Denne veiledningen vil illustrere hvordan du bruker VectorStoreRetrieverMemory ved å bruke LangChain-rammeverket.
Hvordan bruke VectorStoreRetrieverMemory i LangChain?
VectorStoreRetrieverMemory er biblioteket til LangChain som kan brukes til å trekke ut informasjon/data fra minnet ved hjelp av vektorlagrene. Vektorlagre kan brukes til å lagre og administrere data for å effektivt trekke ut informasjonen i henhold til forespørselen eller spørringen.
For å lære prosessen med å bruke VectorStoreRetrieverMemory i LangChain, gå ganske enkelt gjennom følgende veiledning:
Trinn 1: Installer moduler
Start prosessen med å bruke memory retriever ved å installere LangChain ved å bruke pip-kommandoen:
pip installer langkjede
Installer FAISS-modulene for å få dataene ved å bruke det semantiske likhetssøket:
pip installer faiss-gpu 
Installer chromadb-modulen for bruk av Chroma-databasen. Det fungerer som vektorlageret for å bygge minnet for retrieveren:
pip installer chromadb 
En annen modul tiktoken er nødvendig for å installere som kan brukes til å lage tokens ved å konvertere data til mindre biter:
pip installer tiktoken 
Installer OpenAI-modulen for å bruke bibliotekene for å bygge LLM-er eller chatboter ved å bruke miljøet:
pip installer openai 
Sett opp miljøet på Python IDE eller notatbok ved å bruke API-nøkkelen fra OpenAI-kontoen:
import duimport få pass
du . omtrent [ 'OPENAI_API_KEY' ] = få pass . få pass ( 'OpenAI API Key:' )
Trinn 2: Importer biblioteker
Det neste trinnet er å hente bibliotekene fra disse modulene for å bruke minnehenteren i LangChain:
fra langkjede. spør import PromptTemplatefra dato tid import dato tid
fra langkjede. llms import OpenAI
fra langkjede. innebygginger . openai import ÅpneAIEbeddings
fra langkjede. kjeder import Samtalekjede
fra langkjede. hukommelse import VectorStoreRetrieverMemory
Trinn 3: Initialisering av Vector Store
Denne veiledningen bruker Chroma-databasen etter import av FAISS-biblioteket for å trekke ut dataene ved å bruke inndatakommandoen:
import faissfra langkjede. lege import InMemoryDocstore
#importing biblioteker for å konfigurere databaser eller vektorlagre
fra langkjede. vektorbutikker import FAISS
#lag innbygginger og tekster for å lagre dem i vektorlagrene
embedding_size = 1536
indeks = faiss. IndexFlatL2 ( embedding_size )
embedding_fn = ÅpneAIEbeddings ( ) . embed_query
vectorstore = FAISS ( embedding_fn , indeks , InMemoryDocstore ( { } ) , { } )
Trinn 4: Building Retriever støttet av en Vector Store
Bygg opp minnet for å lagre de siste meldingene i samtalen og få konteksten til chatten:
retriever = vectorstore. as_retriever ( search_kwargs = dikt ( k = 1 ) )hukommelse = VectorStoreRetrieverMemory ( retriever = retriever )
hukommelse. lagre_kontekst ( { 'inngang' : 'Jeg liker å spise pizza' } , { 'produksjon' : 'Fantastisk' } )
hukommelse. lagre_kontekst ( { 'inngang' : 'Jeg er god i fotball' } , { 'produksjon' : 'ok' } )
hukommelse. lagre_kontekst ( { 'inngang' : 'Jeg liker ikke politikken' } , { 'produksjon' : 'sikker' } )
Test minnet til modellen ved å bruke input fra brukeren med historikken:
skrive ut ( hukommelse. load_memory_variables ( { 'spørre' : 'hvilken sport bør jeg se?' } ) [ 'historie' ] ) 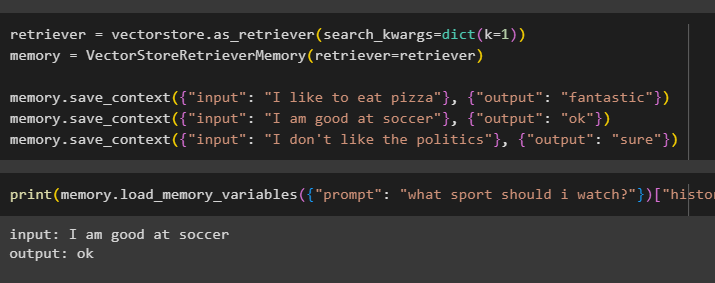
Trinn 5: Bruk av retriever i en kjede
Det neste trinnet er bruken av en minnehenter med kjedene ved å bygge LLM ved å bruke OpenAI()-metoden og konfigurere ledetekstmalen:
llm = OpenAI ( temperatur = 0 )_DEFAULT_MAL = '''Det er et samspill mellom et menneske og en maskin
Systemet produserer nyttig informasjon med detaljer ved hjelp av kontekst
Hvis systemet ikke har svaret for deg, sier det ganske enkelt at jeg ikke har svaret
Viktig informasjon fra samtalen:
{historie}
(hvis teksten ikke er relevant, ikke bruk den)
Nåværende chat:
Menneske: {input}
AI:'''
SPILL = PromptTemplate (
input_variables = [ 'historie' , 'inngang' ] , mal = _DEFAULT_MAL
)
#configure ConversationChain() ved å bruke verdiene for parameterne
samtale_med_sammendrag = Samtalekjede (
llm = llm ,
ledetekst = SPILL ,
hukommelse = hukommelse ,
ordrik = ekte
)
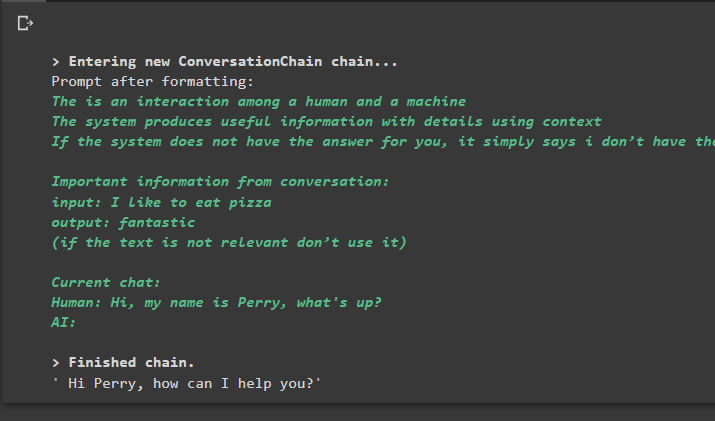
samtale_med_sammendrag. forutsi ( input = 'Hei, jeg heter Perry, hva skjer?' )
Produksjon
Utførelse av kommandoen kjører kjeden og viser svaret gitt av modellen eller LLM:
Kom i gang med samtalen ved å bruke ledeteksten basert på dataene som er lagret i vektorlageret:
samtale_med_sammendrag. forutsi ( input = 'hva er favorittsporten min?' ) 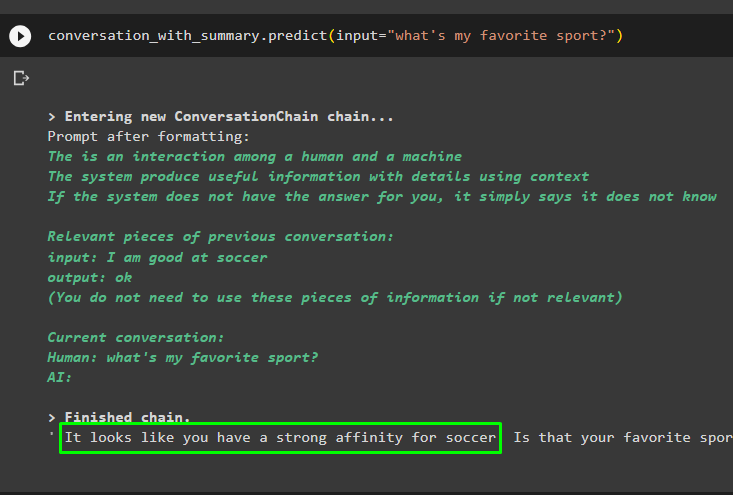
De forrige meldingene er lagret i modellens minne som kan brukes av modellen for å forstå konteksten til meldingen:
samtale_med_sammendrag. forutsi ( input = 'Hva er favorittmaten min' ) 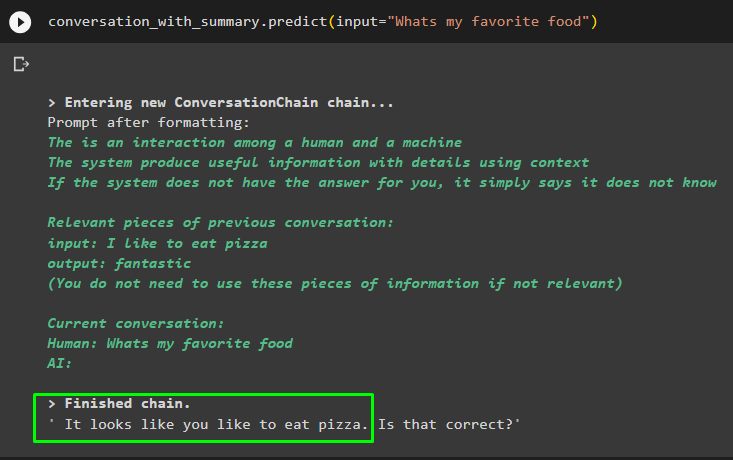
Få svaret gitt til modellen i en av de forrige meldingene for å sjekke hvordan minnehenteren fungerer med chat-modellen:
samtale_med_sammendrag. forutsi ( input = 'Hva er mitt navn?' )Modellen har vist utdataene riktig ved å bruke likhetssøket fra dataene som er lagret i minnet:
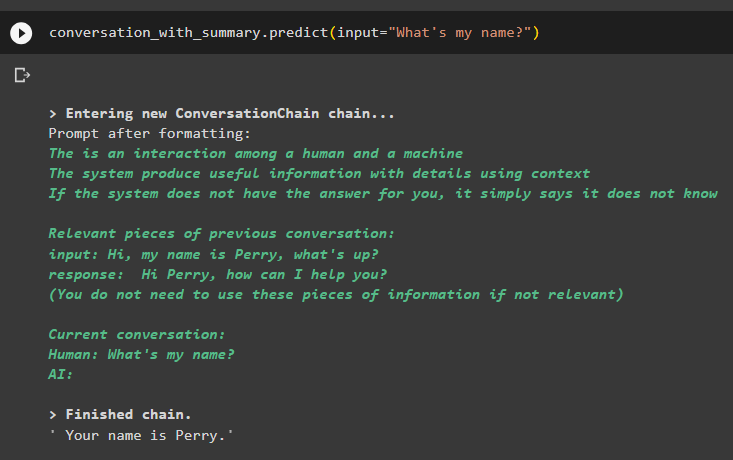
Det handler om å bruke vektorbutikk-retrieveren i LangChain.
Konklusjon
For å bruke minnegjenvinneren basert på et vektorlager i LangChain, installerer du bare modulene og rammeverkene og setter opp miljøet. Deretter importerer du bibliotekene fra modulene for å bygge databasen ved hjelp av Chroma og setter deretter ledetekstmalen. Test retrieveren etter å ha lagret data i minnet ved å starte samtalen og stille spørsmål knyttet til de forrige meldingene. Denne veiledningen har utdypet prosessen med å bruke VectorStoreRetrieverMemory-biblioteket i LangChain.