Denne veiledningen vil forklare hvordan du oppretter crawlere for å hente data fra S3-bøtten.
Hvordan lage crawler for å hente data fra S3 Bucket?
For å opprette en crawler i AWS, gå til ' AWS lim ' tjeneste fra Amazon-dashbordet:
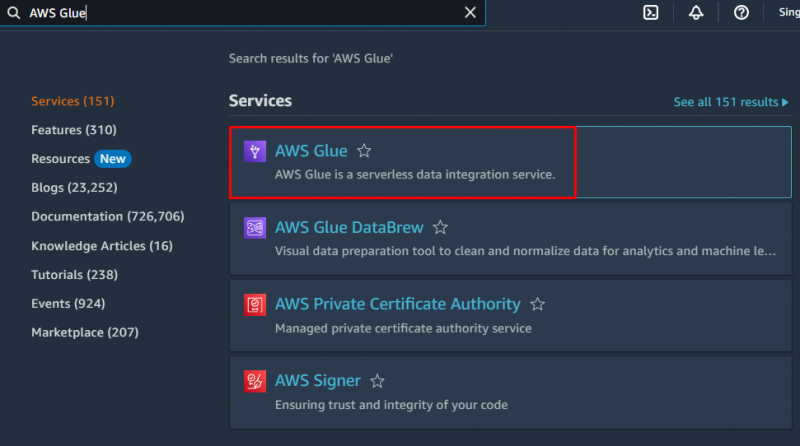
Klikk på ' Databaser ”-knappen fra Datakatalog-delen for å opprette en database:
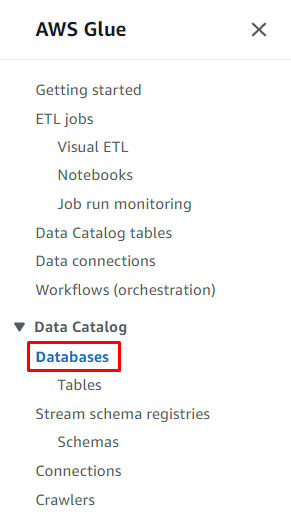
Klikk på ' Legg til database '-knappen for å starte konfigurasjonen:
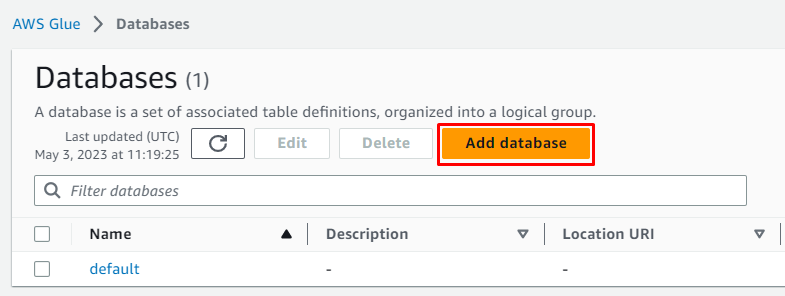
Skriv inn navnet på databasen og la alt være som det er valgfritt før du klikker på ' Opprett database ”-knapp:
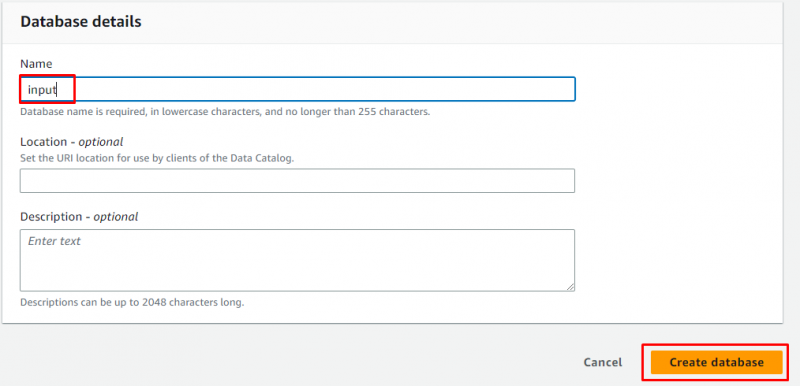
Databasen er opprettet:
Etter det går du bare til ' Crawlere ”-siden ved å klikke på den fra venstre panel:
Klikk på ' Opprett crawler ”-knapp:

Skriv inn navnet på søkeroboten og klikk på ' Neste ”-knapp:

Klikk på ' Legg til en datakilde '-knappen for å velge kilden til dataene:
For å sjekke banen hvor dataene er lagret, besøk S3-tjenesten:
Gå inn i S3-bøtten der dataene lastes opp. Brukeren kan skape en bøtte og laste opp data på den fra AWS S3-dashbordet:

Klikk på ' Bla gjennom S3 '-knappen for å velge banen til dataene:
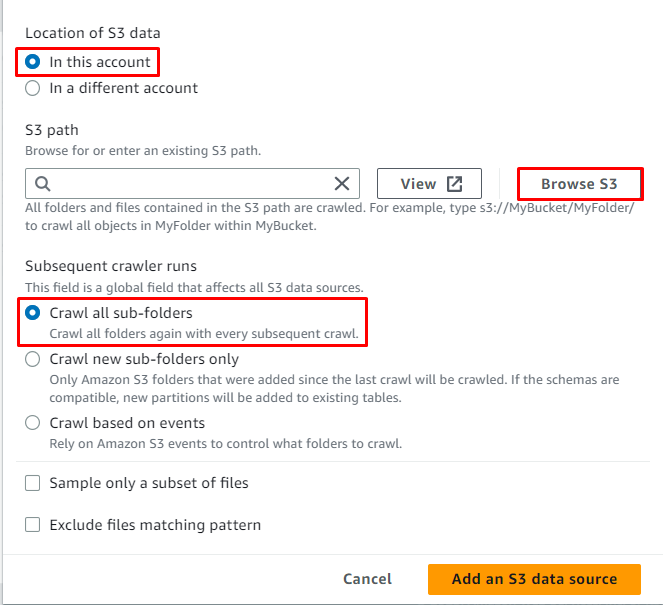
Velg mappen som inneholder dataene, og klikk deretter på ' Velge ”-knapp:

S3-banen er valgt, klikk nå på ' Legg til en S3-datakilde ”-knapp:

Når datakilden er lagt til, klikker du bare på ' Neste ”-knapp:
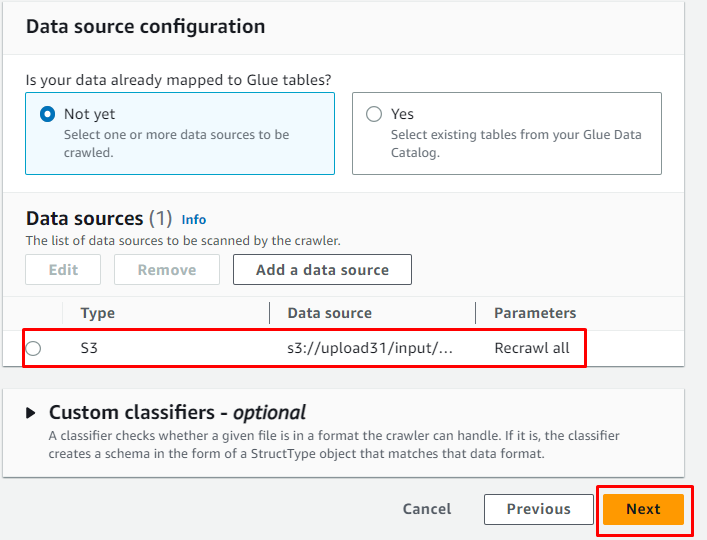
Legg til IAM-rollen og klikk deretter på ' Neste ”-knapp:
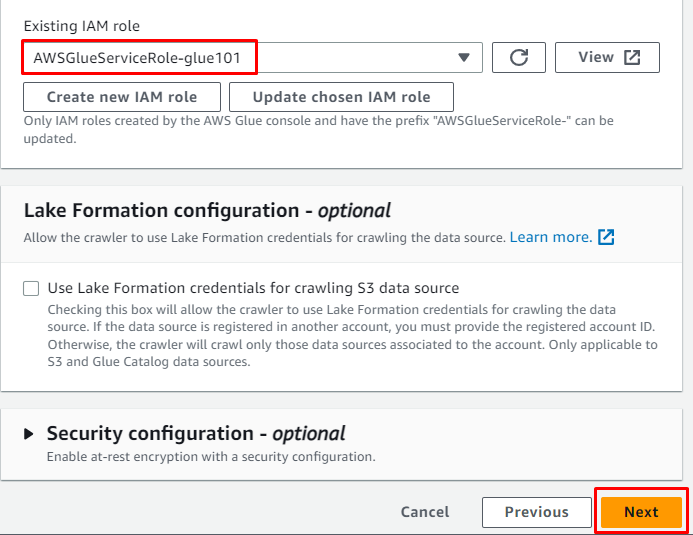
Skriv inn måldatabasen som ble opprettet tidligere, og skriv deretter inn navnet på tabellen:
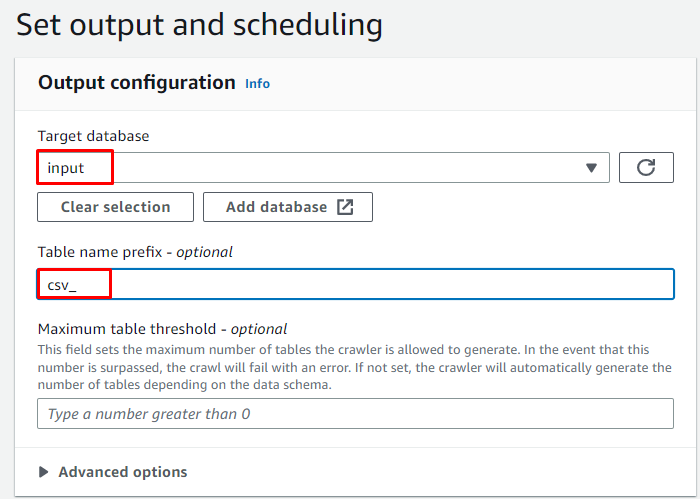
Velg On demand-planen for søkeroboten og klikk på ' Neste ”-knapp:
Se gjennom søkeroboten og klikk på ' Opprett crawler ”-knapp:
Søkeroboten har blitt opprettet, klikk på ' Løpe '-knappen etter å ha valgt den:

Det vil ta noen øyeblikk å kjøre søkeroboten, og den vil hente data og lage en tabell for å lagre dataene:
Gå inn i ' Tabeller ”-side fra Glue-dashbordet:
Velg tabellen ved å klikke på navnet:
Historiedetaljene har blitt vist som inneholder metadataene til de hentede dataene:
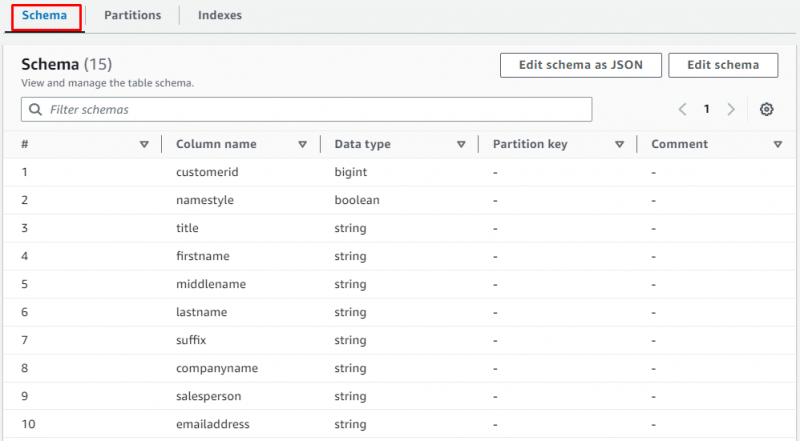
Rull ned på siden og velg delen for å se tabellen som inneholder dataene:
Det handler om å lage en crawler for å hente data fra S3-bøtten.
Konklusjon
For å lage en crawler for å hente data fra S3-bøtten, opprette en database på AWS Glue der de crawlede dataene vil bli lagret. Konfigurer søkeroboten fra Glue-dashbordet ved å oppgi datakilden (S3-bøtte) og måldatabasen. Kjør søkeroboten og hent dataene fra S3-bøtten til databasetabellen, slik denne veiledningen har forklart grundig.