Denne artikkelen gir instruksjoner for implementering av Intelligent-Tiering for å optimalisere kostnadene i S3-bøtten.
Hva er Intelligent Tiering i S3 Bucket?
Data vokser eksponentielt over hele kloden. Noen av disse dataene er tilgjengelig daglig, mens resten bare er nødvendig av og til. Siden S3 er en av de mest populære tjenestene til AWS for datalagring, har AWS introdusert en lagringsklasse kjent som “Intelligent Tiering” å kutte utgiftene til S3 på grunn av datalagring. Lær mer om forskjellige lagringsklasser av S3-bøtter ved å referere til denne artikkelen: 'En oversikt over forskjellige lagringsklasser på S3' .
Intelligent-Tiering kan optimere S3-utgiftene ved å overvåke datatilgangsmønstrene. Denne funksjonen er effektiv nok til å bestemme hvilke data som brukes ofte eller av og til. Basert på disse mønstrene identifiserer den automatisk og plasserer dem i det mest kostnadseffektive nivået uten driftskostnader eller ytelsesreduksjon.
Hvordan optimalisere datalagringskostnader i Amazon S3 med intelligent nivå?
Avhengig av datatilgangsmønstrene, vil objektene som er sjelden tilgang til, plasseres i rimeligere tilgangsnivå for optimale kostnadsformål. Hvis objektet åpnes av brukeren, vil det automatisk og umiddelbart flyttes tilbake til Frequent Access Tier for tilgjengelighet uten ekstra kostnader:
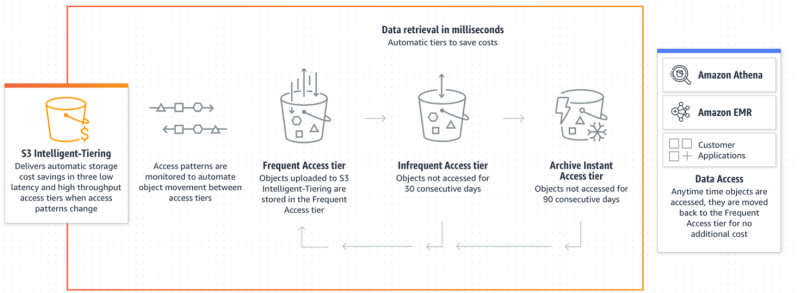
Intelligent Tiering er et gjennomførbart og ideelt valg for brukere når det gjelder å optimalisere kostnader for uforutsigbare datatilgangsmønstre. Følgende er trinnene der vi kan implementere Intelligent-Tiering Storage Class for kostnadseffektivitet:
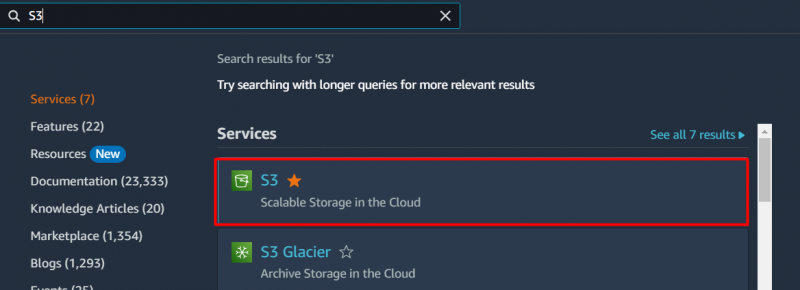
Trinn 1: S3 Dashboard
For å oppnå en kostnadsoptimal løsning for datalagring med S3-bøtten, søk på 'S3' tjeneste i AWS-søkefeltet og klikk på den fra resultatene som vises:
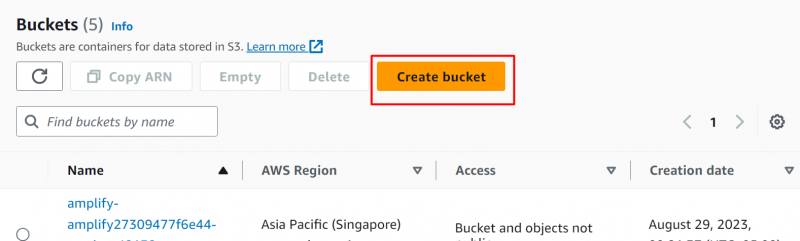
Trinn 2: Lag bøtte
Klikk på 'Opprett bøtte' knappen på S3-konsoll :
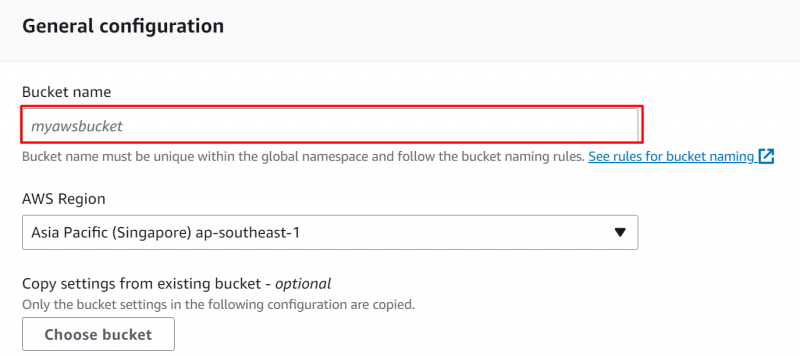
Trinn 3: Generelle konfigurasjoner
Fra grensesnittet som vises, oppgi en unik identifikator for S3-bøtta i 'Generelle konfigurasjoner' seksjon:
Trinn 4: Trykk på 'Opprett bøtte'-knappen
Ved å beholde standardinnstillingene, klikk på 'Opprett bøtte' knappen nederst i grensesnittet:
Bøtten er opprettet. Deretter laster vi opp en fil til denne bøtten. Klikk på bøttenavnet for å navigere til opplastingsfilgrensesnittet:
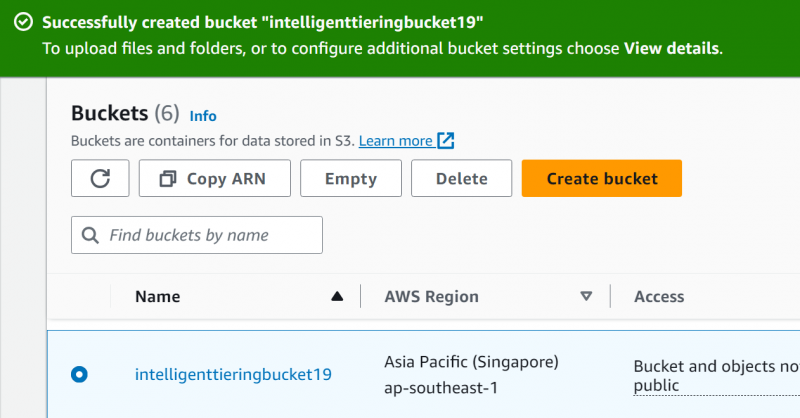
Trinn 5: Last opp filer
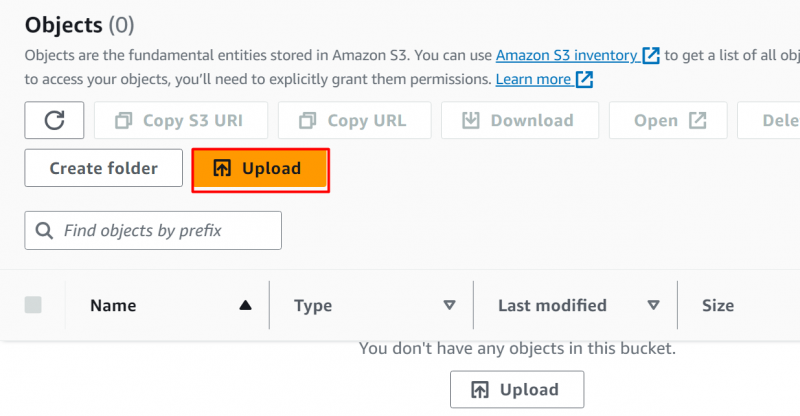
Klikk på 'Laste opp' knappen på det viste grensesnittet:
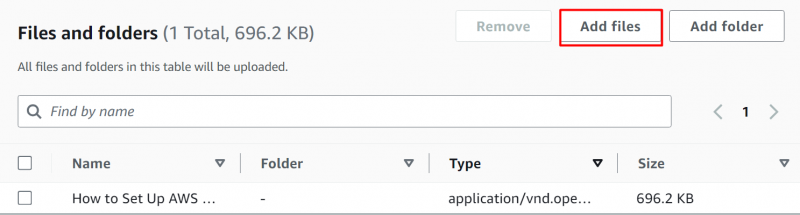
For å velge filer, klikk på 'Legg til filer' og velg deretter filene/mappene fra enheten. Filen er lastet opp til S3-bøtten:
Naviger til 'Egenskaper' blokker og velg ' Intelligent lagdeling” alternativ fra Oppbevaringsklasse seksjon :
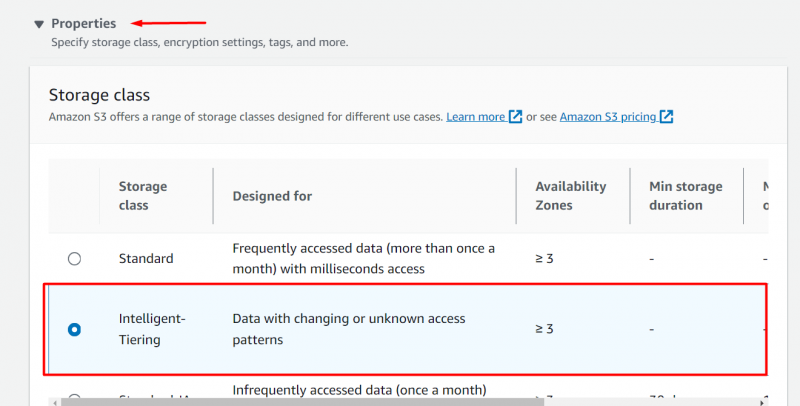
Ved å beholde resten av innstillinger uendret , Klikk på 'Laste opp' knapp nederst i grensesnittet:
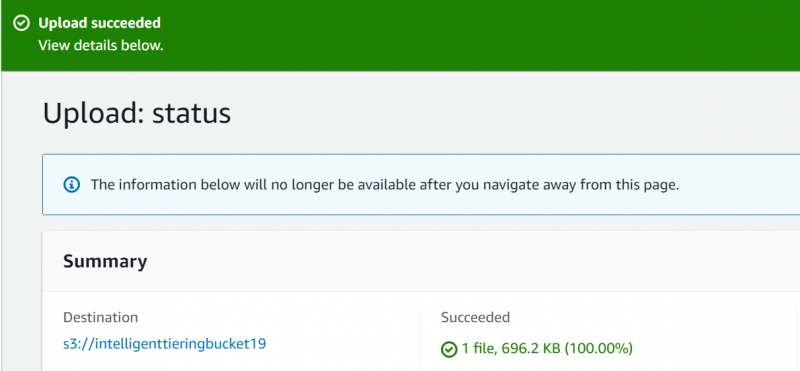
AWS vil vise en bekreftelsesmelding som indikerer at filen har blitt lastet opp:
Trinn 6: Trykk på fanen 'Egenskaper'.
Etter at filen er lastet opp, klikk på 'Egenskaper' fane:
Trinn 7: Intelligent-Tiering-arkivkonfigurasjoner
Fra Egenskaper grensesnitt, bla ned til 'Intelligent-Tiering-arkivkonfigurasjoner' og klikk på 'Opprett konfigurasjoner' knapp:
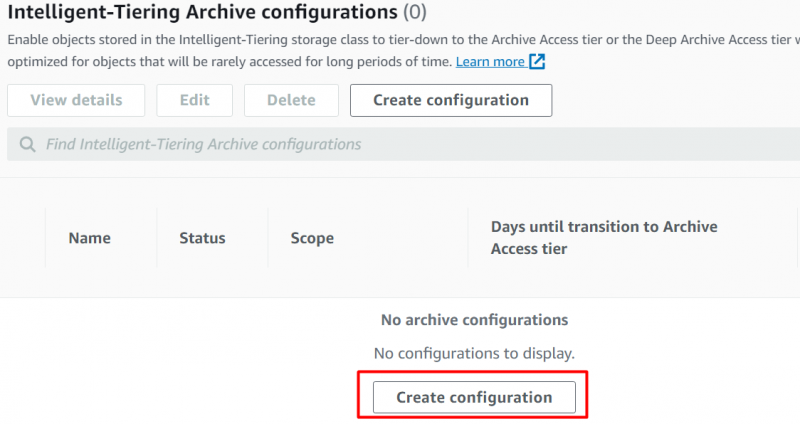
Gi 'Navn' og 'Prefiks' for konfigurasjoner på neste viste grensesnitt:
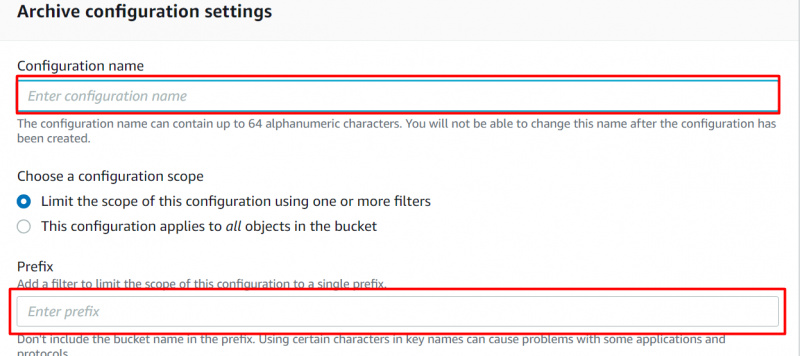
Trinn 8: Arkivtilgangsnivå
Naviger til «Arkiver regelhandlinger» seksjon for å konfigurere når objektene skal flyttes. Aktiver følgende alternativ og angi et antall påfølgende dager hvoretter du vil flytte objektene til «Arkivtilgangsnivå» :
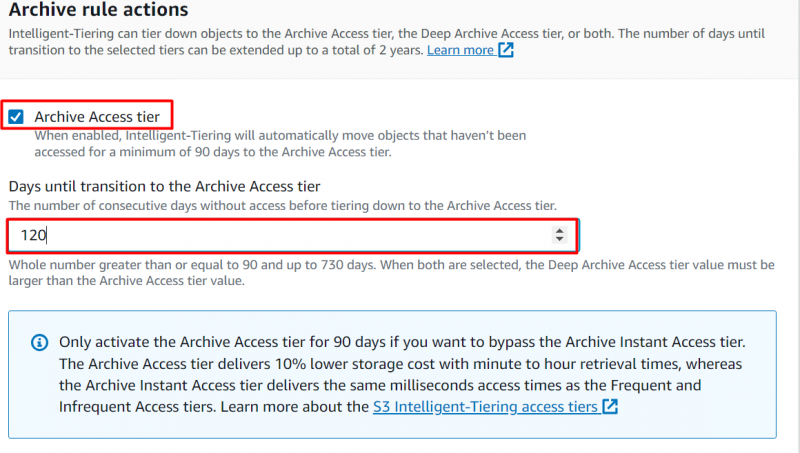
Merk : Hvis et objekt ikke er tilgjengelig for minimum 90 dager, objektet vil automatisk bli flyttet til arkivtilgangsnivået. Brukere kan utvide denne perioden til en maksimum av 730 dager.
Trinn 9: Deep Archive Access Tier
I likhet med arkivtilgangsnivået, kan brukeren også konfigurere arkivtilgangsnivået. Ved å aktivere følgende alternativ, angi antall dager som objektet skal flyttes til Deep Archive Access Tier. Etter å ha oppgitt antall dager, klikk på 'Skape' knapp:
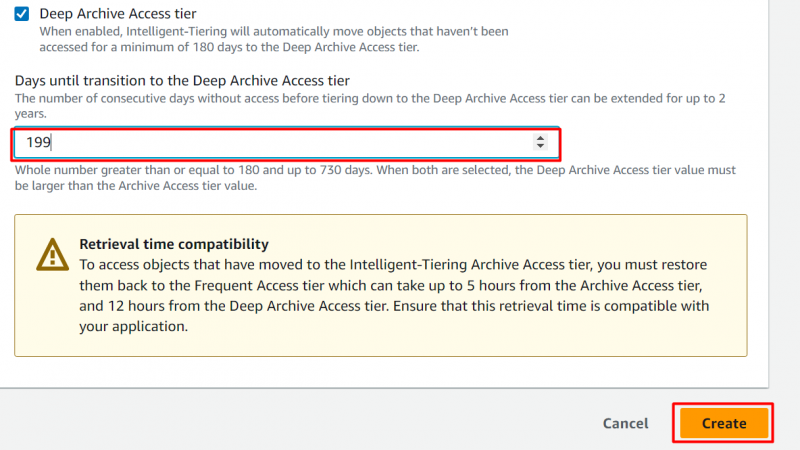
Merk : I Deep Archive Access Tier, objektene som ikke ble åpnet for en minimum 180 dager flyttes til dette nivået. Brukere kan tilpasse dette antall dager til en maksimalt 730 dager .
Konfigurasjonene er gjort vellykket. Nå, når brukeren ikke har tilgang til de opplastede objektene i den angitte tiden, vil dataene automatisk flyttes til forskjellige nivåer for å minimere kostnadene:
Det er alt fra denne guiden.
Konklusjon
For kostnadsoptimalisering med S3-bøtten, velg Klasse med intelligent nivå når du laster opp filer og oppgi deretter tiden for de respektive nivåene. Intelligent nivådeling sparer kostnadene ved å bestemme objektene som ofte og sjelden brukes til de respektive nivåene. Denne artikkelen gir trinnvise instruksjoner for å oppnå den kostnadsoptimale løsningen med en S3-bøtte.