Denne veiledningen vil illustrere prosessen med å bruke enhetsminne i LangChain.
Hvordan bruke enhetsminne i LangChain?
Entiteten brukes til å holde nøkkelfakta lagret i minnet for å trekke ut når det blir spurt av mennesket som bruker spørringene/forespørslene. For å lære prosessen med å bruke enhetsminnet i LangChain, besøk ganske enkelt følgende guide:
Trinn 1: Installer moduler
Installer først LangChain-modulen ved å bruke pip-kommandoen for å få dens avhengigheter:
pip installer langkjede
Etter det, installer OpenAI-modulen for å få bibliotekene for å bygge LLM-er og chat-modeller:
pip installer openai
Sett opp OpenAI-miljøet ved å bruke API-nøkkelen som kan trekkes ut fra OpenAI-kontoen:
import du
import få pass
du . omtrent [ 'OPENAI_API_KEY' ] = få pass . få pass ( 'OpenAI API Key:' )
Trinn 2: Bruke enhetsminne
For å bruke enhetsminnet, importer de nødvendige bibliotekene for å bygge LLM ved å bruke OpenAI()-metoden:
fra langkjede. llms import OpenAIfra langkjede. hukommelse import ConversationEntityMemory
llm = OpenAI ( temperatur = 0 )
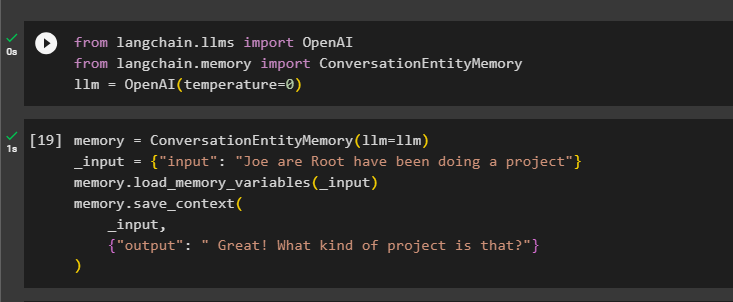
Etter det, definer hukommelse variabel ved å bruke ConversationEntityMemory()-metoden for å trene modellen ved å bruke inngangs- og utdatavariablene:
hukommelse = ConversationEntityMemory ( llm = llm )_inngang = { 'inngang' : 'Joe are Root har gjort et prosjekt' }
hukommelse. load_memory_variables ( _inngang )
hukommelse. lagre_kontekst (
_inngang ,
{ 'produksjon' : 'Flott! Hva slags prosjekt er det?' }
)
Test nå minnet ved å bruke spørringen/ledeteksten i input variabel ved å kalle load_memory_variables()-metoden:
hukommelse. load_memory_variables ( { 'inngang' : 'hvem er root' } ) 
Gi nå litt mer informasjon slik at modellen kan legge til noen flere enheter i minnet:
hukommelse = ConversationEntityMemory ( llm = llm , return_messages = ekte )_inngang = { 'inngang' : 'Joe are Root har gjort et prosjekt' }
hukommelse. load_memory_variables ( _inngang )
hukommelse. lagre_kontekst (
_inngang ,
{ 'produksjon' : 'Flott! Hva slags prosjekt er det' }
)
Kjør følgende kode for å få utdata ved å bruke enhetene som er lagret i minnet. Det er mulig gjennom input som inneholder ledeteksten:
hukommelse. load_memory_variables ( { 'inngang' : 'hvem er Joe' } ) 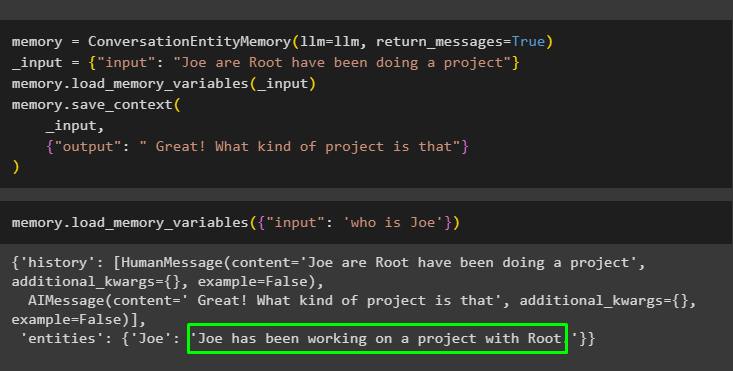
Trinn 3: Bruke enhetsminne i en kjede
For å bruke enhetsminnet etter å ha bygget en kjede, importerer du ganske enkelt de nødvendige bibliotekene ved å bruke følgende kodeblokk:
fra langkjede. kjeder import Samtalekjedefra langkjede. hukommelse import ConversationEntityMemory
fra langkjede. hukommelse . ledetekst import ENTITY_MEMORY_CONVERSATION_MAL
fra pydantisk import BaseModel
fra skrive import Liste , Dict , Noen
Bygg samtalemodellen ved å bruke ConversationChain()-metoden ved å bruke argumentene som llm:
samtale = Samtalekjede (llm = llm ,
ordrik = ekte ,
ledetekst = ENTITY_MEMORY_CONVERSATION_MAL ,
hukommelse = ConversationEntityMemory ( llm = llm )
)
Kall samtale.predict()-metoden med inndata initialisert med ledeteksten eller spørringen:
samtale. forutsi ( input = 'Joe are Root har gjort et prosjekt' ) 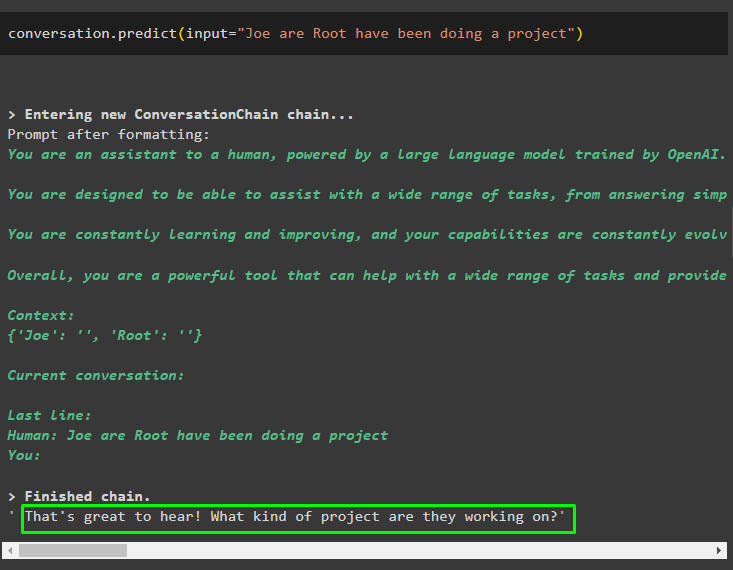
Få nå den separate utgangen for hver enhet som beskriver informasjonen om den:
samtale. hukommelse . entity_store . butikk 
Bruk utdataene fra modellen for å gi input, slik at modellen kan lagre mer informasjon om disse enhetene:
samtale. forutsi ( input = 'De prøver å legge til mer komplekse minnestrukturer til Langchain' ) 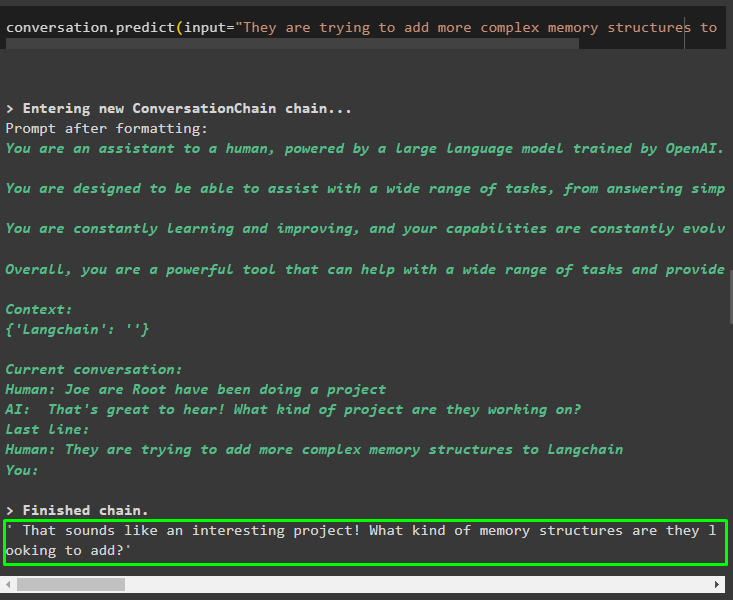
Etter å ha gitt informasjonen som blir lagret i minnet, still spørsmålet for å trekke ut den spesifikke informasjonen om enheter:
samtale. forutsi ( input = 'Hva vet du om Joe og Root' ) 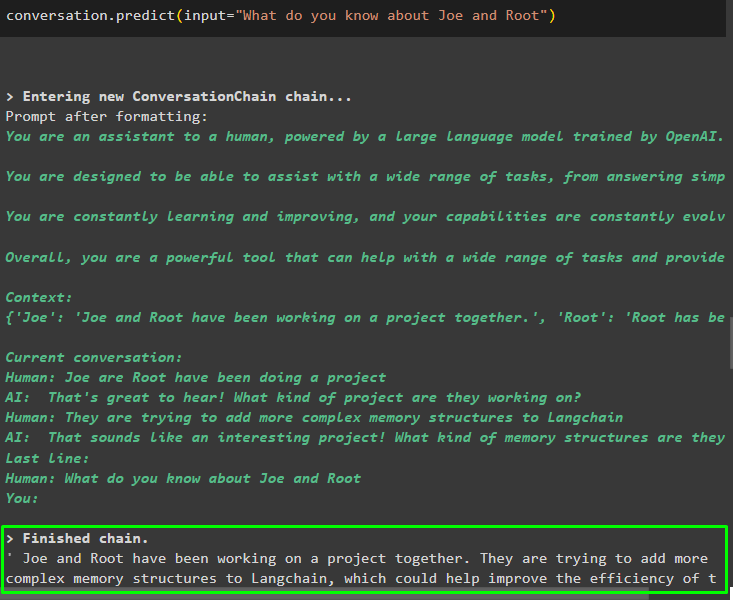
Trinn 4: Testing av minnelageret
Brukeren kan inspisere minnelagrene direkte for å få informasjonen lagret i dem ved å bruke følgende kode:
fra skrive ut import skrive utskrive ut ( samtale. hukommelse . entity_store . butikk )
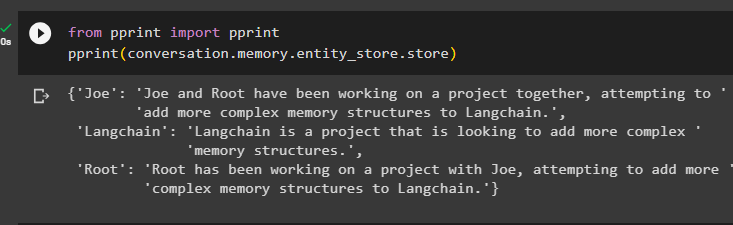
Gi mer informasjon som skal lagres i minnet ettersom mer informasjon gir mer nøyaktige resultater:
samtale. forutsi ( input = 'Root har grunnlagt en virksomhet kalt HJRS' ) 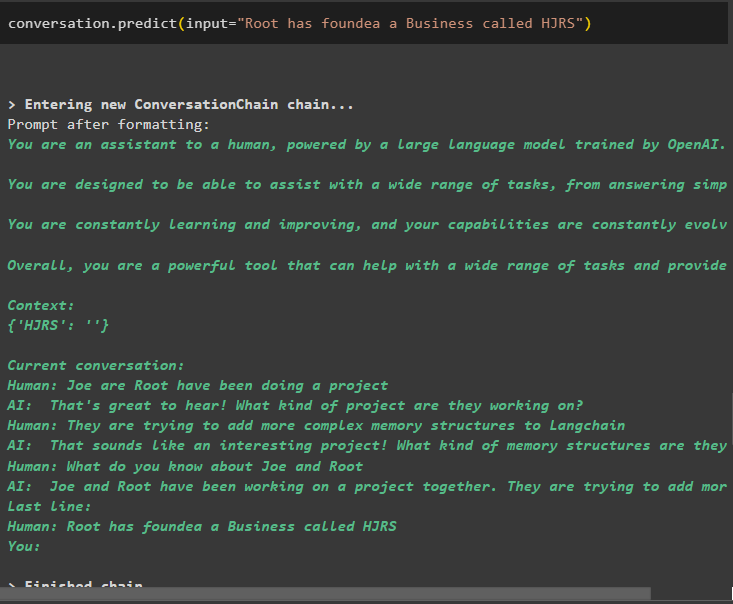
Trekk ut informasjon fra minnelageret etter å ha lagt til mer informasjon om enhetene:
fra skrive ut import skrive utskrive ut ( samtale. hukommelse . entity_store . butikk )
Minnet har informasjon om flere enheter som HJRS, Joe, LangChain og Root:
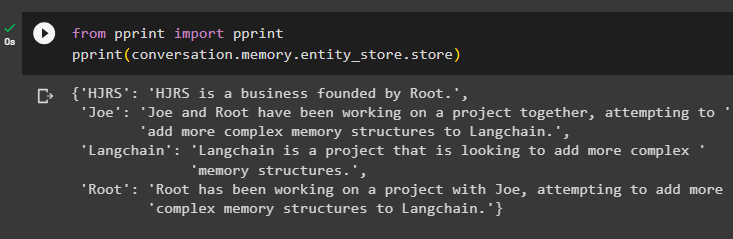
Trekk nå ut informasjon om en spesifikk enhet ved å bruke spørringen eller ledeteksten som er definert i inngangsvariabelen:
samtale. forutsi ( input = 'Hva vet du om Root' ) 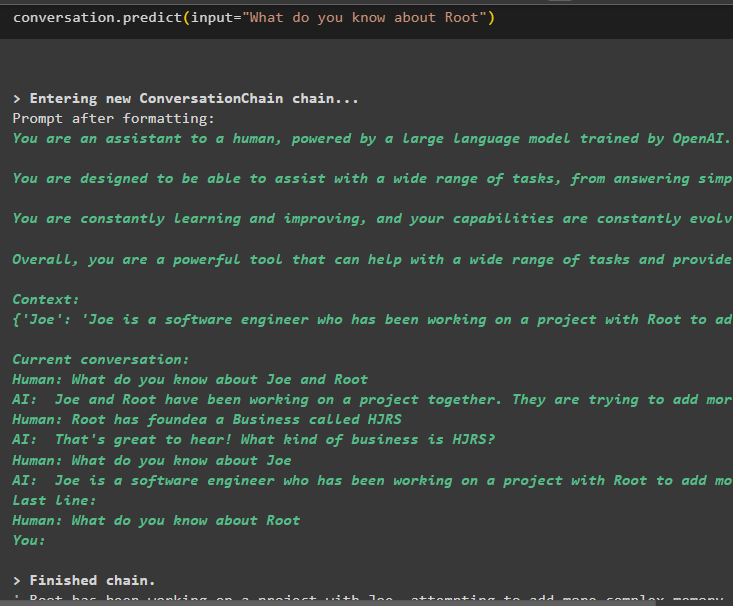
Det handler om å bruke enhetsminnet ved å bruke LangChain-rammeverket.
Konklusjon
For å bruke enhetsminnet i LangChain, installer ganske enkelt de nødvendige modulene for å importere biblioteker som kreves for å bygge modeller etter å ha satt opp OpenAI-miljøet. Deretter bygger du LLM-modellen og lagrer enheter i minnet ved å gi informasjon om enhetene. Brukeren kan også trekke ut informasjon ved å bruke disse enhetene og bygge disse minnene i kjedene med omrørt informasjon om enheter. Dette innlegget har utdypet prosessen med å bruke enhetsminnet i LangChain.