Pandas Set_Option Method
I dag skal vi se på hvordan du bruker 'pd.set_option()'-funksjonen for å vise alle kolonnene i Pandas Dataframe når du presenterer den i Spyder-verktøyet ditt. For å bruke 'pd.set_option()', følger vi den gitte syntaksen:

La oss begynne å lære konseptet ved hjelp av den praktiske implementeringen av Python-programmet.
Eksempel: Bruke Pandas Set_Option-metode for å vise alle kolonnene
Denne demonstrasjonen er en veiledning for å vise alle kolonnene i en DataFrame ved å bruke Pandas 'set_option()'. Vi vil tydeliggjøre detaljene for hvert trinn for implementeringen av denne Python-metoden.
Det første kravet for praktisk implementering av Python-skriptet er å finne ut det beste verktøyet der du kjører programmet ditt. Verktøyet vi brukte til illustrasjonen vår er 'Spyder'-verktøyet. Vi lanserte verktøyet og begynte å jobbe med Python-skriptet.
Fra og med koden, må vi først importere de forutsetningsbibliotekene vi trenger i dette programmet. Det første biblioteket vi lastet inn i Python-filen vår er Pandas-biblioteket, da funksjonene vi bruker her er levert av Pandas. Vi kalte dette biblioteket som 'pd'. Det andre biblioteket vi lastet inn er NumPy-biblioteket. NumPy (Numerical Python) er en numerisk datapakke utviklet over Python-programmering. Importer NumPy-delen av koden ber Python om å integrere NumPy-modulen i din nåværende Python-fil. 'Som np'-delen av skriptet instruerer Python om å tilordne NumPy 'np'-forkortelsen. Den lar deg bruke NumPy-metodene ved å skrive inn 'np.function_name' i stedet for NumPy.
Nå begynner vi med hovedkoden. Det fremste og grunnleggende behovet for programmet vårt er Pandas DataFrame. Så vi viser alle kolonnene den inneholder. Nå er det helt opp til deg om du vil lage en DataFrame med spesifiserte verdier eller om du trenger å importere en CSV-fil. Det vi valgte for denne forekomsten var å lage en DataFrame med NaN-verdier. Vi påkalte 'pd.DataFrame()'-metoden for å konstruere en DataFrame. Her ga vi to parametere - 'indeks' og 'kolonner'. Argumentet 'indeks' refererer til radene som betyr at vi setter radene for DataFrame.
Vi tildelte 'indeks'-parameteren og NumPy-funksjonen 'np.arange() med et verdiantall på '6'. Den genererer seks rader for DataFrame. Den fyller alle oppføringene med NaN-verdier siden vi ikke har gitt den noen verdi. Argumentet 'kolonner', som navnet spesifiserer, brukes til å angi kolonnene for DataFrame. Den er også tildelt 'np.arange()'-funksjonen med '25' verdiantall for kolonnene. Dermed konstruerer den 25 kolonner for DataFrame.
Følgelig, når vi kaller 'pd.DataFrame()'-funksjonen, har vi en DataFrame med 25 kolonner og 6 rader fylt med nullverdier. For behovet for å bevare denne DataFrame, er vi pålagt å bygge et DataFrame-objekt som lagrer innholdet. Derfor opprettet vi et DataFrame-objekt 'tilfeldig' og tildelte det resultatet som vi får fra 'pd.DataFrame()'-metoden. Nå vil du sikkert se at DataFrame blir generert. Python gir oss en metode for å se utdataene på skjermen som er 'print()'-funksjonen. Vi påkalte denne metoden ved å sende DataFrame-objektet 'tilfeldig' som parameter.
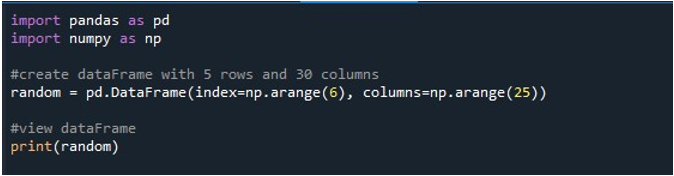
Når vi kjører denne kodebiten, får vi vår DataFrame med NaN-verdier vist på terminalen. Her kan vi observere at noen av de første kolonnene og bare noen få fra slutten er synlige. Alle de mellomliggende kolonnene er avkortet. Som standard skjuler den noen av radene og kolonnene for å unngå å skape frustrasjon for brukeren ved å vise enorme datasett.
Du kan til og med sjekke antall totale kolonner i en DataFrame ved å bruke 'len()'-funksjonen til Pandas. Skriv 'len()'-funksjonen på konsollen til 'Spyder'-verktøyet ditt. Skriv DataFrames navn mellom parentesene med egenskapen '.columns'. Den returnerer oss den totale lengden på kolonnene i DataFrame.

Den returnerer lengden på vår DataFrame som er 25.
Nå er den neste og kjerneoppgaven å endre standardalternativet for å vise utdataene. Det kan være omstendigheter der du vil se hele DataFrame på terminalen. På grunn av standardverdiene blir mange oppføringer avkortet, noe som forårsaker skuffelse for brukeren. Du vil lære her hvordan du kan løse dette problemet. Pandas gir oss en 'pd.set_option()'-funksjon for å endre standard skjerminnstillinger. Rett etter å ha vist DataFrame på konsollen, påkaller vi 'pd.set_option()'-metoden. Vi spesifiserer parameteren mellom parentesene til denne funksjonen som vi må bruke for å vise alle kolonnene i DataFrame.
Her brukte vi 'display.max_columns' for å vise de maksimale kolonnene i vår DataFrame. Vi kan også definere verdien for denne parameteren, dvs. de maksimale kolonnene du ønsker å vise. Vi på den annen side setter 'display.max_columns' til 'Ingen' som viser alle kolonnene fra DataFrame med maksimal lengde. Til slutt brukte vi 'print()'-funksjonen for å vise den resulterende DataFrame med alle kolonnene synlige på terminalen.
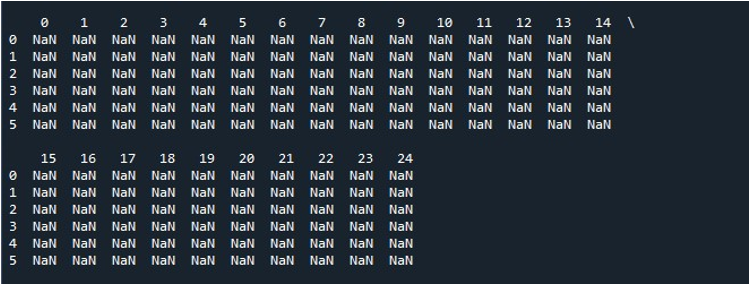
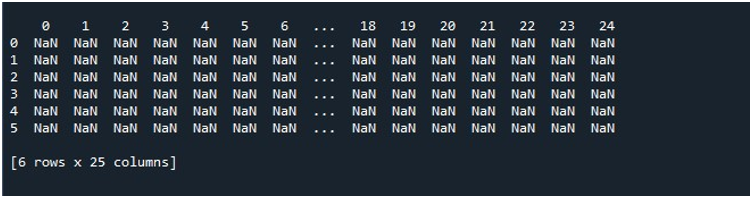
Når vi trykker på 'Kjør fil'-alternativet på 'Spyder'-verktøyet, kan vi se en DataFrame som vises. Denne DataFrame har seks rader og antall kolonner den har er 25. Det er ingen kolonner som er avkortet siden 'pd.set_option()'-funksjonen med maksimal kolonnelengde er aktivert nå.
Vi kan til og med tilbakestille visningsalternativet fordi når vi har satt skjermlengden til maksimum, fortsetter den å vise DataFrames med alle kolonnene i den aktuelle Python-filen. For dette bruker vi Pandaene 'pd.reset_option()'. Vi påkaller denne funksjonen og gir 'display.max_columns' som parameter for denne funksjonen.

Dette gir oss de første skjerminnstillingene for den medfølgende DataFrame.
Konklusjon
Å se hele utdataene på terminalen med et stort datasett får oss noen ganger i problemer når verktøyets standardinnstillinger kommer i kontrast til brukerens behov. For å løse dette tilbakeslaget gir Pandas oss metoden 'pd.set_option()'. I denne læringsguiden introduserte vi deg for denne metoden og behovet for å bruke den. Vi demonstrerte emnet med de praktisk kompilerte og utførte Python-eksempelkodene. Vi gjengav resultatene av illustrasjonen utført på 'Spyder'. Vi forklarte hvordan du viser alle kolonnene i DataFrame på konsollen ved å endre standardinnstillingene samt tilbakestille alle innstillingene til initial. Ved å gi en fullt fokusert oppmerksomhet til den praktiske implementeringen av modulen, kan du bruke den når du støter på slike problemer.