Data samles inn i enorme mengder daglig, og håndtering av big data er den viktigste bruken av Elasticsearch-motoren. Dataene lagres i analysedatabasen i sanntid, og brukeren har lov til å trekke ut data for å finne nyttig kunnskap fra dem ved hjelp av spørringer. Brukeren kan bruke spørringer for å finne data fra flere indekser og vise dem i en enkelt bøtte fra relasjonsdatabasen.
Denne veiledningen vil forklare Elasticsearch-aggregeringene med eksempler som bruker forskjellige aggregasjoner.
Hva er Elasticsearch Aggregation?
I Elasticsearch er aggregering prosessen med å kombinere eller gruppere feltene for å trekke ut informasjon fra relasjonsdatabasen. Aggregeringen i Elasticsearch kan betraktes som GRUPPE ETTER KLAUSUL eller AGGREGAT() funksjon i SQL-språket.
Hvordan bruke Elasticsearch Aggregation?
For å bruke aggregeringen i Elasticsearch, må brukeren ha en grunnleggende forståelse av databasen sin. La oss utforske syntaksen og dens praktiske implementering:
Syntaks
For å finne data fra databasen, syntaksen til aggregeringen i Elasticsearch-motoren som nedenfor:
'aggs' : {'navn_på_aggregation' : {
'type_aggregering' : {
'felt' : 'document_field_name'
}
Utdragene ovenfor:
-
- Den bruker ' aggs ” nøkkelord som forklarer bruken av aggregering i spørringen.
- De navn_på_aggregering settes av brukeren i henhold til nødvendig informasjon.
- Etter det har type_aggregering brukes til å hente data.
- Den siste linjen bruker felt nøkkelord som etterfølges av navnet på attributtet fra dokumentet.
Eksempel 1: Aggregering i Kibana-eksempeldata
Denne delen forklarer aggregeringen ved hjelp av et eksempel ved å bruke eksempeldataene fra Kibana ved å koble til den først. Etter det går du bare inn i ' Utviklerverktøy ' ved å søke på den fra søkefeltet og klikke på den:
Hent data fra eksempeldata
Bare bruk følgende kommando for å hente dataene fra ' kibana_sample_data_logs ”-indeksen på Dev Tools-konsollen:
FÅ / kibana_sample_data_logs / _Søk
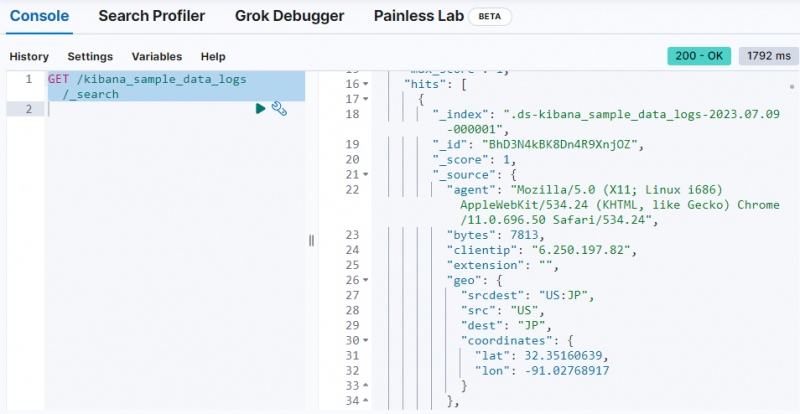
Utdataene viser at data har blitt hentet fra ' kibana_sample_data_logs ' indeks.
Følgende kode bruker en FÅ forespørsel på ' kibana_sample_data_log ' for å søke fra den ved å bruke aggregeringen av verdi_antall på ' klienttips ' felt:
FÅ / kibana_sample_data_logs / _Søk{ 'størrelse' : 0 ,
'aggs' : {
'ip_count' : {
'verditall' : {
'felt' : 'klienttips'
}
}
}
}
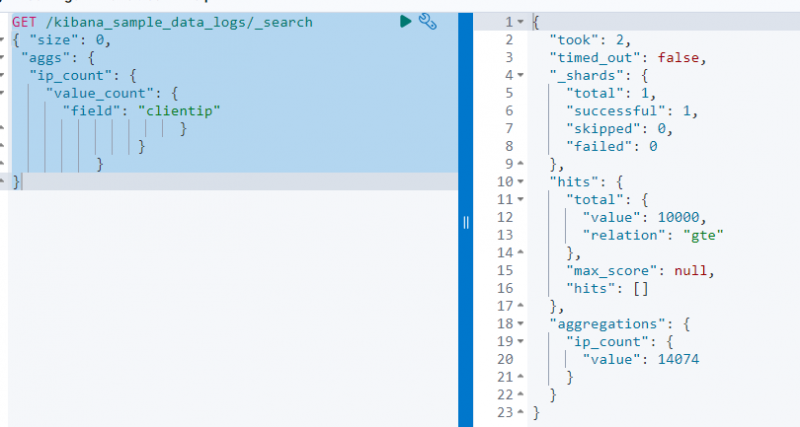
Skjermbildet ovenfor viser aggregeringen på klienttips feltet med verdien 14074 .
Viktige samlinger
Noen av de viktige aggregeringene som brukes for å finne data effektivt fra databasen er nevnt nedenfor:
Følgende eksempler forklarer de ovennevnte aggregeringene ved å bruke FÅ forespørsel fra ' kibana_sample_data_ecommerce 'indeks:
Kardinalitet Aggregasjon
Følgende kode bruker ' kardinalitet ' aggregering på ' sku ”-feltet fra e-handelsdataene. Kjøring av denne koden vil få enkeltverdiaggregering for å få de unike SKUene fra Elasticsearch-databasen:
FÅ / kibana_sample_data_ecommerce / _Søk{
'størrelse' : 0 ,
'aggs' : {
'unique_skus' : {
'kardinalitet' : {
'felt' : 'sku'
}
}
}
}
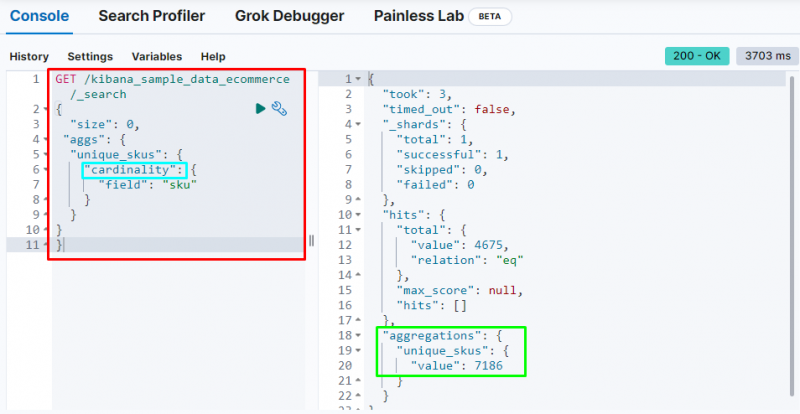
Den viser kardinalitet aggregering å finne 7186 verdier fra indeksen.
Statistikk Aggregasjon
En annen viktig aggregering er ' statistikk ' aggregering som brukes for å få ' telle ', ' min ', ' maks ', ' gj.sn ', og ' sum ' statistikk fra ' totalt antall ' felt:
FÅ / kibana_sample_data_ecommerce / _Søk{
'størrelse' : 0 ,
'aggs' : {
'quantity_stats' : {
'statistikk' : {
'felt' : 'totalt antall'
}
}
}
}
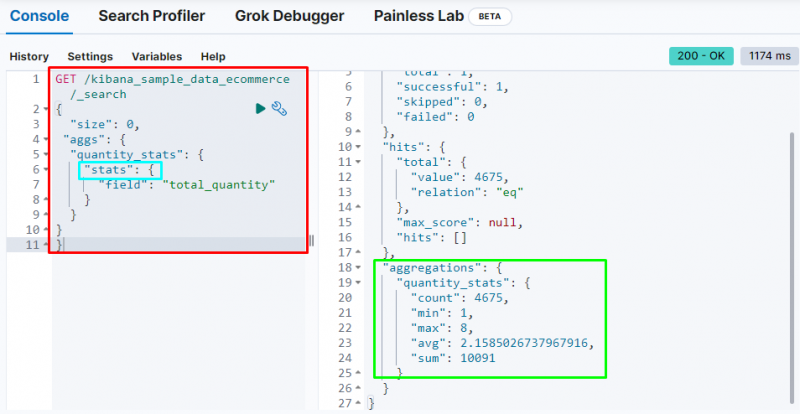
Skjermbildet ovenfor viser statistikken i utdataene fra ' totalt antall ' felt.
Filteraggregation
Filteraggregering brukes til å filtrere ut data basert på et begrep eller en frase fra databasen som følgende kode inneholder den:
FÅ / kibana_sample_data_ecommerce / _Søk{ 'størrelse' : 0 ,
'aggs' : {
'filter_aggregation' : {
'filter' : {
'begrep' : {
'bruker' : 'eddie' } } ,
'aggs' : {
'pris_gjennomsnitt' : {
'avg' : {
'felt' : 'produkter.pris' } }
} } } }
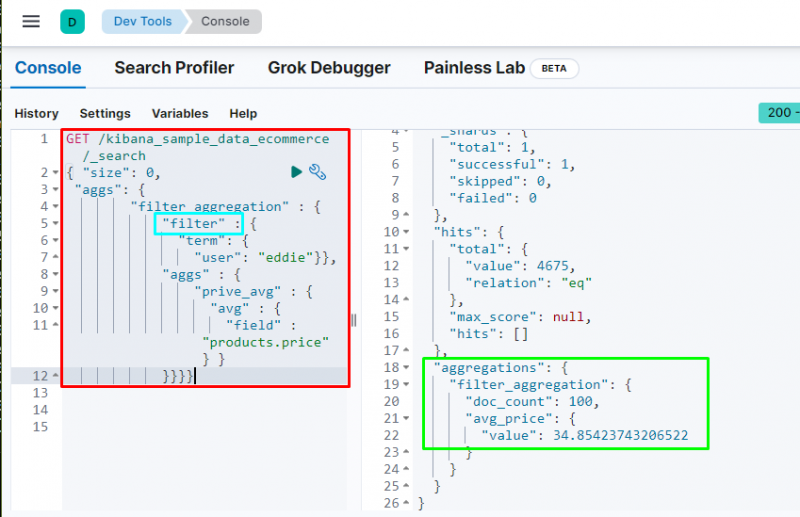
Utførelse av kode vil filtrere dataene basert på ' eddie ” bruker og viser gjennomsnittsprisen på varene som er kjøpt. Skjermbildet ovenfor viser at bruker har funnet 100 ganger fra dataene og verdi av gj.sn _ pris aggregering.
Term Aggregasjon
Begrepet aggregering lager en bøtte og lagrer data fra feltet i bøtte, og følgende kode bruker ' bruker '-feltet for å lagre dataene i bøtten:
FÅ / kibana_sample_data_ecommerce / _Søk{
'størrelse' : 0 ,
'aggs' : {
'Term_Aggregation' : {
'vilkår' : {
'felt' : 'bruker'
}
}
}
}
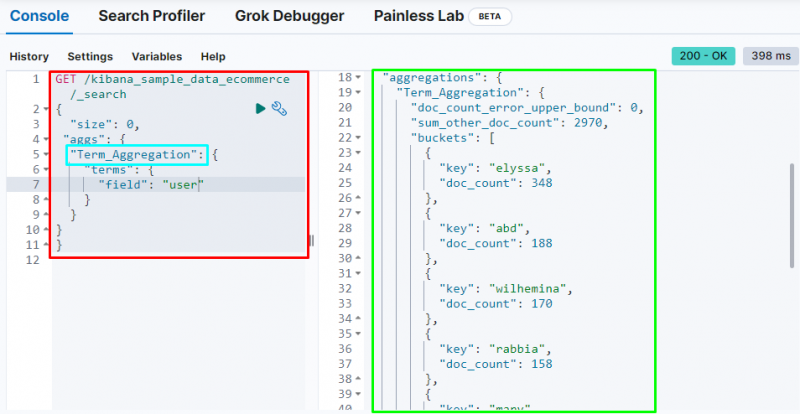
Følgende skjermbilde viser at begrepet aggregering har skapt samlinger for hver bruker og deres dokumentantall.
Det handler om Elasticsearch-aggregering og forskjellig viktig aggregering.
Konklusjon
I Elasticsearch brukes aggregeringen til å hente data fra de aggregerte dokumentene og disse dokumentene trekkes ut fra et spesifikt felt. Det er noen viktige aggregeringer som brukes for å få nyttig innsikt fra indeksene er forklart. Denne veiledningen har forklart Elasticsearch-aggregering og demonstrert prosessen med å bruke Elasticsearch-aggregering.