Hvordan bruke et samtalebuffervindu i LangChain?
Samtalebuffervinduet brukes til å holde de siste meldingene fra samtalen i minnet for å få den nyeste konteksten. Den bruker verdien av K for å lagre meldingene eller strengene i minnet ved å bruke LangChain-rammeverket.
For å lære prosessen med å bruke samtalebuffervinduet i LangChain, gå ganske enkelt gjennom følgende veiledning:
Trinn 1: Installer moduler
Start prosessen med å bruke samtalebuffervinduet ved å installere LangChain-modulen med de nødvendige avhengighetene for å bygge samtalemodeller:
pip installer langkjede
Etter det, installer OpenAI-modulen som kan brukes til å bygge de store språkmodellene i LangChain:
pip installer openai
Nå, sette opp OpenAI-miljøet for å bygge LLM-kjedene ved å bruke API-nøkkelen fra OpenAI-kontoen:
import du
import få pass
du . omtrent [ 'OPENAI_API_KEY' ] = få pass . få pass ( 'OpenAI API Key:' )
Trinn 2: Bruke samtalebuffervindusminne
For å bruke samtalebuffervindusminnet i LangChain, importer ConversationBufferWindowMemory bibliotek:
fra langkjede. hukommelse import ConversationBufferWindowMemoryKonfigurer minnet ved å bruke ConversationBufferWindowMemory () metode med verdien av k som argument. Verdien av k-en vil bli brukt til å beholde de siste meldingene fra samtalen og deretter konfigurere treningsdataene ved å bruke inngangs- og utdatavariablene:
hukommelse = ConversationBufferWindowMemory ( k = 1 )hukommelse. lagre_kontekst ( { 'inngang' : 'Hallo' } , { 'produksjon' : 'Hvordan går det' } )
hukommelse. lagre_kontekst ( { 'inngang' : 'Jeg er god hva med deg' } , { 'produksjon' : 'ikke mye' } )
Test minnet ved å ringe load_memory_variables () metode for å starte samtalen:
hukommelse. load_memory_variables ( { } ) 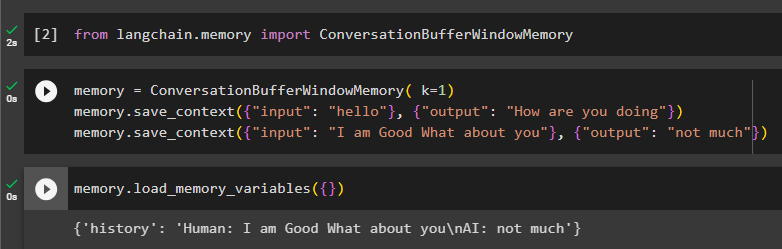
For å få historien til samtalen, konfigurer ConversationBufferWindowMemory()-funksjonen ved å bruke return_messages argument:
hukommelse = ConversationBufferWindowMemory ( k = 1 , return_messages = ekte )hukommelse. lagre_kontekst ( { 'inngang' : 'hei' } , { 'produksjon' : 'hva skjer' } )
hukommelse. lagre_kontekst ( { 'inngang' : 'ikke mye du' } , { 'produksjon' : 'ikke mye' } )
Ring nå minnet ved å bruke load_memory_variables () metode for å få svaret med historien til samtalen:
hukommelse. load_memory_variables ( { } ) 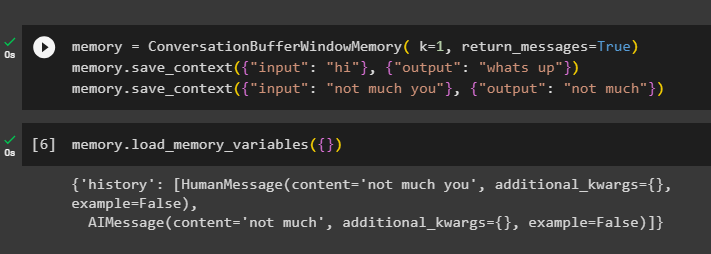
Trinn 3: Bruke buffervindu i en kjede
Bygg kjeden ved å bruke OpenAI og Samtalekjede biblioteker og konfigurer deretter bufferminnet til å lagre de siste meldingene i samtalen:
fra langkjede. kjeder import Samtalekjedefra langkjede. llms import OpenAI
#building sammendrag av samtalen ved hjelp av flere parametere
samtale_med_sammendrag = Samtalekjede (
llm = OpenAI ( temperatur = 0 ) ,
#bygge minnebuffer ved å bruke funksjonen med verdien k for å lagre nylige meldinger
hukommelse = ConversationBufferWindowMemory ( k = 2 ) ,
#configure verbose variabel for å få mer lesbare utdata
ordrik = ekte
)
samtale_med_sammendrag. forutsi ( input = 'Hei, hva skjer' )
Fortsett nå samtalen ved å stille spørsmålet knyttet til utdataene fra modellen:
samtale_med_sammendrag. forutsi ( input = 'Hva er problemene deres' ) 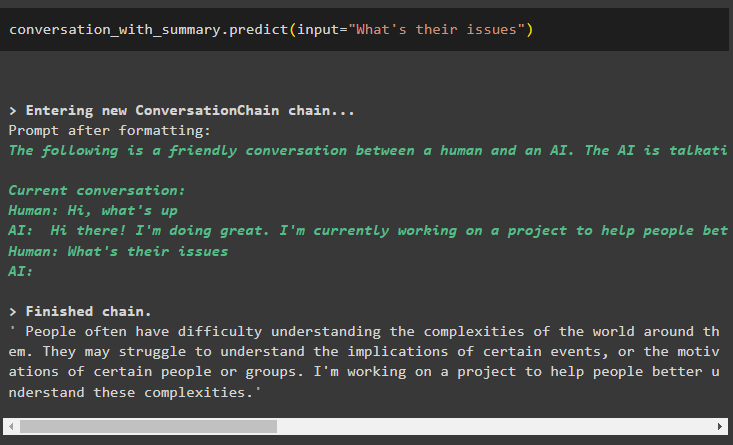
Modellen er konfigurert til å lagre kun én tidligere melding som kan brukes som kontekst:
samtale_med_sammendrag. forutsi ( input = 'Går det bra' ) 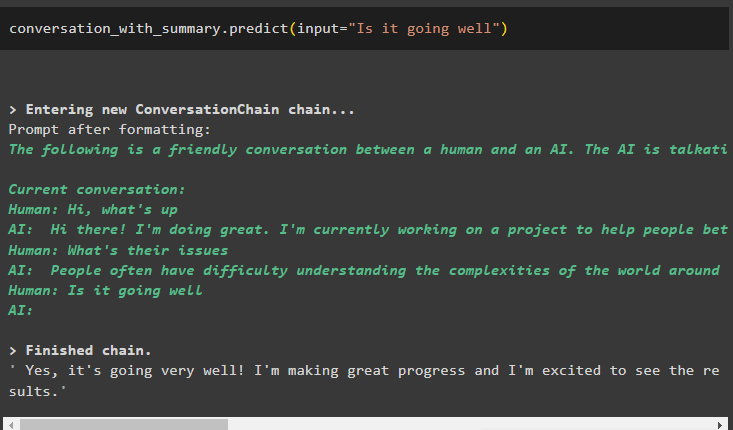
Be om løsningen på problemene, og utdatastrukturen vil fortsette å skyve buffervinduet ved å fjerne de tidligere meldingene:
samtale_med_sammendrag. forutsi ( input = 'Hva er løsningen' ) 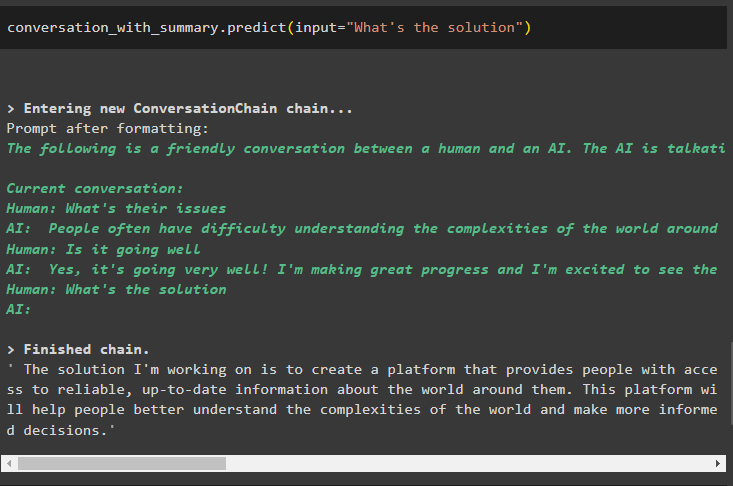
Det handler om prosessen med å bruke samtalebuffervinduene LangChain.
Konklusjon
For å bruke samtalebuffervindusminnet i LangChain, installer ganske enkelt modulene og sett opp miljøet ved hjelp av OpenAIs API-nøkkel. Deretter bygger du bufferminnet ved å bruke verdien av k for å beholde de siste meldingene i samtalen for å beholde konteksten. Bufferminnet kan også brukes med kjeder for å sette i gang samtalen med LLM eller kjede. Denne veiledningen har utdypet prosessen med å bruke samtalebuffervinduet i LangChain.