- Bildeoversettelse
- Bilde rotasjon
- Bilde aritmetikk
- Bildet snur
- Bildebeskjæring
- Endre størrelse på bildet
Nå vil vi forklare alle de ovennevnte bildebehandlingsemnene i detalj.
1. Bildeoversettelse
Bildeoversettelse er en bildebehandlingsmetode som hjelper oss å flytte bildet langs x- og y-aksene. Vi kan flytte bildet opp, ned, høyre, venstre eller en hvilken som helst kombinasjon.
Vi kan definere oversettelsesmatrisen med symbolet M, og vi kan representere den i matematisk form, som vist nedenfor:
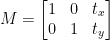
Vi kan forstå konseptet med oversettelsesbildet gjennom dette programmet.
Python-kode: Vi beholder følgende programnavn som translate.py .
# importer nødvendige pakkerimport nusset som f.eks.
import argparse
import imutil
import cv2
# vi implementerer argumentparseren
ap_obj = argparse. ArgumentParser ( )
ap_obj. add_argument ( '-k' , '--bilde' , nødvendig = ekte ,
hjelp = 'plassering av bildefilen' )
args = hvem sin ( ap_obj. parse_args ( ) )
# last inn bildet og vis det på skjermen
bilde = cv2. imread ( args [ 'bilde' ] )
cv2. imshow ( 'Original_image' , bilde )
# Oversettelsen av bildet er en NumPy-matrise som er gitt nedenfor:
# [[1, 0, shiftX], [0, 1, shiftY]]
# Vi skal bruke NumPy-matrisen ovenfor for å flytte bildene langs
# x-akse og y-akse retninger. For dette må vi ganske enkelt sende pikselverdiene.
# I dette programmet vil vi flytte bildet 30 piksler til høyre
# og 70 piksler mot bunnen.
translation_mat = f.eks. flyte32 ( [ [ 1 , 0 , 30 ] , [ 0 , 1 , 70 ] ] )
image_translation = cv2. warpAffine ( bilde , translation_mat ,
( bilde. form [ 1 ] , bilde. form [ 0 ] ) )
cv2. imshow ( 'Bildeoversettelse ned og til høyre' , image_translation )
# nå skal vi bruke NumPy-matrisen ovenfor for å flytte bildene langs
# x-akse (venstre) og y-akse (opp) retninger.
# Her skal vi flytte bildene 50 piksler til venstre
# og 90 piksler oppover.
translation_mat = f.eks. flyte32 ( [ [ 1 , 0 , - femti ] , [ 0 , 1 , - 90 ] ] )
image_translation = cv2. warpAffine ( bilde , translation_mat ,
( bilde. form [ 1 ] , bilde. form [ 0 ] ) )
cv2. imshow ( 'Bildeoversettelse opp og venstre' , image_translation )
cv2. waitKey ( 0 )
Linje 1 til 5: Vi importerer alle nødvendige pakker for dette programmet, som OpenCV, argparser og NumPy. Vær oppmerksom på at det er et annet bibliotek som er imutils. Dette er ikke en pakke med OpenCV. Dette er bare et bibliotek som enkelt vil vise den samme bildebehandlingen.
Bibliotekets imutils vil ikke inkluderes automatisk når vi installerer OpenCV. Så for å installere imutils, må vi bruke følgende metode:
pip installer imutils
Linje 8 til 15: Vi laget vår agrparser og lastet inn bildet vårt.
Linje 24 til 25: Denne programdelen er der oversettelsen skjer. Oversettelsesmatrisen forteller oss hvor mange piksler bildet skal flyttes opp eller ned eller til venstre eller høyre. Fordi OpenCV krever at matriseverdien er i en flytende kommamatrise, tar oversettelsesmatrisen verdier i flyttallsmatriser.
Oversettelsesmatrisens første rad ser slik ut:
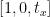
Denne raden i matrisen er for x-aksen. Verdien av t x vil avgjøre om bildet skal flyttes til venstre eller høyre side. Hvis vi passerer en negativ verdi, betyr det at bildet vil bli forskjøvet til venstre side, og hvis verdien er positiv, betyr det at bildet vil bli forskjøvet til høyre side.
Vi vil nå definere den andre raden i matrisen som følger:
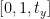
Denne raden i matrisen er for y-aksen. Verdien av t Y vil avgjøre om bildet skal flyttes til opp- eller nedsiden. Hvis vi passerer en negativ verdi, betyr det at bildet vil bli forskjøvet til oppsiden, og hvis verdien er positiv, betyr det at bildet vil bli forskjøvet til nedsiden.
I forrige program på linje 24 definerer vi t x = 30 og t Y = 70. Så vi flytter bildet 30 piksler mot høyre side og 70 piksler nedover.
Men hovedbildeoversettelsesprosessen foregår på linje 25, hvor vi definerer oversettelsesmatrisen cv2.warpAffine . I denne funksjonen sender vi tre parametere: den første parameteren er bildet, den andre parameteren er oversettelsesmatrisen, og den tredje parameteren er bildedimensjonen.
Linje 27: Linje 27 vil vise resultatet i utgangen.
Nå skal vi implementere en annen oversettelsesmatrise for venstre og oppside. For dette må vi definere verdiene i negative.
Linje 33 til 34: I forrige program på linje 33 definerer vi t x = -50 og t Y = -90. Så vi flytter bildet 50 piksler mot venstre side og 90 piksler opp. Men hovedbildeoversettelsesprosessen foregår på linje 34, hvor vi definerer oversettelsesmatrisen cv2.warpAffine .
Linje 36 : Linjen 36 vil vise resultatet som vist i utgangen.
For å kjøre den forrige koden, må vi gi banen til bildet som gitt nedenfor.
Produksjon: python translate.py –image squirrel.jpg
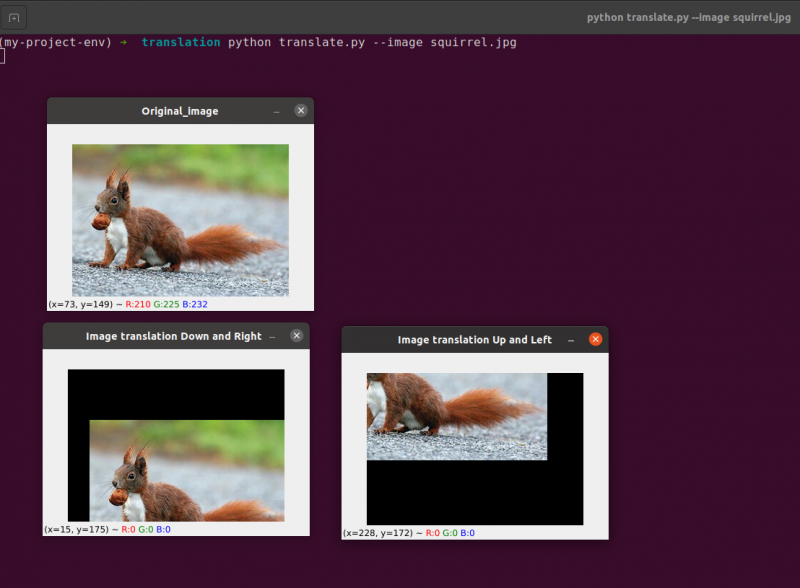
Nå vil vi implementere det samme bildeoversettelsesprogrammet ved å bruke imutil bibliotek. Dette biblioteket er veldig enkelt å bruke for bildebehandling. I dette biblioteket trenger vi ikke tenke på cv2.warpAffine fordi dette biblioteket tar seg av dette. Så la oss implementere dette bildeoversettelsesprogrammet ved å bruke imutils-biblioteket.
Python-kode: Vi beholder følgende programnavn som translate_imutils.py .
# importer de nødvendige pakkeneimport nusset som f.eks.
import argparse
import imutil
import cv2
# Denne funksjonen implementerer bildeoversettelsen og
# returnerer det oversatte bildet til anropsfunksjonen.
def oversette ( bilde , x , Y ) :
translation_matrise = f.eks. flyte32 ( [ [ 1 , 0 , x ] , [ 0 , 1 , Y ] ] )
image_translation = cv2. warpAffine ( bilde , translation_matrise ,
( bilde. form [ 1 ] , bilde. form [ 0 ] ) )
komme tilbake image_translation
# konstruer argumentparseren og analyser argumentene
ap = argparse. ArgumentParser ( )
ap. add_argument ( '-Jeg' , '--bilde' , nødvendig = ekte , hjelp = 'Veien til bildet' )
args = hvem sin ( ap. parse_args ( ) )
# last inn bildet og vis det på skjermen
bilde = cv2. imread ( args [ 'bilde' ] )
cv2. imshow ( 'Original_image' , bilde )
image_translation = imutil. oversette ( bilde , 10 , 70 )
cv2. imshow ( 'Bildeoversettelse til høyre og ulemper' ,
image_translation )
cv2. waitKey ( 0 )
Linje 9 til 13: Denne delen av programmet er der oversettelsen skjer. Oversettelsesmatrisen informerer oss med hvor mange piksler bildet vil bli flyttet opp eller ned eller til venstre eller høyre.
Disse linjene er allerede forklart, men nå skal vi bygge en funksjon kalt translate () og sende tre forskjellige parametere inn i den. Selve bildet fungerer som den første parameteren. Translasjonsmatrisens x- og y-verdier tilsvarer den andre og tredje parameteren.
Merk : Det er ikke nødvendig å definere denne oversettelsesfunksjonen inne i programmet fordi den allerede er inkludert i imutils bibliotekpakken. Jeg har brukt det i programmet for å få en enkel forklaring. Vi kan kalle denne funksjonen direkte med imutils, som vist i linje 24.
Linje 24: Det forrige programmet vil vise at på linje 24 definerer vi tx = 10 og ty = 70. Så vi flytter bildet 10 piksler mot høyre side og 70 piksler nedover.
I dette programmet bryr vi oss ikke om noen cv2.warpAffine-funksjoner fordi de allerede er inne i imutils-bibliotekpakken.
For å kjøre den forrige koden, må vi gi banen til bildet, som gitt nedenfor:
Produksjon:
python imutils. py --bilde ekorn. jpg 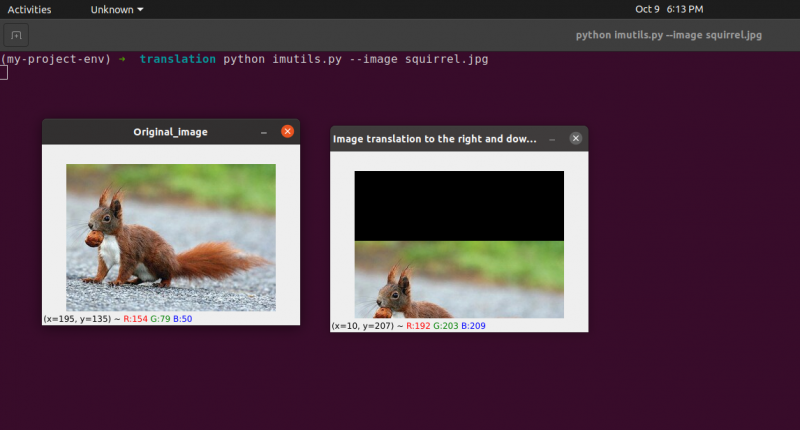
2. Bilderotasjon
Vi gikk gjennom hvordan du kan oversette (dvs. flytte) et bilde opp, ned, til venstre og høyre i forrige leksjon (eller en hvilken som helst kombinasjon). Deretter vil vi diskutere rotasjon når det gjelder bildebehandling.
Et bilde roteres med en vinkel, theta, i en prosess kjent som rotasjon. Vinkelen som vi roterer bildet med vil bli representert av theta. I tillegg vil jeg senere gi den roterende bekvemmelighetsfunksjonen for å gjøre roterende bilder enklere.
I likhet med translasjon, og kanskje ikke overraskende, rotasjon med en vinkel, bestemmes theta ved å bygge en matrise M i følgende format:
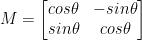
Denne matrisen kan rotere en vektor theta grader (mot klokken) rundt opprinnelsen gitt (x, y)-kartesisk plan. Vanligvis, i dette scenariet, vil opprinnelsen være midten av bildet, men i virkeligheten kan vi utpeke et hvilket som helst tilfeldig (x, y) punkt som vårt rotasjonssenter.
Det roterte bildet R lages deretter fra det originale bildet I ved å bruke enkel matrisemultiplikasjon: R = IM
OpenCV, på den annen side, tilbyr i tillegg kapasitet til å (1) skalere (dvs. endre størrelse) på et bilde og (2) tilby et vilkårlig rotasjonssenter for å utføre rotasjonen rundt.
Vår modifiserte rotasjonsmatrise M er vist nedenfor:
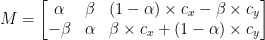
La oss starte med å åpne og generere en ny fil kalt rotate.py :
# importerer de nødvendige pakkeneimport nusset som f.eks.
import argparse
import imutil
import cv2
# lage argumentparser-objektet og parsing-argumentet
apobj = argparse. ArgumentParser ( )
apobj. add_argument ( '-k' , '--bilde' , nødvendig = ekte , hjelp = 'bildebane' )
argumenter = hvem sin ( apobj. parse_args ( ) )
bilde = cv2. imread ( argumenter [ 'bilde' ] )
cv2. imshow ( 'Original_image' , bilde )
# Beregn bildets sentrum ved å bruke bildets dimensjoner.
( høyde , bredde ) = bilde. form [ : 2 ]
( centerX , sentrumY ) = ( bredde / 2 , høyde / 2 )
# Nå, ved å bruke cv2, vil vi rotere bildet 55 grader til
# bestem rotasjonsmatrisen ved å bruke getRotationMatrix2D()
rotasjonsmatrise = cv2. getRotationMatrix2D ( ( centerX , sentrumY ) , 55 , 1.0 )
rotert bilde = cv2. warpAffine ( bilde , rotasjonsmatrise , ( bredde , høyde ) )
cv2. imshow ( 'Roterte bildet 55 grader' , rotert bilde )
cv2. waitKey ( 0 )
# Bildet vil nå bli rotert med -85 grader.
rotasjonsmatrise = cv2. getRotationMatrix2D ( ( centerX , sentrumY ) , - 85 , 1.0 )
rotert bilde = cv2. warpAffine ( bilde , rotasjonsmatrise , ( bredde , høyde ) )
cv2. imshow ( 'Roterte bildet med -85 grader' , rotert bilde )
cv2. waitKey ( 0 )
Linje 1 til 5: Vi importerer alle nødvendige pakker for dette programmet, som OpenCV, argparser og NumPy. Vær oppmerksom på at det er et annet bibliotek som er imutils. Dette er ikke en pakke med OpenCV. Dette er bare et bibliotek som vil bli brukt til å vise den samme bildebehandlingen enkelt.
Bibliotekets imutils vil ikke inkluderes automatisk når vi installerer OpenCV. OpenCV installerer imutils. Vi må bruke følgende metode:
pip install imutils
Linje 8 til 14: Vi laget vår agrparser og lastet inn bildet vårt. I denne argparseren bruker vi bare ett bildeargument, som vil fortelle oss banen til bildet som vi vil bruke i dette programmet for å demonstrere rotasjonen.
Når vi roterer et bilde, må vi definere rotasjonens dreiepunkt. Mesteparten av tiden vil du rotere et bilde rundt midten, men OpenCV lar deg velge hvilket som helst tilfeldig punkt i stedet. La oss ganske enkelt rotere bildet rundt midten.
Linje 17 til 18 ta henholdsvis bildets bredde og høyde, og del deretter hver dimensjon med to for å etablere bildets sentrum.
Vi konstruerer en matrise for å rotere et bilde på samme måte som vi definerte en matrise for å oversette et bilde. Vi ringer bare cv2.getRotationMatrix2D funksjon på linje 22 i stedet for å lage matrisen manuelt ved å bruke NumPy (som kan være litt tungvint).
De cv2.getRotationMatrix2D funksjonen krever tre parametere. Den første inngangen er ønsket rotasjonsvinkel (i dette tilfellet midten av bildet). Theta brukes så til å spesifisere hvor mange (mot klokken) grader vi skal rotere bildet. Her vil vi rotere bildet 45 grader. Det siste alternativet er relatert til bildets størrelse.
Uavhengig av det faktum at vi ennå ikke har diskutert skalering av et bilde, kan du oppgi et flyttall her med 1,0 som indikerer at bildet skal brukes i de opprinnelige proporsjonene. Men hvis du skrev inn en verdi på 2.0, ville bildet dobles i størrelse. Et tall på 0,5 reduserer bildets størrelse slik.
Linje 22 til 23: Etter å ha mottatt vår rotasjonsmatrise M fra cv2.getRotationMatrix2D funksjon, roterer vi bildet vårt ved å bruke cv2.warpAffine teknikk på linje 23. Funksjonens første inngang er bildet som vi ønsker å rotere. Bredden og høyden på utgangsbildet vårt defineres da, sammen med rotasjonsmatrisen vår M. På linje 23 roteres bildet 55 grader.
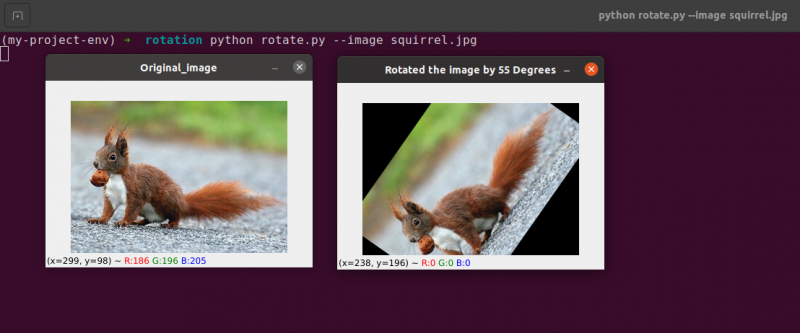
Du kan legge merke til at bildet vårt har blitt rotert.
Linje 28 til 30 utgjør den andre rotasjonen. Linje 22–23 i koden er identiske, bortsett fra at vi denne gangen roterer med -85 grader i motsetning til 55.
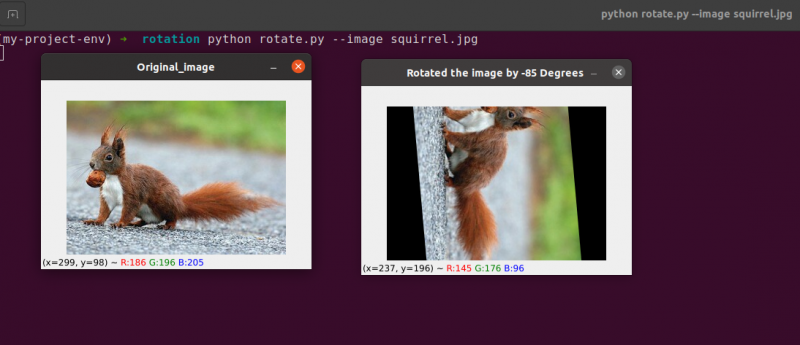
Vi har ganske enkelt rotert et bilde rundt midten til dette punktet. Hva om vi ønsket å rotere bildet rundt et tilfeldig punkt?
La oss starte med å åpne og generere en ny fil kalt rotate.py:
# importerer de nødvendige pakkeneimport nusset som f.eks.
import argparse
import imutil
import cv2
# lage argumentparser-objektet og parsing-argumentet
ap_obj = argparse. ArgumentParser ( )
ap_obj. add_argument ( '-k' , '--bilde' , nødvendig = ekte , hjelp = 'bildebane' )
argument = hvem sin ( ap_obj. parse_args ( ) )
# last inn bildet og vis det på skjermen
bilde = cv2. imread ( argument [ 'bilde' ] )
cv2. imshow ( 'Original_image' , bilde )
# Beregn bildets sentrum ved å bruke bildets dimensjoner.
( høyde , bredde ) = bilde. form [ : 2 ]
( centerX , sentrumY ) = ( bredde / 2 , høyde / 2 )
# Nå, ved å bruke cv2, vil vi rotere bildet 55 grader til
# bestem rotasjonsmatrisen ved å bruke getRotationMatrix2D()
rotasjonsmatrise = cv2. getRotationMatrix2D ( ( centerX , sentrumY ) , 55 , 1.0 )
rotert bilde = cv2. warpAffine ( bilde , rotasjonsmatrise , ( bredde , høyde ) )
cv2. imshow ( 'Roterte bildet 55 grader' , rotert bilde )
cv2. waitKey ( 0 )
# Bildet vil nå bli rotert med -85 grader.
rotasjonsmatrise = cv2. getRotationMatrix2D ( ( centerX , sentrumY ) , - 85 , 1.0 )
rotert bilde = cv2. warpAffine ( bilde , rotasjonsmatrise , ( bredde , høyde ) )
cv2. imshow ( 'Roterte bildet med -85 grader' , rotert bilde )
cv2. waitKey ( 0 )
# bilderotasjon fra et vilkårlig punkt, ikke fra midten
rotasjonsmatrise = cv2. getRotationMatrix2D ( ( centerX - 40 , centerY - 40 ) , 55 , 1.0 )
rotert bilde = cv2. warpAffine ( bilde , rotasjonsmatrise , ( bredde , høyde ) )
cv2. imshow ( 'Bilderotering fra vilkårlige punkter' , rotert bilde )
cv2. waitKey ( 0 )
Linje 34 til 35: Nå burde denne koden virke ganske vanlig for å rotere et objekt. For å rotere bildet rundt et punkt 40 piksler til venstre og 40 piksler over midten, instruerer vi cv2.getRotationMatrix2D funksjon for å ta hensyn til den første parameteren.
Bildet som produseres når vi bruker denne rotasjonen er vist nedenfor:
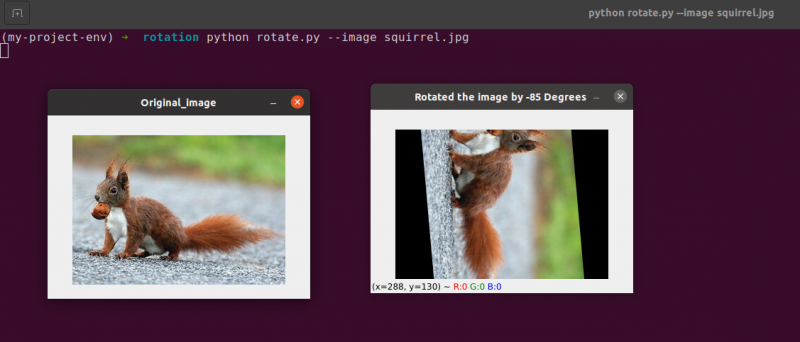
Vi kan tydelig se at sentrum av rotasjonen nå er (x, y)-koordinaten, som er 40 piksler til venstre og 40 piksler over det beregnede midten av bildet.
3. Bilderegning
Faktisk er bildearitmetikk bare matrisetillegg med noen få ekstra begrensninger på datatyper som vi skal dekke senere.
La oss ta et øyeblikk for å gå gjennom noen ganske grunnleggende for lineær algebra.
Vurder å kombinere de to neste matrisene:
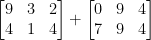
Hvilket resultat ville matrisetilsetningen gi? Det enkle svaret er summen av matriseoppføringene, element for element:
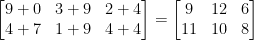
Enkelt nok, ikke sant?
Vi forstår alle de grunnleggende operasjonene for addisjon og subtraksjon på dette tidspunktet. Vi må imidlertid være oppmerksomme på begrensningene som pålegges av vårt fargerom og datatype når vi jobber med bilder.
Piksler i RGB-bilder faller for eksempel mellom [0, 255]. Hva skjer hvis vi prøver å legge til 10 til en piksel med en intensitet på 250 mens vi ser på den?
Vi ville komme til en verdi på 260 hvis vi brukte standard aritmetiske prinsipper. 260 er ikke en gyldig verdi, da RGB-bilder er representert som 8-biters usignerte heltall.
Så hva bør skje? Bør vi kjøre en sjekk for å sikre at ingen piksler er utenfor området [0, 255], og beskjære hver piksel til å ha en verdi mellom 0 og 255?
Eller 'vikler vi oss rundt' og utfører en moduloperasjon? I samsvar med modulreglene vil å legge til 10 til 255 bare resultere i en verdi på 9.
Hvordan skal addisjoner og subtraksjoner til bilder utenfor området [0, 255] håndteres?
Sannheten er at det ikke er noen rett eller gal teknikk; alt avhenger av hvordan du jobber med pikslene dine og hva du håper å oppnå.
Men husk at det er forskjeller mellom addisjon i OpenCV og addisjon i NumPy. Modulus aritmetikk og 'wrap around' vil bli utført av NumPy. I motsetning til dette vil OpenCV utføre klipping og sørge for at pikselverdier aldri forlater området [0, 255].
La oss begynne med å lage en ny fil kalt aritmetic.py og åpne den:
# python arithmetic.py --image squirrel.jpg# importerer de nødvendige pakkene
import nusset som f.eks.
import argparse
import imutil
import cv2
# lage argumentparser-objektet og parsing-argumentet
apObj = argparse. ArgumentParser ( )
apObj. add_argument ( '-k' , '--bilde' , nødvendig = ekte , hjelp = 'bildebane' )
argumenter = hvem sin ( apObj. parse_args ( ) )
bilde = cv2. imread ( argumenter [ 'bilde' ] )
cv2. imshow ( 'Original_image' , bilde )
'''
Verdiene til våre piksler vil være i området [0, 255]
siden bilder er NumPy-matriser, som er lagret som usignerte 8-biters heltall.
Når du bruker funksjoner som cv2.add og cv2.subtract, vil verdier bli klippet
til dette området selv om de legges til eller trekkes fra utenfor
[0, 255] område. Her er en illustrasjon:
'''
skrive ut ( 'maks 255: {}' . format ( str ( cv2. legge til ( f.eks. uint8 ( [ 201 ] ) ,
f.eks. uint8 ( [ 100 ] ) ) ) ) )
skrive ut ( 'minimum 0: {}' . format ( str ( cv2. trekke fra ( f.eks. uint8 ( [ 60 ] ) ,
f.eks. uint8 ( [ 100 ] ) ) ) ) )
'''
Når du utfører aritmetiske operasjoner med disse matrisene ved å bruke NumPy,
verdien vil omsluttes i stedet for å bli klippet til
[0, 255]område. Når du bruker bilder, er det viktig å beholde dette
i tankene.
'''
skrive ut ( 'wrap around: {}' . format ( str ( f.eks. uint8 ( [ 201 ] ) + f.eks. uint8 ( [ 100 ] ) ) ) )
skrive ut ( 'wrap around: {}' . format ( str ( f.eks. uint8 ( [ 60 ] ) - f.eks. uint8 ( [ 100 ] ) ) ) )
'''
La oss multiplisere lysstyrken til hver piksel i bildet vårt med 101.
For å gjøre dette genererer vi en NumPy-matrise i samme størrelse som matrisen vår,
fylt med enere, og gang det med 101 for å produsere en matrise fylt
med 101s. Til slutt slår vi sammen de to bildene.
Du vil merke at bildet nå er 'lysere'.
'''
Matrise = f.eks. seg ( bilde. form , dtype = 'uint8' ) * 101
image_added = cv2. legge til ( bilde , Matrise )
cv2. imshow ( 'Lagt til bilderesultat' , image_added )
#På lignende måte kan vi gjøre bildet mørkere ved å ta
# 60 unna alle pikslene.
Matrise = f.eks. seg ( bilde. form , dtype = 'uint8' ) * 60
image_subtracted = cv2. trekke fra ( bilde , Matrise )
cv2. imshow ( 'Stratrukket bilderesultat' , image_subtracted )
cv2. waitKey ( 0 )
Linje 1 til 16 vil bli brukt til å utføre vår normale prosess, som innebærer å importere pakkene våre, konfigurere argumentparseren og laste inn bildet vårt.
Husker du hvordan jeg tidligere diskuterte skillet mellom OpenCV og NumPy tillegg? Nå som vi har dekket det grundig, la oss se på en spesifikk sak for å sikre at vi forstår den.
To 8-biters usignerte heltalls NumPy-matriser er definert på linje 26 . En verdi på 201 er det eneste elementet i den første matrisen. Selv om bare ett medlem er i den andre matrisen, har den en verdi på 100. Verdiene legges deretter til ved hjelp av OpenCVs cv2.add-funksjon.
Hva forventer du at resultatet blir?
I samsvar med konvensjonelle aritmetiske prinsipper bør svaret være 301. Men husk at vi har å gjøre med 8-bits usignerte heltall, som bare kan være i området [0, 255]. Fordi vi bruker cv2.add-metoden, håndterer OpenCV klipping og sikrer at tillegget kun gir et maksimalt resultat på 255.
Den første linjen i listen nedenfor viser resultatet av å kjøre denne koden:
aritmetikk. pymaksimalt 255 : [ [ 255 ] ]
Summen ga faktisk et tall på 255.
Følger det, linje 26 bruker cv2.subtract for å utføre en subtraksjon. Nok en gang definerer vi to 8-bits usignerte heltalls NumPy-matriser med et enkelt element i hver. Verdien til den første matrisen er 60, mens verdien til den andre matrisen er 100.
Aritmetikken vår tilsier at subtraksjonen skal resultere i en verdi på -40, men OpenCV håndterer klippingen for oss en gang til. Vi oppdager at verdien har blitt trimmet til 0. Resultatet vårt nedenfor viser dette:
aritmetikk. pyminimum av 0 : [ [ 0 ] ]
Bruk cv2, trekk 100 fra 60 trekk fra, og produsere verdien 0.
Men hva skjer hvis vi bruker NumPy i stedet for OpenCV for å utføre beregningene?
Linje 38 og 39 løse dette problemet.
Først defineres to 8-bits usignerte heltalls NumPy-matriser med et enkelt element hver. Verdien av den første matrisen er 201, mens verdien til den andre matrisen er 100. Addisjonen vår ville bli trimmet, og en verdi på 255 ville bli returnert hvis vi brukte cv2.add-funksjonen.
NumPy, på den annen side, 'smyger seg rundt' og utfører modulo-aritmetikk i stedet for å klippe. NumPy går rundt til null når en verdi på 255 er nådd, og fortsetter deretter å telle opp til 100 trinn er nådd. Dette bekreftes av den første utdatalinjen, som er vist nedenfor:
aritmetikk. pyvikle rundt: [ Fire fem ]
Deretter defineres ytterligere to NumPy-matriser, en med en verdi på 50 og den andre med 100. Denne subtraksjonen vil bli trimmet av cv2.subtract-metoden for å returnere et resultat på 0. Men vi er klar over at i stedet for å klippe, kjører NumPy modulo aritmetikk. I stedet går modulo-prosedyrene rundt og begynner å telle bakover fra 255 når 0 er nådd under subtraksjonen. Vi kan se dette fra følgende utgang:
aritmetikk. pyvikle rundt: [ 207 ]
Nok en gang demonstrerer terminalutgangen forskjellen mellom å klippe og pakke rundt:
Det er avgjørende å ha ønsket resultat i bakhodet når du utfører heltallsregning. Vil du at noen verdier utenfor området [0, 255] skal klippes? Bruk OpenCVs innebygde bilderegningsteknikker etter det.
Vil du at verdier skal omsluttes hvis de er utenfor området for [0, 255] og aritmetiske moduloperasjoner? NumPy-matrisene blir så ganske enkelt lagt til og trukket fra som vanlig.
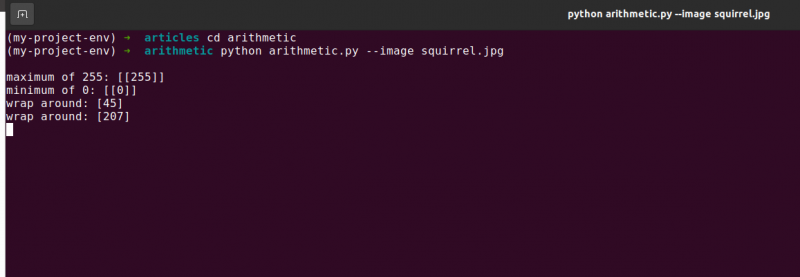
Linje 48 definerer en endimensjonal NumPy-matrise med samme dimensjoner som bildet vårt. Nok en gang sikrer vi at datatypen vår er 8-biters usignerte heltall. Vi multipliserer bare matrisen vår med ensifrede verdier med 101 for å fylle den med verdier på 101 i stedet for 1. Til slutt bruker vi funksjonen cv2.add for å legge til matrisen vår på 100 til det originale bildet. Dette øker intensiteten til hver piksel med 101 samtidig som det sikrer at alle verdier som forsøker å overskride 255, klippes til området [0, 255].
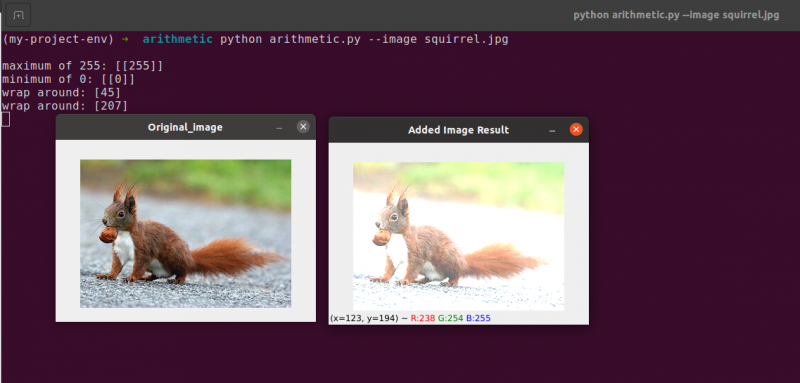
Se hvordan bildet er merkbart lysere og ser mer 'utvasket ut' enn originalen. Dette er fordi vi driver piksler mot lysere farger ved å øke pikselintensiteten med 101.
For å trekke fra 60 fra hver pikselintensitet i bildet, etablerer vi først en andre NumPy-matrise på linje 54 som er fylt med 60-tallet.
Resultatene av denne subtraksjonen er avbildet i følgende bilde:
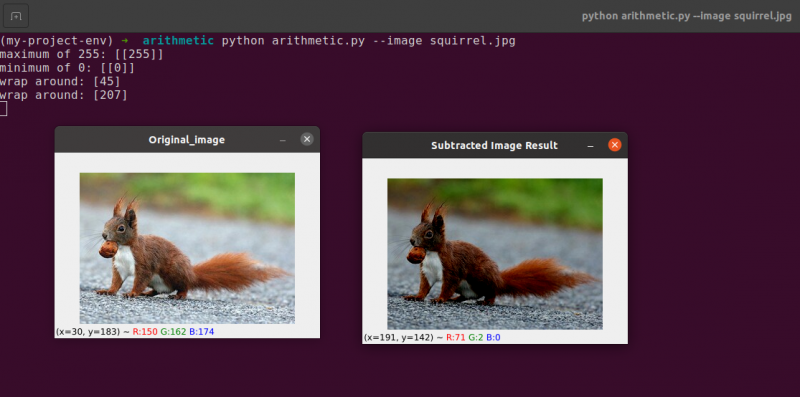
Gjenstandene rundt oss ser betydelig mørkere ut enn de gjorde tidligere. Dette er fordi ved å trekke fra 60 fra hver piksel, flytter vi pikslene i RGB-fargerommet inn i de mørkere områdene.
4. Bildeflipping
I likhet med rotasjon, er det å vende et bilde over x- eller y-aksen et annet alternativ som tilbys av OpenCV. Selv om flippoperasjoner ikke brukes så ofte, er det utrolig nyttig å vite dem av ulike grunner du kanskje ikke umiddelbart ser.
Vi utvikler en maskinlæringsklassifisering for et lite oppstartsselskap som søker å identifisere ansikter i bilder. For at systemet vårt skal 'lære' hva et ansikt er, trenger vi et slags datasett med eksempelansikter. Dessverre har selskapet bare gitt oss et lite datasett på 40 ansikter, og vi klarer ikke å samle inn mer informasjon.
Hva gjør vi da?
Siden et ansikt forblir et ansikt enten det er speilvendt eller ikke, kan vi snu hvert bilde av et ansikt horisontalt og bruke de speilvendte versjonene som ekstra treningsdata.
Dette eksemplet kan virke dumt og kunstig, men det er det ikke. Flipping er en bevisst strategi som brukes av sterke dyplæringsalgoritmer for å produsere mer data under treningsfasen.
Det er klart fra forrige at bildebehandlingsmetodene du lærer i denne modulen fungerer som grunnlaget for større datasynssystemer.
Mål:
Bruker cv2.flip funksjon, vil du lære hvordan du snur et bilde både horisontalt og vertikalt i denne økten.
Flipping er den neste bildemanipulasjonen vi skal studere. Et bildes x- og y-akser kan snus eller begge deler. Før vi dykker ned i kodingen, er det best å først se på resultatene av en bildevending. Se et bilde som har blitt snudd horisontalt i følgende bilde:
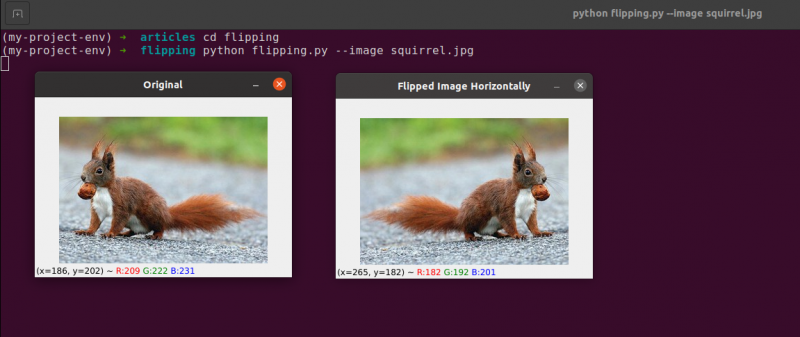
Legg merke til hvordan originalbildet vårt er til venstre og hvordan bildet har blitt horisontalt speilvendt til høyre.
La oss begynne med å lage en ny fil kalt flipping.py .
Du har sett et eksempel på en bildevending, så la oss undersøke koden:
# python flipping.py --image quirrel.jpg# importerer de nødvendige pakkene
import argparse
import cv2
# lage objektet til argumentparser og analyser argumentet
apObj = argparse. ArgumentParser ( )
apObj. add_argument ( '-Jeg' , '--bilde' , nødvendig = ekte , hjelp = 'bildebane' )
argument = hvem sin ( apObj. parse_args ( ) )
bilde = cv2. imread ( argument [ 'bilde' ] )
cv2. imshow ( 'Opprinnelig' , bilde )
# vend bildet horisontalt
imageflipped = cv2. snu ( bilde , 1 )
cv2. imshow ( 'Vendt bilde horisontalt' , imageflipped )
# vend bildet vertikalt
imageflipped = cv2. snu ( bilde , 0 )
cv2. imshow ( 'Vendt bilde vertikalt' , imageflipped )
# bilde vend langs begge aksene
imageflipped = cv2. snu ( bilde , - 1 )
cv2. imshow ( 'Snudd horisontalt og vertikalt' , imageflipped )
cv2. waitKey ( 0 )
Trinnene vi tar for å importere pakkene våre, analysere inngangene våre og laste inn bildet fra disken, håndteres i l ines 1 til 12 .
Ved å aktivere cv2.flip-funksjonen Linje 15 , er det enkelt å snu et bilde horisontalt. Bildet vi prøver å snu og en spesifikk kode eller flagg som spesifiserer hvordan bildet skal snus er de to argumentene som trengs for cv2.flip-metoden.
En flip-kodeverdi på 1 betyr at vi vil rotere bildet rundt y-aksen for å snu det horisontalt ( Linje 15 ). Hvis vi spesifiserer en flip-kode på 0, ønsker vi å rotere bildet om x-aksen ( Linje 19 ). En negativ flippkode ( Linje 23 ) roterer bildet på begge akser.
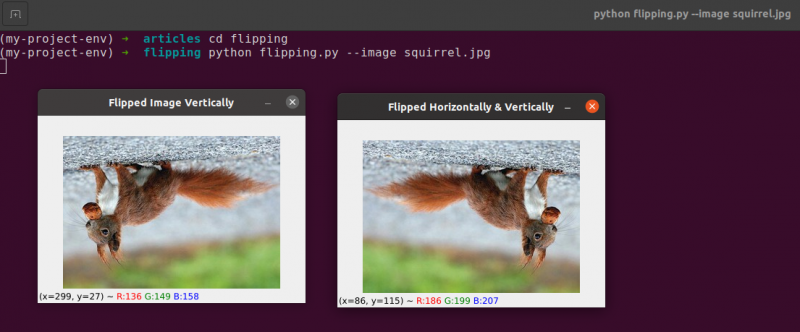
Et av de enkleste eksemplene i dette emnet er å snu et bilde, noe som er grunnleggende.
Deretter vil vi diskutere beskjæring av bilder og bruke NumPy array skiver for å trekke ut spesifikke bildedeler.
5. Bildebeskjæring
Beskjæring, som navnet tilsier, er prosessen med å velge og fjerne interesseregionen (eller ganske enkelt ROI), som er området av bildet som interesserer oss.
Ansiktet må beskjæres fra et bilde for et ansiktsgjenkjenningsprogram. I tillegg, hvis vi skulle lage et Python-skript for å finne hunder i bilder, vil vi kanskje beskjære hunden ut av bildet når vi finner den.
Mål: Vårt hovedmål er å bli kjent med og på en enkel måte å bruke NumPy array slicing for å beskjære områder fra et bilde.
Beskjæring : Når vi beskjærer et bilde, er målet vårt å eliminere de ytre elementene som ikke interesserer oss. Prosessen med å velge vår ROI blir ofte referert til som å velge vår interesseregion.
Opprett en ny fil kalt crop.py , åpne den og legg til følgende kode:
# python crop.py# importerer de nødvendige pakkene
import cv2
# bilde laster og vises på skjermen
bilde = cv2. imread ( 'ekorn.jpg' )
skrive ut ( bilde. form )
cv2. imshow ( 'Opprinnelig' , bilde )
# NumPy array skiver brukes til raskt å trimme et bilde
# vi skal beskjære ekornansiktet fra bildet
ekorn = bilde [ 35 : 90 , 35 : 100 ]
cv2. imshow ( 'ekornansikt' , ekorn )
cv2. waitKey ( 0 )
# Og nå, her skal vi beskjære hele kroppen
# av ekornet
ekornkropp = bilde [ 35 : 148 , 23 : 143 ]
cv2. imshow ( 'Ekornkropp' , ekornkropp )
cv2. waitKey ( 0 )
Vi viser beskjæring i Python og OpenCV ved å bruke et bilde som vi laster inn fra disk på Linje 5 og 6 .

Originalt bilde som vi skal beskjære
Ved å bruke bare grunnleggende beskjæringsteknikker, tar vi sikte på å skille ekornansiktet og ekornkroppen fra området rundt.
Vi vil bruke vår forkunnskap om bildet og manuelt levere NumPy-matrisen hvor kroppen og ansiktet finnes. Under normale forhold vil vi vanligvis bruke maskinlæring og datasynsalgoritmer for å gjenkjenne ansiktet og kroppen i bildet. Men la oss holde ting enkelt for tiden og unngå å bruke noen deteksjonsmodeller.
Vi kan identifisere ansiktet i bildet med bare én kodelinje. Linje 13 , For å trekke ut en rektangeldel av bildet, starter ved (35, 35), gir vi NumPy array skiver (90, 100). Det kan virke forvirrende at vi mater avlingen med indeksene i høyde-første og bredde-sekund rekkefølge som vi gjør, men husk at OpenCV lagrer bilder som NumPy-matriser. Som et resultat må vi oppgi verdiene for y-aksen før x-aksen.
NumPy krever følgende fire indekser for å utføre beskjæringen vår:
Start y: Y-koordinaten i begynnelsen. For dette tilfellet begynner vi på y=35.
Slutt y: Y-koordinaten på slutten. Avlingen vår stopper når y = 90.
Start x: Skivens begynnelse x-koordinat. Beskjæringen påbegynnes ved x=35.
Slutt x: Skivens ende x-aksekoordinat. Ved x=100 er skiven vår ferdig.
På samme måte beskjærer vi områdene (23, 35) og (143, 148) fra originalbildet for å trekke ut hele kroppen fra bildet på Linje 19 .
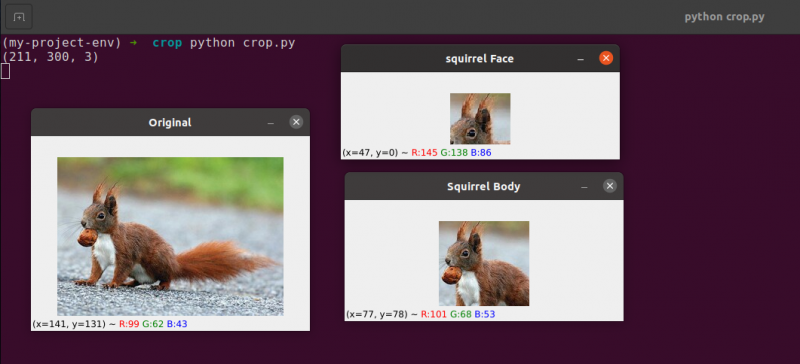
Du kan observere at bildet er beskåret for kun å vise frem kroppen og ansiktet.
6. Endre størrelse på bildet
Prosessen med å øke eller redusere et bildes bredde og høyde er kjent som skalering eller ganske enkelt endre størrelse. Sideforholdet, som er forholdet mellom et bildes bredde og høyden, bør vurderes når du endrer størrelse på et bilde. Forsømmelse av sideforholdet kan føre til at bilder som har blitt skalert som ser komprimerte og forvrengte ut:
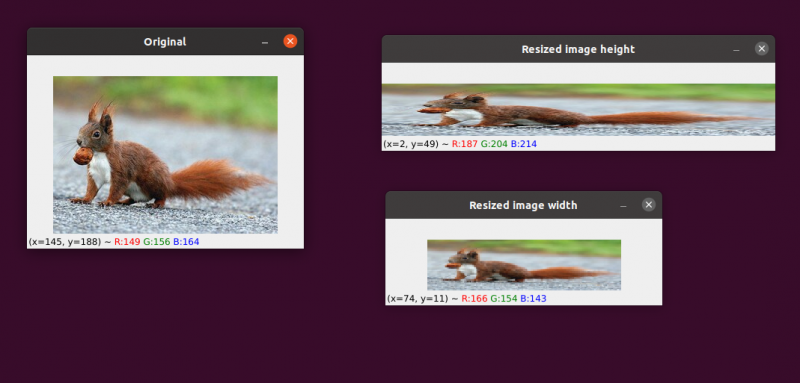
Vårt første bilde er til venstre. Til høyre ser du to bilder som har blitt skalert uten å opprettholde sideforholdet, noe som forvrenger forholdet mellom bildets bredde og høyden. Når du endrer størrelsen på bildene dine, bør du generelt vurdere sideforholdet.
Interpolasjonsteknikken som brukes av algoritmen vår for å endre størrelsen må også ta hensyn til formålet med interpolasjonsfunksjonen for å bruke disse nabolagene av piksler til å enten øke eller redusere størrelsen på bildet.
Generelt er det langt mer effektivt å krympe størrelsen på bildet. Dette er fordi å fjerne piksler fra et bilde er alt interpolasjonsfunksjonen trenger å gjøre. På den annen side ville interpolasjonsmetoden trenge å 'fylle ut hullene' mellom piksler som ikke tidligere fantes hvis bildestørrelsen skulle økes.
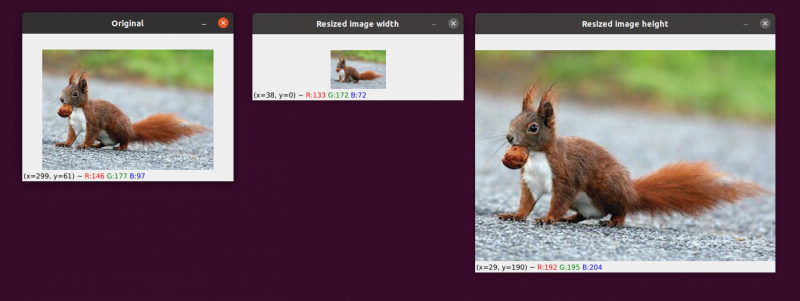
Vi har originalbildet vårt til venstre. Bildet er redusert til halvparten av sin opprinnelige størrelse i midten, men bortsett fra det har det ikke vært noe tap av bildets 'kvalitet'. Likevel har bildets størrelse blitt betydelig forbedret til høyre. Det ser nå ut som 'sprengt' og 'pikselert'.
Som jeg tidligere sa, vil du vanligvis redusere størrelsen på et bilde i stedet for å øke det. Ved å redusere bildestørrelsen analyserer vi færre piksler og må håndtere mindre 'støy', noe som gjør bildebehandlingsalgoritmer raskere og mer presise.
Translasjon og rotasjon er de to bildetransformasjonene som er adressert så langt. Vi skal nå undersøke hvordan du endrer størrelsen på et bilde.
Ikke overraskende vil vi endre størrelsen på bildene våre ved å bruke cv2.resize-metoden. Som jeg indikerte tidligere, må vi vurdere bildets sideforhold når vi bruker denne metoden. Men før vi går for dypt inn i detaljene, la meg gi deg en illustrasjon:
# python resize.py --image squirrel.jpg# importerer de nødvendige pakkene
import argparse
import cv2
# lage objektet til argumentparser og analyser argumentet
apObj = argparse. ArgumentParser ( )
apObj. add_argument ( '-k' , '--bilde' , nødvendig = ekte , hjelp = 'bildebane' )
argumenter = hvem sin ( apObj. parse_args ( ) )
# last inn bildet og vis det på skjermen
bilde = cv2. imread ( argumenter [ 'bilde' ] )
cv2. imshow ( 'Opprinnelig' , bilde )
# For å forhindre at bildet ser skjevt ut, sideforhold
# må vurderes eller deformeres; derfor finner vi ut hva
# forholdet mellom det nye bildet og det gjeldende bildet.
# La oss gjøre bredden på det nye bildet vårt til 160 piksler.
aspekt = 160,0 / bilde. form [ 1 ]
dimensjon = ( 160 , int ( bilde. form [ 0 ] * aspekt ) )
# denne linjen vil vise faktiske endringsoperasjoner
endre størrelse på bildet = cv2. endre størrelse ( bilde , dimensjon , interpolasjon = cv2. INTER_AREA )
cv2. imshow ( 'Endre størrelse på bildebredde' , endre størrelse på bildet )
# Hva om vi ønsket å endre bildets høyde? - bruker
# samme prinsipp, vi kan beregne sideforholdet basert
# på høyde i stedet for bredde. La oss lage den skalerte
# bildes høyde 70 piksler.
aspekt = 70,0 / bilde. form [ 0 ]
dimensjon = ( int ( bilde. form [ 1 ] * aspekt ) , 70 )
# utfør endringen av størrelsen
endre størrelse på bildet = cv2. endre størrelse ( bilde , dimensjon , interpolasjon = cv2. INTER_AREA )
cv2. imshow ( 'Endre størrelse på bildehøyde' , endre størrelse på bildet )
cv2. waitKey ( 0 )
Linje 1-14 , Etter å ha importert pakkene våre og konfigurert argumentparseren vår, vil vi laste og vise bildet vårt.
Linje 20 og 21: Den aktuelle kodingen begynner på disse linjene . Sideforholdet til bildet må tas i betraktning når du endrer størrelsen på det. Forholdet mellom bildets bredde og høyde er kjent som sideforholdet.
Høyde bredde er sideforholdet.
Hvis vi ikke tar høyde/bredde-forholdet i betraktning, vil resultatene av endringen av størrelsen bli forvrengt.
På Linje 20 , er den endrede størrelsesberegningen utført. Vi gir bredden på det nye bildet vårt som 160 piksler i denne kodelinjen. Vi definerer ganske enkelt forholdet vårt (aspectratio) som den nye bredden (160 piksler) delt på den gamle bredden, som vi får tilgang til ved hjelp av bilde, for å beregne forholdet mellom den nye høyden og den gamle høyden. form[1].
De nye dimensjonene til bildet på Linje 21 kan beregnes nå som vi kjenner forholdet vårt. Nok en gang vil det nye bildet ha en bredde på 160 piksler. Etter å ha multiplisert den gamle høyden med forholdet vårt og konvertert resultatet til et heltall, beregnes høyden. Vi kan opprettholde bildets originale sideforhold ved å utføre denne operasjonen.
Linje 24 er der bildet virkelig endres. Bildet vi ønsker å endre størrelse på er det første argumentet, og det andre er dimensjonene vi beregnet for det nye bildet. Interpolasjonsmetoden vår, som er algoritmen for å endre størrelsen på det faktiske bildet, er den siste parameteren.
Til slutt, på Linje 25 , viser vi vårt skalerte bilde.
Vi redefinerer forholdet vårt (aspektratio) på Linje 31 . Høyden på det nye bildet vårt vil være 70 piksler. Vi deler 70 på den opprinnelige høyden for å få det nye høyde-til-originale høydeforholdet.
Deretter etablerer vi det nye bildets dimensjoner. Det nye bildet vil ha en høyde på 70 piksler, noe som allerede er kjent. Vi kan igjen beholde bildets originale sideforhold ved å multiplisere den gamle bredden med forholdet for å produsere den nye bredden.
Bildet blir da faktisk endret på Linje 35 , og den vises på Linje 36.
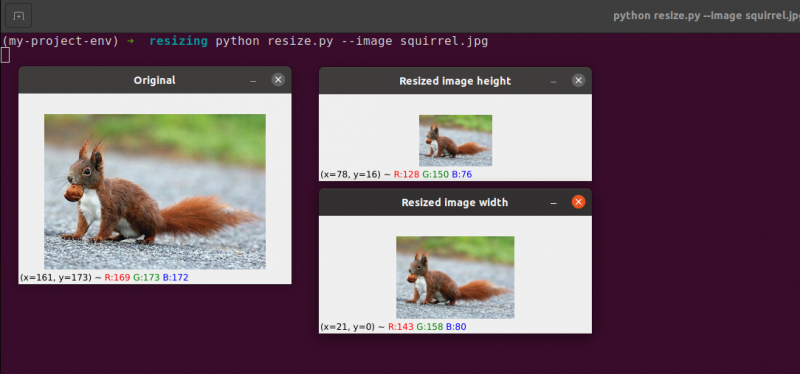
Her kan vi se at vi har redusert bredden og høyden på originalbildet vårt mens vi beholder sideforholdet. Bildet vårt ville virke forvrengt hvis sideforholdet ikke ble opprettholdt.
Konklusjon
I denne bloggen har vi studert de grunnleggende forskjellige bildebehandlingskonseptene. Vi har sett bildeoversettelse ved hjelp av OpenCV-pakken. Vi har sett metodene for å flytte bildet opp, ned, høyre og venstre. Disse metodene er svært nyttige når vi lager et datasett med lignende bilder for å gi som et treningsdatasett, slik at maskinen vil se forskjellige bilder selv om de er like. Denne artikkelen lærte deg også hvordan du roterer et bilde rundt et hvilket som helst punkt i kartesisk rom ved hjelp av en rotasjonsmatrise. Så oppdaget du hvordan OpenCV roterer bilder ved hjelp av denne matrisen og så et par illustrasjoner av spinnende bilder.
De to grunnleggende (men signifikante) bildearitmetiske operasjonene addisjon og subtraksjon ble undersøkt i denne delen. Som du kan se, er det å legge til og subtrahere fundamentale matriser alle billedaritmetiske operasjoner innebærer.
I tillegg brukte vi OpenCV og NumPy for å undersøke særegenhetene ved bildearitmetikk. Disse begrensningene må huskes, ellers risikerer du å få uventede utfall når du utfører aritmetiske operasjoner på bildene dine.
Det er viktig å huske at selv om NumPy utfører en modulusoperasjon og 'omslutter', kutter OpenCV addisjon og subtraksjon verdier utenfor området [0, 255] for å passe innenfor området. Når du utvikler dine egne datasynsapplikasjoner, vil du huske at dette vil hjelpe deg med å unngå å jakte på vanskelige feil.
Bildevending er utvilsomt en av de enklere ideene vi vil utforske i dette kurset. Flipping brukes ofte i maskinlæring for å generere flere treningsdataprøver, noe som resulterer i mer potente og pålitelige bildeklassifiserere.
Vi lærte også hvordan du bruker OpenCV til å endre størrelse på et bilde. Det er avgjørende å vurdere både interpolasjonsmetoden du bruker og sideforholdet til originalbildet ditt når du endrer størrelse på et slik at resultatet ikke ser forvrengt ut.
Til slutt er det viktig å huske at hvis bildekvalitet er et problem, er det alltid best å bytte fra et større til et mindre bilde. I de fleste tilfeller skaper forstørrelse av et bilde artefakter og forringer kvaliteten.