdatabase. Deretter skal disse nøkkelverdi-parene indekseres på en måte som bestemmer dokumenttilordningen. Kartleggingen definerer deretter datatypen til dokumentet i henhold til feltdataene som tekst, flytepunkt, geopunkt, tid og mange flere.
Elasticsearch har aldri bundet oss til å forhåndsdefinere indeksfeltstrukturen, og dokumentene kan ha forskjellig feltstruktur i en indeks. Men hvis kartleggingen av feltet er definert for en spesifikk datatype, må alle Elasticsearch-dokumenter i en indeks følge samme kartleggingstype. For å sjekke hvordan dokumentet fungerer for å lagre data i Elasticsearch, gå gjennom neste avsnitt.
Hvordan lagre data i et Elasticsearch-dokument?
For å lagre data i Elasticsearch, må brukeren først opprette en indeks. Deretter spesifiser feltene for å lagre dataene i Elasticsearch-dokumentet. For demonstrasjonen, gå gjennom de oppførte trinnene.
Trinn 1: Start Elasticsearch
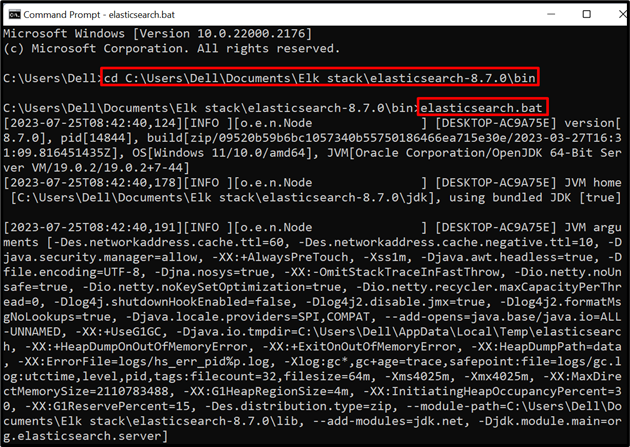
For å kjøre Elasticsearch-databasen eller -motoren på systemet, start systemterminalen, for eksempel kommandoprompt. Etter det, besøk ' bin '-mappen til Elasticsearch gjennom ' cd ' kommando:
cd C:\Users\Dell\Documents\Elk stack\elasticsearch-8.7.0\bin
Etter det, kjør batchfilen til Elasticsearch for å kjøre databasen på systemet:
elasticsearch.bat
Trinn 2: Start Kibana
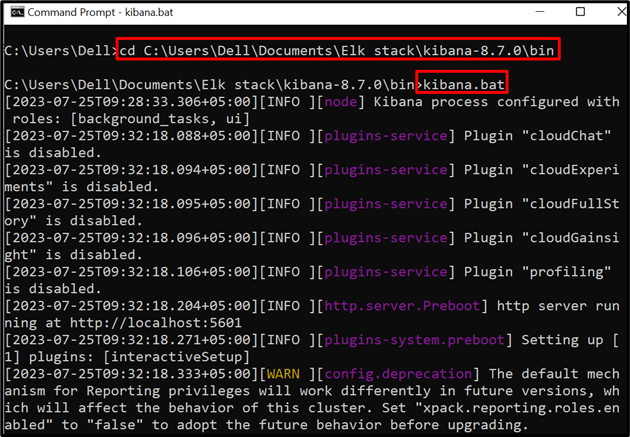
Deretter kjører du Kibana på systemet. For å gjøre det, besøk ' bin '-mappen fra ledeteksten:
cd C:\Users\Dell\Documents\Elk stack\kibana-8.7.0\bin
Kjør deretter kommandoen nedenfor for å begynne å utføre Kibana:
kibana.bat
Merk: Hvis du ikke har installert og satt opp Elasticsearch og Kibana på systemet, naviger til innleggene våre og sjekk ut trinn-for-trinn-prosedyren for å installere dem på systemet.
For Elasticsearch, besøk vår ' Installer og konfigurer Elasticsearch med .zip på Windows ' artikkel. For å sette opp Kibana på Windows, følg ' Sett opp Kibana for Elasticsearch ' artikkel.
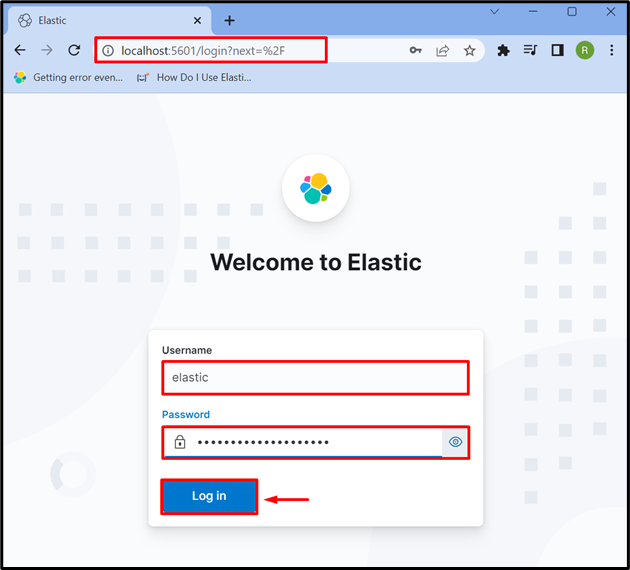
Trinn 3: Logg på Kibana
Etter å ha startet Kibana på systemet, naviger til standardadressen til Kibana ' lokal vert: 5601 ' i nettleseren, og oppgi påloggingsinformasjonen til Elasticsearch som ' elastisk ' bruker og passord. Deretter trykker du på ' Logg Inn ”-knapp:
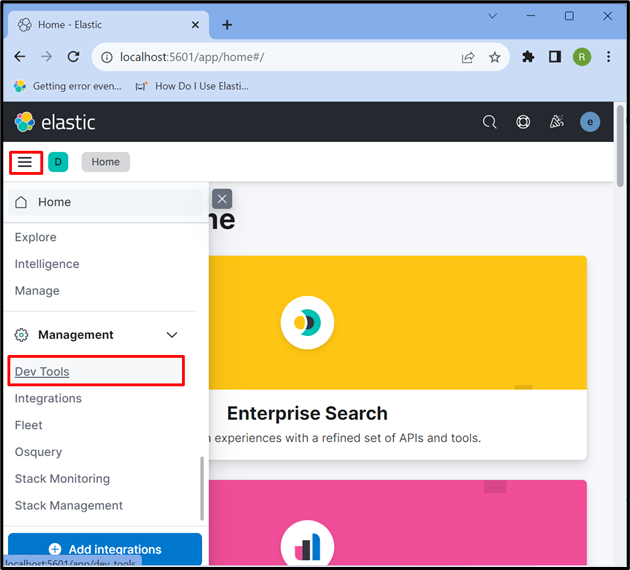
Trinn 4: Åpne Kibana 'Dev Tool'
Etter det klikker du på ' Tre horisontale stenger '-ikonet og åpne Kibana ' Utviklerverktøy ' for å bruke APIer til å lagre, hente og oppdatere dataene:
Trinn 5: Lag indeks
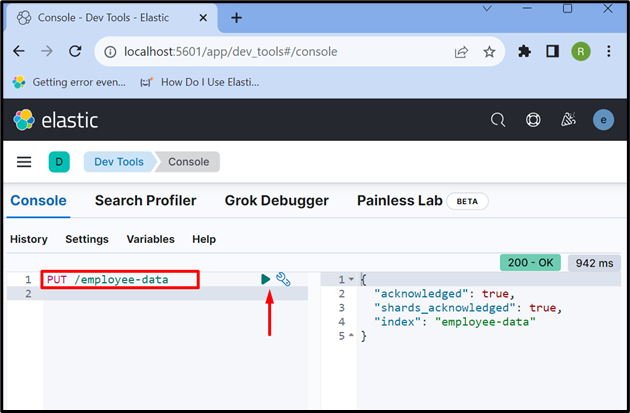
Opprett nå en ny indeks med ' PUT /
Utgangen viser at ' ansatt-data '-indeksen er opprettet:
Trinn 6: Sett inn data i dokumentet
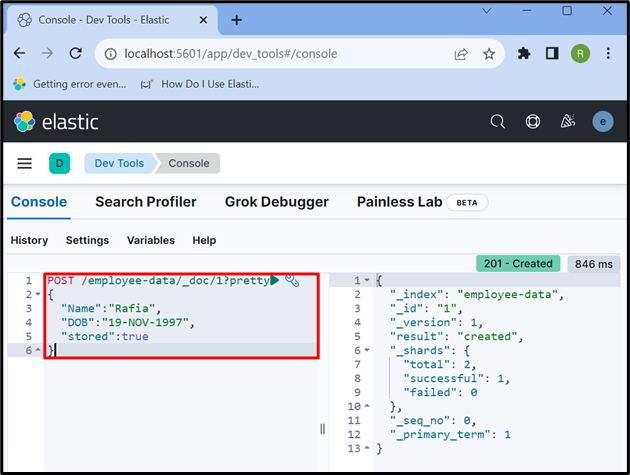
Bruk nå ' POST ” API for å lagre dataene i indeksen. I forespørselen nedenfor, ' ansatt-data ' er en indeks av Elasticsearch, ' _dok ' brukes til å lagre data i Elasticsearch-dokumentet, og ' 1 ' er id:
POST / ansatt-data / _dok / 1 ?ganske{
'Navn' : 'Raffia' ,
'DOB' : '19-NOV-1997' ,
'lagret' :ekte
}
Trinn 7: Hent data fra Elasticsearch-dokumentet
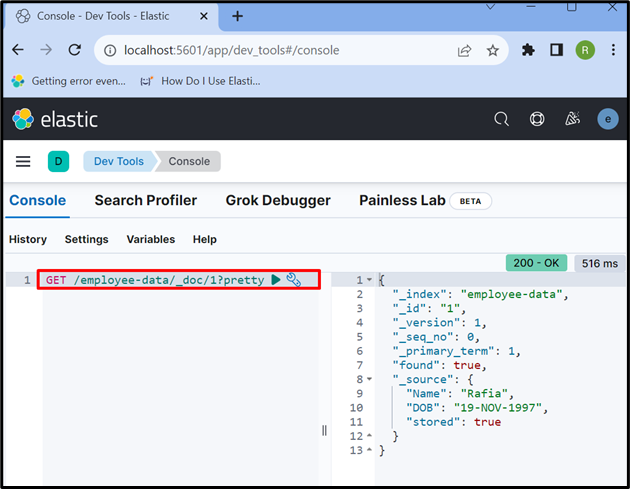
For å få tilgang til dataene fra indeksen eller Elasticsearch-dokumentet, bruk ' FÅ ' API som brukt nedenfor:
FÅ / ansatt-data / _dok / 1 ?ganske
Utdataene viser at vi har hentet ut dataene fra Elasticsearch-dokumentet med id ' 1 ':
Det handler om Elasticsearch-dokumentet.
Konklusjon
Elasticsearch-dokumentet brukes vanligvis til å lagre data i JSON-format. Som i relasjonsdatabaser kan dokumentet refereres til som en rad som er lagret i en eller annen indeks. Disse indeksene kan ha flere dokumenter akkurat som databaser har forskjellige tabeller. Disse dokumentene inneholder flere felt som er ' nøkkel:verdi ” parer for å lagre dataene. Denne artikkelen har demonstrert hva som er Elasticsearch-dokumenter og hvordan de fungerer i Elasticsearch.