Kjøl (Knowledge Extraction based on Evolutionary Learning) er et Java-basert programvareverktøy som spesialiserer seg på implementering av evolusjonære algoritmer. Siden det er en åpen kildekode, gir den et bredt utvalg av kunnskapsoppdagelsesalgoritmer som kan brukes i eksperimenter som driver datautvinnings- og analysesamfunnet. Det gir et enkelt og brukervennlig grafisk brukergrensesnitt som reduserer den generelle kompleksiteten til dette verktøyet betydelig. De fleste lignende verktøy på markedet krever at brukerne samhandler med dem ved å skrive koden, mens Keel fjerner dette kravet ved å tilby en intuitiv GUI som kan brukes av både nybegynnere og eksperter.
Keel tilbyr et bredt utvalg av forskjellige databaserte intelligensbaserte algoritmer, inkludert klassifisering, regresjon, funksjonsekstraksjon, mønsteranalyse, klynging og mer. Med mainstream-modeller bakt rett inn i selve applikasjonen, er Keel et veldig nyttig verktøy når det gjelder å utføre utforskende dataanalyser på rådatasett. Det enkle dra-og-slipp-grensesnittet sammen med den enkle funksjonalitetsutnyttelsen muliggjør rask og effektiv datautvinningseksperimentering for både utdannings- og forskningsformål. Verktøy som Keel øker i popularitet på grunn av deres forenklede tilnærming til ellers komplekse algoritmiske praksiser.
Installasjon
Det er to hovedmåter vi kan installere på Kjøl på hvilken som helst Linux-maskin. Den første innebærer å gå til Kjøl nettside og laster ned programvaren derfra. Den andre, som vi vil følge i denne installasjonsveiledningen, krever at vi laster ned Keel ved hjelp av wget nedlastingsverktøy tilgjengelig for Linux-brukere.
1. Vi starter med å få wget på vår Linux-maskin.
Kjør følgende kommando for å laste ned wget ved å bruke apt pakkebehandler:
$ sudo apt-get install wget
Du vil se en lignende terminalutgang:
2. Nå som vi har wget verktøyet installert på vår Linux-maskin, bruker vi det til å laste ned Kjøl verktøy.
Dette er link at vi går over til wget.
Kjør følgende kommando i terminalen din:
$ wget http: // sci2s.ugr.es / kjøl / programvare / prototyper / åpen versjon / Programvare- 2018 -04-09.zip
Du bør se en lignende utgang på terminalen din:
Når Keel er ferdig med å laste ned, kan vi fortsette med resten av installasjonen.
3. Vi trekker nå ut den komprimerte filen som vi lastet ned i forrige trinn ved å bruke Linux Unzip-verktøyet.
Kjør følgende kommando:
$ pakke opp Programvare- 2018 -04-09.zip
Du bør se en lignende utgang i terminalen:
4. Naviger inn i Keel-mappen ved å kjøre følgende kommando:
$ cd Programvare- 2018 -04-09 / dokumenter / eksperimenter / KJØL / dist /
5. Kjør følgende kommando for å starte med installasjonen:
$ java -krukke . / GraphInterKeel.jar
Med dette bør Keel være tilgjengelig for deg å bruke på din Linux-maskin.
Brukerhåndboken
Samhandle med Kjøl applikasjonen er veldig enkel og enkel. La oss starte med å importere Iris datasett inn i arbeidsområdet vårt.
Når vi importerer dataene, viser verktøyet oss den generelle klyngingen av datapunktet i datasettet. Den viser oss også de forskjellige klassene som er tilstede i datasettet sammen med den grunnleggende informasjonen som de numeriske områdene som disse datapunktene spenner over og den generelle variansen og gjennomsnittsverdiene den presenterer. Denne informasjonen lar brukerne bedre forstå hvordan de skal fortsette med dataforberedelsen for enhver form for dataanalyseoppgave.
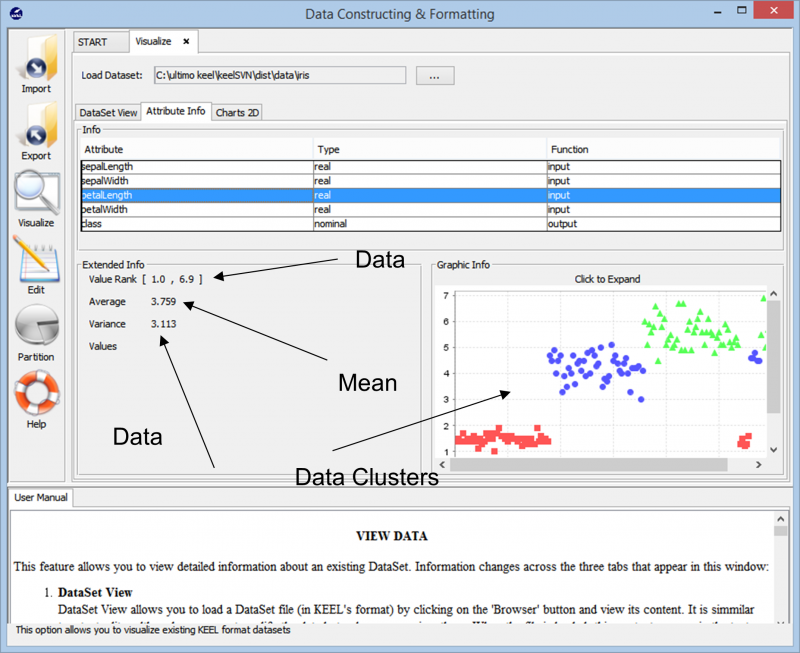
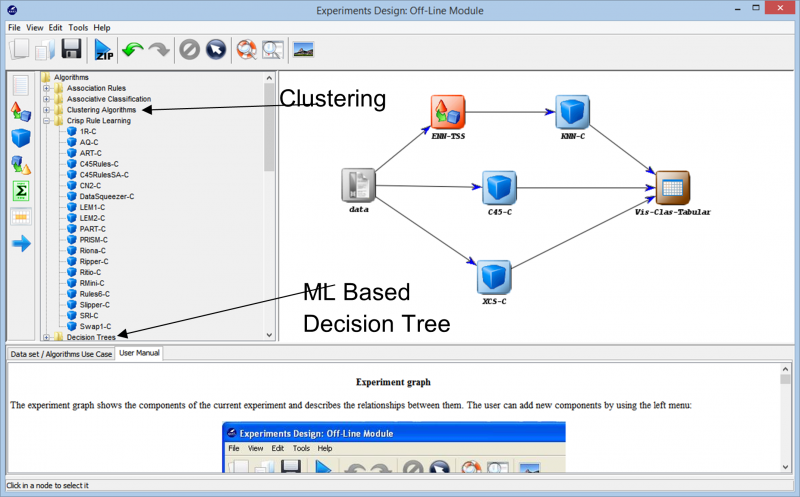
Når vi går videre inn i eksperimentet, kommer vi over de forskjellige teknikkene som kan brukes til å lage eksperimentet vårt på ethvert datasett. De forskjellige læringsalgoritmene som kan brukes på våre data kan sees i bildet nedenfor. Avhengig av typen av datasett og kravene til eksperimentet, kan forskjellige algoritmer eksperimenteres med.
Hvis du for eksempel jobber med umerkede data og må finne likheter mellom de forskjellige datapunktene i datasettet ditt, kan bruk av en klyngealgoritme fra de forskjellige tilgjengelige alternativene hjelpe deg med å forstå datapunktene bedre. Dette hjelper deg til slutt å merke og klassifisere datapunktene slik at eksperimentet kan bygges på ved å bruke mer omfattende overvåket læringsalgoritmer.
Konklusjon
De Kjøl plattform for dataanalyse er en god ressurs for både forsknings- og utdanningsformål. Det er brukervennlig grafisk brukergrensesnitt hjelper brukerne til å bedre forstå kravene til dataene sammen med å gi logiske referanser til nyttige teknikker og algoritmer som ytterligere hjelper brukerne i deres arbeidsflyter. Å ha et bredt spekter av forskjellige algoritmer som faller inn under de forskjellige kategoriene og algoritmiske teknikker lar brukerne eksperimentere med en rekke logiske retninger og sammenligne disse resultatene slik at den mest optimale løsningen på ethvert problem kan nås.
Keels kodefrie dra-og-slipp-tilnærming til datautvinning hjelper selv nybegynnere til å enkelt jobbe med omfattende databaserte intelligensmodeller. Dette gir innsikt i komplekse datasett og utleder som et resultat nyttige slutninger som hjelper til med å løse de virkelige verdensproblemer.