'Comma-Separated Values (CSV) er et av de mest allsidige og brukervennlige dataformatene. Det er et lett dataformat som lar utviklere og applikasjoner overføre og analysere data fra en kilde til en annen.
CSV-data lagrer data i et tabellformat der hver kolonne er atskilt med komma, og en ny post tildeles en ny linje. Dette gjør det til et veldig godt valg for eksport av databaser som SQL-databaser, Cassandra-data og mer.
Det er derfor ingen overraskelse at du vil møte et scenario der du må importere en CSV-fil til databasen din.
Målet med denne opplæringen er å vise deg en rask og enkel metode for å importere en CSV-fil til din Elasticsearch-klynge ved å bruke Kibana-dashbordet.'
La oss hoppe inn.
Krav
Før du dykker inn, sørg for at du har følgende krav:
- En Elasticsearch-klynge med grønn helsestatus.
- Kibana-server koblet til din Elasticsearch-klynge.
- Tilstrekkelige tillatelser til å administrere indekser på klyngen din.
Eksempel på CSV-fil
Som vanlig er det første kravet din CSV-kildefil. Det er greit å sørge for at dataene i CSV-filen er godt formatert og at den ikke inneholder feil.
For illustrasjonsformål vil vi bruke et gratis datasett som inneholder filmer og TV-serier fra Amazon Prime.
Åpne nettleseren din og naviger til ressursen nedenfor:
https://www.kaggle.com/datasets/shivamb/amazon-prime-movies-and-tv-shows
Følg prosedyren for å laste ned datasettet til din lokale maskin. Du kan pakke ut det nedlastede arkivet med kommandoen:
$ pakke opp a~ / Nedlastinger / archive.zip
Importer CSV-fil
Når du har kildefilen klar, kan vi fortsette og diskutere hvordan du importerer den.
Start med å gå over til Kibana-hjemmedashbordet og velge alternativet 'last opp en fil'.
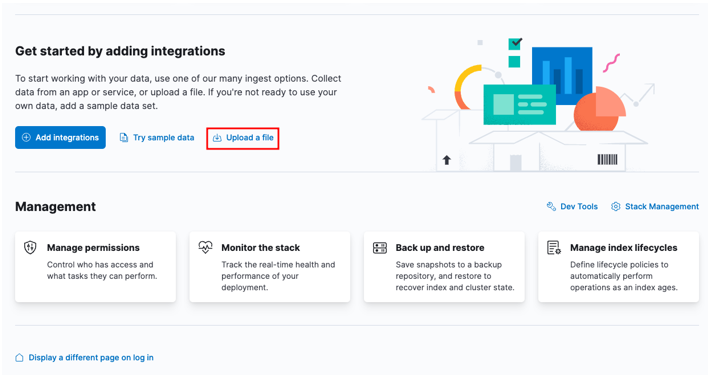
Finn mål-CSV-filen du ønsker å importere i startvinduet.
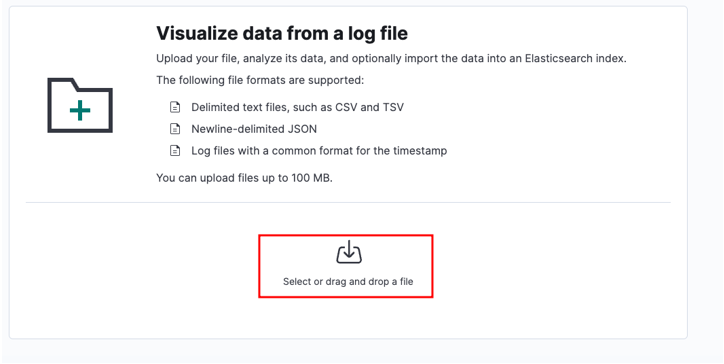
Velg kildefilen din og klikk på last opp.
Tillat at Elasticsearch og Kibana analyserer den opplastede filen. Dette vil analysere CSV-filen og bestemme dataformat, felt, datatyper osv.
MERK: Avhengig av klyngekonfigurasjonen og datastørrelsen, kan denne prosessen ta en stund. Sørg for at masternoden svarer for å unngå tidsavbrudd.
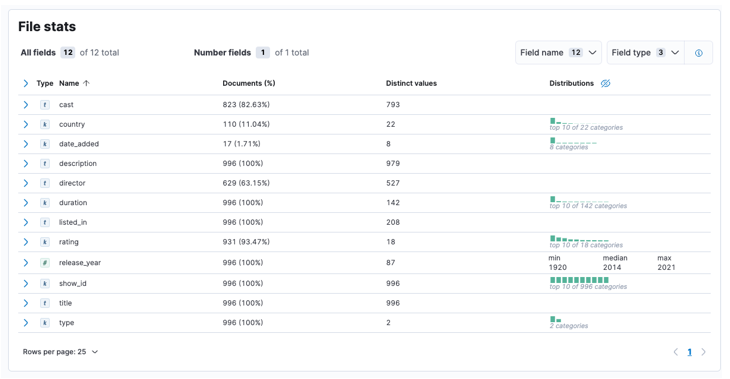
Når prosessen er fullført, bør du få et utvalg av filinnholdet og filstatistikken som analysert av Elastic.
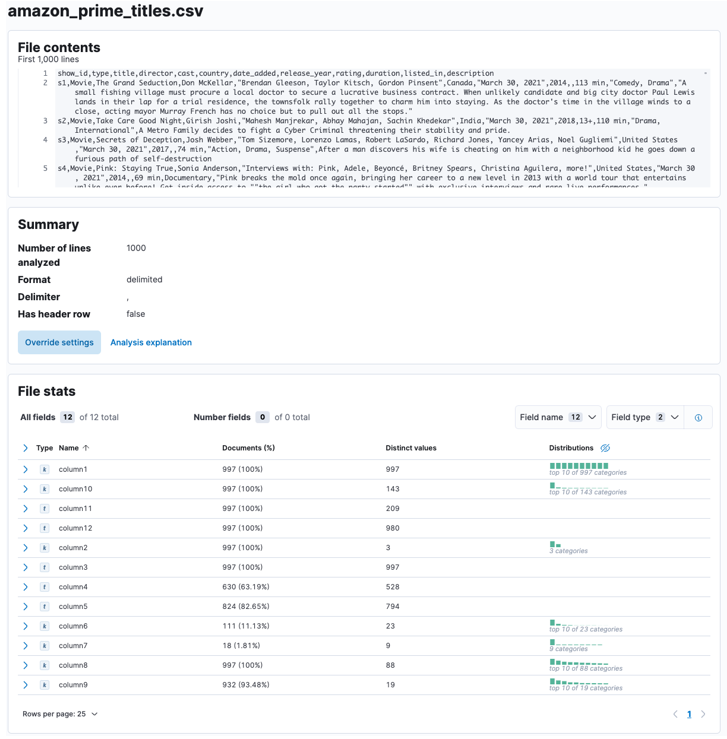
Du kan skreddersy en rekke parametere, for eksempel skilletegn, overskriftsrader osv. For eksempel kan vi tilpasse utdataene ovenfor for å fortelle Elastic at CSV-filen vår inneholder overskriftsfiler.
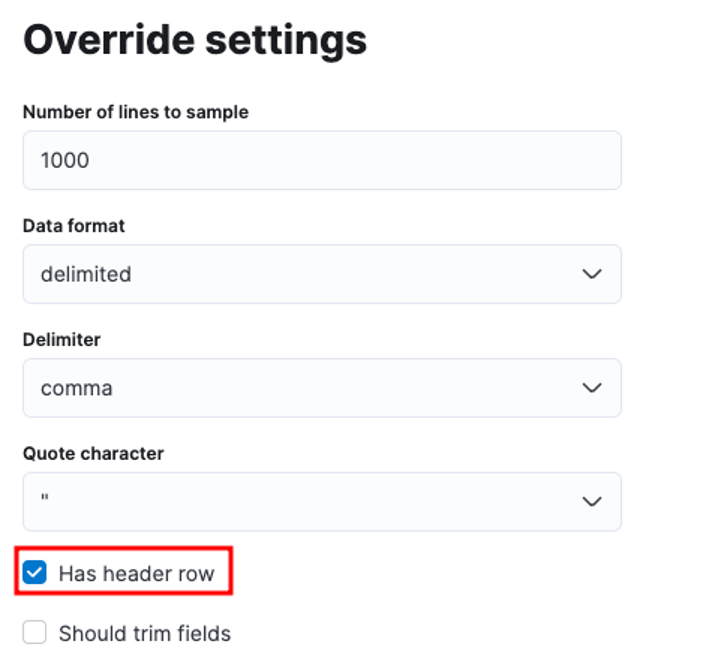
Vi kan deretter klikke på bruk og analysere dataene på nytt. Dette bør formatere dataene i riktig format, inkludert feltene.
Deretter kan vi klikke på import for å fortsette til det importerte dashbordet.
Her må vi lage en indeks der CSV-dataene er lagret. Du kan tildele et hvilket som helst støttet navn til indeksen din.
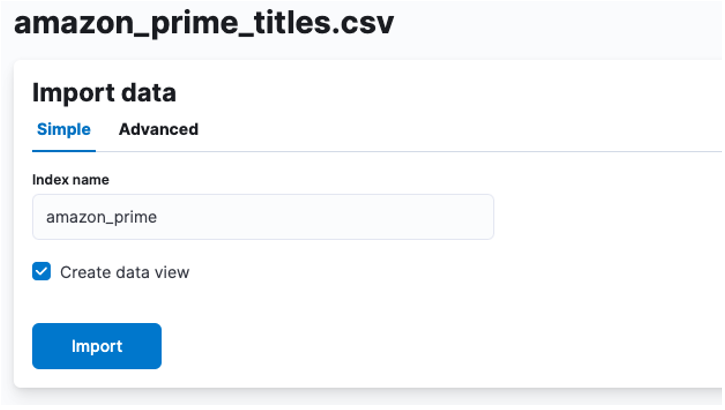
Hvis du ønsker å tilpasse indeksegenskapene dine, slik som antall shards, replikaer, tilordninger, osv. Velg det avanserte alternativet og juster innstillingene dine slik hjertet ditt ønsker.
Til slutt, klikk på import og se på mens Kibana gjør sin 'magi'. Når du er ferdig, kan du få tilgang til indeksen din enten via Elasticsearch API eller bruke Kibana-dashbordet.
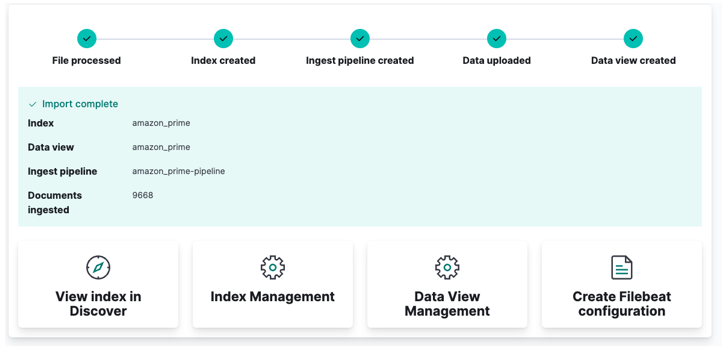
Og du er ferdig!!
Konklusjon
I dette innlegget dekket vi prosessen med å hente og importere CSV-datasettet ditt til Elasticsearch-klyngen ved hjelp av Kibana-dashbordet.
Takk for at du leste og god koding!!